Une startup (et Dieu sait que j’aime les startup) a proposé récemment, via Kickstarter, une clé USB de stockage sécurisée inviolable ! Suite à quoi les experts en sécurité exhortent le marketing à ne plus jamais utiliser le terme inviolable.
Continuer la lectureArchives de catégorie : Concepts
Reconnaissance faciale
Dans la biométrie, la reconnaissance faciale a une place à part car elle est la plus facilement disponible pour tout acteur (étatique ou privé), sans aucune action préalable de l’utilisateur.
Continuer la lectureCryptographie en Python
Python est un langage pratique pour différents usages, y compris la cryptographie. Voici mon aide-mémoire sur le sujet.
Installation
Il faut jouer du pip. Le module le plus important est cryptography !
Voir aussi
- Mon repository GitHub
TOTP
TOTP signifie Time-Based One-Time Password Algorithm. Bien. Les choses sont posées.
Continuer la lectureFake News
Moi qui suit un ardent défenseur de la langue française, je cède ici car l’expression est trop répandue pour ne pas la reprendre. Et surtout le terme fausses informations n’a pas exactement la même signification ni la même connotation complotiste.
Comment ça se passe
Définition
Commençons par tenter de définir ce que c’est. A mon sens, une fake new est une information fausse ou biaisée présentée comme incontestable, dans le but de manipuler les opinions.
Un exemple de manipulation
Création de la source (identité)
Plusieurs techniques sont possibles :
- le piratage pur et simple d’un site d’information ; c’est difficile car il faut s’introduire frauduleusement dans un SI, et risqué juridiquement ;
- la copie visuelle, un peu moins risquée ;
- l’usurpation de noms de domaines (prendre un nom de domaine proche d’un site connu) : on a l’embarras du choix avec les nouveaux TLD ;
- les campagnes de publicité sur des médias reconnus, avec des supports faisant croire à de l’information (genre publi-information, mais avec un but plus clairement malveillant) ;
- le site ad hoc, créé de toute pièces, avec des rédacteurs produisant du contenu régulièrement
Création du faux contenu
Circular reporting
Un mécanisme courant d’apparition et de crédibilisation d’une fausse information est le circular reporting. Le procédé est le suivant :
- Un agent A publie l’information souhaitée, sans source ;
- Un agent B (complice du premier ou trompé par celui-ci) publie l’information (toujours sans source) ;
- L’agent A reprend alors l’information, mais cette fois en citant l’agent B. La boucle est bouclée.
En fonction de la crédibilité ou de la force d’influence de l’agent B, l’information se diffusera plus ou moins rapidement, mais l’agent A pourra désormais donner son information totalement fabriquée avec une source connue (connue ne veut pas dire forcément fiable).
Wikipédia est souvent utilisé comme « agent A », car il est souvent (trop souvent) repris comme source d’information fiable…
Variante : la source cachée
En journalisme, on demande de croiser ses informations en utilisant plusieurs sources différentes.
Or, notamment avec le web, plusieurs médias réputés peuvent reprendre une information dont la source n’est pas connue du lecteur final. Ainsi, ce dernier souhaitant vérifier l’information, ira sur ces différents médias : il aura l’impression d’avoir plusieurs sons de cloche alors qu’en réalité, ces médias ne font que reprendre la même et unique source.
Ca me rappelle un peu ce que je disais à l’époque sur le Web 2.0, avec les flux RSS fleurissant comme des boutons de sébums chez les adolescents, avec pour résultat de vous renvoyer en 50 exemplaires sur 50 sites différents la même information à la virgule près.
Création des faux documents
Tellement facile de nos jours… L’important pour le manipulateur sera d’avoir quelque chose de crédible mais de qualité moyenne, afin d’empêcher toute expertise ou toute recherche de retouche sur une photo, par exemple. Même les vidéos sont facilement contrefaites…
La troncature
Un moyen simple de manipuler un support est de le tronquer pour ne garder qu’une partie en effaçant une partie signifiante du support.
Autre exemple de troncature : cette petite vidéo qui met également en exergue un mécanisme similaire, et très simple à réaliser.
https://embed.koreus.com/00071/201908/lancer-stylo-feutre-pot.mp4
Le doit de réponse oublié
Autre grand travers dans le domaine de fake news : l’absence de visibilité des droits de réponse. En avril 2019, en période de tension entre l’administration américaine et la société Huawei, une nouvelle tombe sur les téléscripteurs : des backdoors auraient été trouvé(e)s sur des équipements réseau Huawei. Or très peu de temps après, Vodafone Italie (pourtant source annoncée de l’information) dément1 en indiquant n’avoir trouvé qu’un accès telnet2. Ok, utiliser ce protocole en soit pourrait être considéré comme une faille, mais il restait pourtant très courant de s’en servir chez les équipementiers réseau.
Faites une recherche Google et vous trouverez cette nouvelle multipliée à l’infini à la date du 30 avril 2019. Ce qui n’apparaît pas clairement est que cette information ne vient que d’une seule source, Bloomberg, qui a pourtant connu des précédents d’informations douteuses34 avec l’affaire SuperMicro5.
Utiliser une information provenant d’une source unique (Bloomberg), ayant eu des problèmes de crédibilité sur le même domaine de la sécurité informatique, pour établir une opinion et des sanctions économiques me semble problématique.
Et ne pas (ou peu ou pas assez) entendre la réponse (crédible ou pas) de Huawei indiquant que ces faits dataient de plusieurs années en arrière (2011 et 2012), que ces problèmes avaient été corrigés et qu’ils n’auraient pas forcément permis un accès à distance par internet2 est tout aussi perturbant.
Diffusion du contenu
Il est impressionnant de voir qu’il n’est pas utile d’écrire beaucoup pour être lu : en positionnant bien son article, avec une accroche bien faite, quelques lignes et une image spectaculaires suffiront.
Un exemple ? Facile !
Le canal privilégié sera les réseaux sociaux, très peu modérés ou contrôlés. Mais l’information ne sera reprise que si elle est issue d’un compte ayant une certaine popularité ou s’étant construit une image de confiance (apparente) suffisante.
Le compte créé pour l’occasion
Les comptes créés spécialement pour diffuser des fake news ont souvent des caractéristiques communes :
- Compte récent (car les comptes douteux finissent heureusement souvent par être supprimés) ;
- L’activité est surtout du relais d’information, et peu de création par lui-même ;
- Beaucoup de mentions de type j’aime, ce qui s’achète facilement ;
- En général peu d’abonnés, ou des abonnés de profil douteux (mais c’est difficile à contrôler).
Le compte original (par compromission)
La compromission d’un compte légitime est aussi possible, via phishing ou grâce aux questions secrètes encore beaucoup trop utilisées. Quoi de mieux que l’original pour diffuser une info bidon ?
La contrepartie est la limitation dans le temps : souvent surveillés, ils finissent par être redonnés à leurs propriétaires.
Double switch
Plus subtil, cette technique consiste à compromettre n’importe quel compte ayant un bon niveau de confiance. Sur Twitter, l’attaquant change ensuite le nom du compte pour celui qu’il veut (Donal__Trump par exemple), ce qui libère l’ancien… qu’il peut ensuite reprendre puisqu’il vient lui-même de le libérer !
Ainsi il dispose d’un compte ayant de nombreux followers, avec une identité qu’il a choisie (le compte original), et un autre compte (sans réputation ni followers) mais avec le nom du compte original ! Pas mal avec une seule compromission, non ?
Autres voies (voix)
Tout s’achète, y compris certains comptes de réseaux sociaux (avec leur public de followers). Et les blogs ou autres forums peuvent aussi encore servir, tout comme les commentaires (issus de robots ou pas).
Propagation
Une fois diffusé, le mécanisme continue : il faut toucher le public le plus large possible, et les réseaux sociaux font merveilles dans le domaine (et encore plus s’ils sont aidés par des robots).
Comment on lutte
Comme on peut, surtout que les mesures préconisées sont souvent contradictoires avec la liberté d’expression ou la neutralité du net.
- https://www.theguardian.com/media/2018/apr/24/eu-to-warn-social-media-firms-over-fake-news-and-data-mining
- https://www.reuters.com/article/us-eu-internet-fakenews/eu-piles-pressure-on-social-media-over-fake-news-idUSKBN1HX15D
- http://europa.eu/rapid/press-release_IP-18-3370_fr.htm
Voir aussi
Formations
Voici une page spéciale avec différentes sources de sensibilisation et d’information :
- https://secnumacademie.gouv.fr/
- https://www.skillset.com/ pour évaluer ses connaissances, en vue d’une certification par exemple.
- https://www.skillset.com/
- https://www.information-security.fr/
- https://www.root-me.org/
- https://podcloud.fr/podcast/comptoir-secu (podcasts)
- https://www.reddit.com/r/netsec
- https://www.zenk-security.com/
Outils
Sites, podcasts, etc.
Sensibilisation pour les enfants
- https://www.securitytuesday.com/wp-content/uploads/2018/10/ISSA.Cahier.SecNum777.pdf
- https://github.com/wavestone-cdt/1-2-3-Cyber
RGPD
- https://atelier-rgpd.cnil.fr/ (MOOC de la CNIL)
Datalake
On peut traduire par tas de données, même s’il n’y a pas l’analogie aquatique. Quoi que tas de données serait mieux approprié pour big data. Parce que lac de données c’est bôf. Bref. Si j’ai bien compris1 dans ce monde merveilleux de la grosse donnée, un datalake est un entrepôt de données, mais dont la grande force est de n’avoir aucun format et de stocker des données quasi-brutes (en les améliorant je pense de quelques métadonnées, à savoir d’où viennent ces données, qui les a produites, quand, etc.).
Avant, on récupérait des données, on les formatait pour les stocker de façon structurée quelque part, ça s’appelait un datawarehouse. Et après on chargeait ce dont on a besoin (Extract – Transform – Load).
Maintenant c’est mieux : on les stocke en tas de merde données, sans modification ni altération donc sans perte d’info (ce qui est bien, faut reconnaître), puis on les charge, et seulement à la fin on en fait quelque chose, en leur appliquant des filtres, des modèles, des structures, mais a posteriori2. Donc on passe en Extract – Load – Transform. Comme les puissances de calcul et de stockage peuvent maintenant le permettre (c’est-à-dire stocker des données en tas de merde sans pour autant que ça soit trop le bordel bazar), ben on le fait.
Et on vient de révolutionner pour la 256e fois l’informatique.
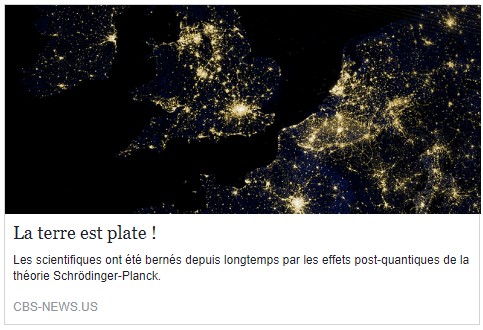
Fonctions de hachage
Les fonctions de hachage sont des fonctions particulières très utilisées dans le cadre de la sécurité informatique, notamment dans le domaine de la cryptographie et des certificats numériques. Elles permettent d’obtenir une empreinte, également appelée condensat (« hash »), à partir d’un message ou de tout document numérique.
Il existe un nombre assez restreint de fonctions de hachage, car elles sont assez complexes à mettre au point et reposent sur des mécanismes mathématiques complexes.
Principales caractéristiques
En pratique
Une fonction de hachage est une fonction mathématique particulière permettant de calculer rapidement l’empreinte d’une donnée informatique. Une fonction de hachage doit présenter les caractéristiques suivantes :
- La taille du condensat (« hash ») est fixe (pour un algorithme donné) ;
- Elle ne fonctionne que dans un sens (c’est-à-dire qu’il n’existe pas de fonction inverse) ;
- Pour une entrée donnée, on doit toujours obtenir le même résultat (empreinte) ;
- Toute modification même très légère en entrée produit un résultat très différent ;
- Elle est rapide à calculer.
L’intérêt de ce condensat est d’avoir une sorte de signature d’un document :
- L’irréversibilité permet de ne pas pouvoir retrouver le document original à partir du condensat (il est même très difficile de construire un document quelconque à partir d’une empreinte donnée) ;
- Si deux hashs sont différents, alors les documents initiaux sont forcément différents.
Intérêt et usage des fonctions de hash
L’intérêt principal est de permettre d’identifier la donnée de façon presque sûre sans pour autant transmettre la donnée : il est mathématiquement très difficile (voire impossible) de retrouver la donnée initiale à partir de son empreinte.
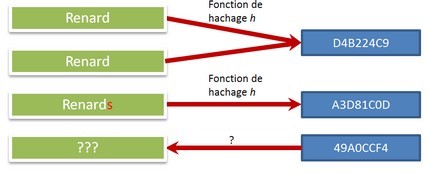
Ces fonctions peuvent avoir plusieurs usages, plus ou moins critiques. Cela peut aller du simple contrôle technique pour s’assurer qu’un message a été correctement transmis (ou n’a pas été modifié), jusqu’à la signature électronique.
Pour le mot de passe
On s’en sert également pour chiffrer les mots de passe dans beaucoup de systèmes. Puisque ces fonctions sont rapides, on peut facilement calculer l’empreinte d’un mot de passe ; c’est alors lui qui est stocké dans le système, et non le mot de passe en clair. Comme il est difficile de retrouver la donnée initiale à partir d’une empreinte, la protection ainsi obtenue est bonne (plus ou moins en fonction de l’algorithme utilisé et de sa mise-en-oeuvre).
Lorsqu’un utilisateur veut se connecter à un système, il entre son mot de passe. On calcule ensuite son empreinte : si c’est la même que celle stockée dans le système, l’accès est alors autorisé.
Pour vérifier l’intégrité d’une donnée
Si on souhaite vérifier qu’une donnée (un fichier informatique) est intègre, c’est-à-dire non modifiée, on communique le fichier au destinataire et ce dernier recalcule lui-même son empreinte : celle-ci doit correspondre à une empreinte de référence.
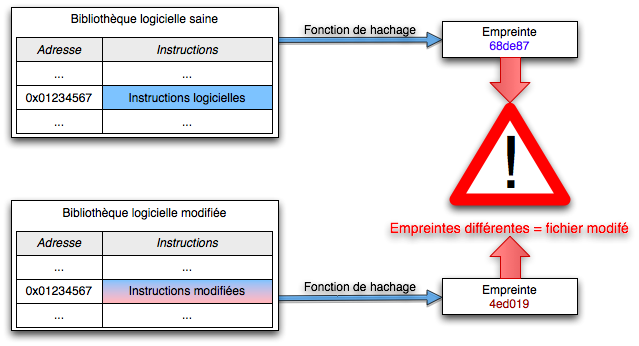
Toute la subtilité vient ensuite de la façon dont on connaît cette empreinte de référence : quand on télécharge un fichier, cela peut être une somme de contrôle ; pour un certificat, c’est une des données du certificat.
Pourquoi presque sûre ?
L’empreinte est généralement de petite taille et de longueur fixe. Même si cela représente beaucoup de possibilités, ce nombre est fini, alors que le nombre d’entrées possibles est, lui, infini.
Statistiquement, il est donc très peu probable que deux données différentes en entrée produisent la même empreinte, mais c’est possible : la difficulté augmente avec la longueur choisie pour l’empreinte. Pour SHA-1, c’est 160 bits. pour SHA-256 c’est… 256 bits !
Trouver deux données différentes ayant un même hash est appelé collision. La probabilité d’une collision dépend principalement de la longueur du hash, mais aussi (un peu) de la façon dont il est calculé (notamment la rapidité de son calcul).
Les propriétés et les attaques
Propriétés formelles attendues d’une fonction de hachage
Reprenons un peu le chemin de la théorie. Selon McAfee Labs (Intel)1, une bonne fonction de hachage doit avoir les propriétés suivantes :
- Résistance à la préimage : Pour une valeur de hachage donnée, il doit être difficile de trouver un fichier ou message pour lequel la fonction de hachage produirait une valeur identique.
- Résistance à la seconde préimage : Pour un fichier ou message donné, il doit être difficile de trouver un second fichier ou message tel que la fonction de hachage produirait la même valeur pour les deux fichiers ou messages.
- Résistance à la collision : Il doit être difficile de trouver deux fichiers ou messages distincts pour lesquels la fonction de hachage produirait la même valeur de hachage.
Dis comme ça, il n’est pas évident de voir la différence (je parle pour moi). Mais l’enjeu de cette formalisation est de voir quels sont les types d’attaques possibles : chaque propriété est plus ou moins forte, pour un type de hash donné. Et plus la propriété est faible, plus une attaque est probable.
Les différents type d’attaques
Attaques par collision
Il existe deux types principaux d’attaques de collisions :
- l’attaque de collisions classique : cette attaque consiste à trouver deux messages m1 et m2 différents, tels que hachage (m1) = hachage (m2) ;
- l’attaque de collisions avec préfixes choisis : étant donné deux préfixes différents P1 et P2, cette attaque consiste à trouver deux suffixes S1 et S2 tels que hachage (P1 ∥ S1) = hachage ( P2 ∥ S2) (où ∥ est l’opération de concaténation).
Source : Wikipédia
xxx
Qu’est-ce qui se passe avec SHA-1
Il se passe que la robustesse de SHA-1 est remise en question face au développement de la puissance de calcul disponible. Or SHA-1 est très utilisé, notamment pour les certificats ; or si on peut attaquer SHA-1, on peut alors attaquer des certificats et créer des faux !
Pour plus d’informations : voir SHA-1.
Ce qu’affichent les navigateurs
La signalétique est généralement univoque. Chrome affiche du vert quand c’est sûr, du gris pour un avis neutre, et du rouge quand le niveau de sécurité est trop faible.
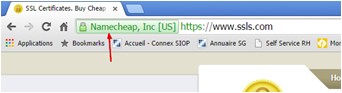
Malheureusement tout le monde applique un peu les règles qu’il veut, comme il le sent, ce qui aboutit à des incohérences pour un utilisateur multi-navigateurs (comme moi). Google a tendance à avoir l’attitude la plus restrictive, ce qui n’est pas forcément condamnable, sauf que cela n’a pas toujours de l’intérêt, comme par exemple sur des sites de peu d’influence ou de peu d’importance.
De plus, Google change ses règle si rapidement qu’un utilisateur peut être perdu en voyant un site « dégradé » (en termes de sécurité) d’une version à l’autre du navigateur.
Exemple d’utilisation
Sous Linux, si vous ne disposez pas des commandes shaxxxsum :
openssl dgst -sha1 filename
Cloud (pannes)
Facile mais instructif : quelques pannes notables sur les grands fournisseurs de Cloud (hors failles de sécurité)
Amazon Web Services
- mars 2017 : une panne sur S3 (Virginie) avec plusieurs services affectés 1 . La cause est officiellement… une erreur de frappe2 !
- mars 2018 : problèmes réseau (Virgine) 3 , ayant pour origine une panne électrique, avec de forts impacts 4 .
Microsoft Azure
- xx
Microsoft Office
- xx
IBM
- nn
Google Cloud Plateform
- 17 juillet 2018 : panne sur le StackDriver (données de performance et diagnostic), AppEngine et Cloud Networking touchés5, perturbant notamment Snapchat, Discord, Spotify ou même Pokemon GO 😉
Source
Chiffrement (outils)
Calcul multipartite sécurisé
Le calcul multipartite sécurisé est un problème où chacune des parties veut effectuer une opération commune sur des données qui doivent rester privées (aucun des participants ne connaît les données de l’autres) et exactes (non compromises). Il faut aussi qu’un tiers extérieur (attaquant) ne puisse pas accéder lui non plus aux données privées, ni les falsifier.
Participons
Une des applications pratiques est celle du classement de fortunes de millionnaires, sans rendre publics les montants de ces fortunes. Pour deux millionnaires cela revient à savoir lequel est le plus riche sans connaître la fortune de l’autre. La réduction à deux participants n’est pas anodine car elle permet, dans certaines méthodes, une généralisation à plusieurs participants.
Un cas d’usage similaire est celui d’enchères anonymes, ou du comptage des voix dans une élection : il faut savoir qui a gagné sans connaître le vote de chacun (note : ceci est réalisable dans le cas du vote papier, et beaucoup plus difficile dans un vote électronique).
Mathématiquement, cela peut aussi être la création d’un entier aléatoire N que deux parties ne peuvent reconstituer que conjointement. Si N = pq avec p et q étant des facteurs de N, alors aucune des deux parties ne connaît (p,q). Les deux parties peuvent ainsi effectuer des calculs sur des fonctions polynomiales sans révéler les valeurs utilisées en entrée, qui restent donc secrètes, ce qui a des applications en cryptographie.
Les Yao Garbled Circuits sont une solution possible permettant le calcul multipartite sécurisé.
Garbled circuits, secure multi-party computation
Références externes
- http://u.cs.biu.ac.il/~lindell/research-statements/tutorial-secure-computation.ppt
- https://www.cs.purdue.edu/homes/ninghui/courses/555_Spring12/handouts/555_Spring12_topic24.ppt
- https://eprint.iacr.org/2009/314.pdf
- https://cyber.ee/uploads/2013/04/T-4-15-Yao-Garbled-Circuits-in-Secret-Sharing-based-Secure-Multi-party-Computation.pdf
- https://arxiv.org/pdf/1410.1389.pdf
- http://www.lix.polytechnique.fr/~catuscia/teaching/cg597/01Fall/lecture_notes/SMC.ppt
- http://www.wisdom.weizmann.ac.il/~gilc/talks/mpc.ppsx
- http://www.cs.tau.ac.il/~fiat/crypt04/Lecture_12.ppt
- https://www.sciencedirect.com/science/article/pii/S0166218X05002428
Autres informations
Google Releases Encrypted Multi-Party Computation Tool(June 19, 2019)
Google has rolled out its open-source Private Join and Compute (PJC) secure multi-party computation tool. PJC can be used in studies that require data sets containing sensitive information from two separate parties. PJC will allow two sets of data to be used in computations without exposing the data each set contains. The data are encrypted during the computation; all parties can see the result.
Read more in:
– security.googleblog.com: Helping organizations do more without collecting more data
– www.wired.com: Google Turns to Retro Cryptography to Keep Data Sets Private
– www.theregister.co.uk: Google takes the PIS out of advertising: New algo securely analyzes shared encrypted data sets without leaking contents
– www.zdnet.com: Google open sources Private Join and Compute, a tool for sharing confidential data sets
Lean six sigma
Comme tout bon français qui se respecte, j’adore râler. Mais à l’inverse des complotistes, j’aime me documenter et argumenter mes haines ordinaires.
Sources d’information
Big brother
Le thème n’est pas nouveau, mais entre les progrès techniques (technologiques), l’avènement du big data et autres joyeusetés, nous ne sommes pas près d’avoir la paix quant aux informations personnelles circulant en dehors de notre contrôle. En outre, les petits ruisseaux font les grandes rivières : avec la prolifération des données que nous produisons, il devient possible par inférence ou corrélation de déterminer une quantité énorme d’informations nouvelles et souvent inattendues.
Soyons anonymes
Et bien cela va être de plus en plus difficile. Dernier exemple que je viens de trouver : des chercheurs ont trouvé une technique permettant de déterminer la position d’un téléphone portable à partir d’informations a priori anonymes.
Conservons notre vie privée
Ça va devenir de plus en plus difficile (je me répète). Les applications les plus utilisées sont et seront la cible des autorités et des officines secrètes qui chercheront à savoir tout sur vous, pour des raisons commerciales, idéologiques, de sécurité1, etc.
Le cas Facebook
Voir aussi
Liens externes
- http://www.lepoint.fr/chroniqueurs-du-point/guerric-poncet/vie-privee-protegez-vous-des-surveillants-08-09-2015-1962786_506
- http://wefightcensorship.org/fr/online-survival-kithtml.html
- https://ssd.eff.org/
- http://www.laquadrature.net/fr/Vie_privee et http://www.controle-tes-donnees.net/
- https://arxiv.org/abs/1802.01468
- https://www.theregister.co.uk/2018/02/07/boffins_crack_location_tracking_even_if_youve_turned_off_the_gps/
- https://www.01net.com/actualites/chine-une-faille-de-securite-donne-un-apercu-d-un-systeme-de-surveillance-digne-de-big-brother-1686365.html
Liens internes
- Appareils mobiles
- Rêvons un peu…
Bastion
Le bastionnage (pas sûr que le terme existe) consiste à créer un bastion pour accéder à vos ressources (informatiques). On les utiliser sur des ressources sensibles par leur positionnement (ex : production), par leur nature (ex : outil de gestion de droits), leur contenu, etc.
Ainsi, personne ne peut (en théorie) accéder à vos ressources sans montrer patte blanche et sans passer par ce bastion, qui peut surveiller et mettre en historique les actions effectuées, filtrer les éléments indésirables, gérer des droits d’accès différenciés, etc.
Continuer la lectureAuthentification par assertion
La technique de l’authentification basée sur des assertions (ou « claims-based identity ») est un concept extrêmement intéressant sur lequel est basé SAML. Un des principaux attraits de cette technologie est de permettre la fédération d’identité.
Principes
Très concrètement, un système de jetons de sécurité (STS an anglais, pour Security Token Service) permet la gestion de l’identité d’un utilisateur (et de ses droits). Un des grands intérêts de ce concept est de permettre des relations de confiance entre STS, ce qui permet à différents systèmes d’authentification de propager une identité, et donc de créer des fédérations d’identité.
Les briques
Il y a 3 composants dans un tel système :
- Le fournisseur d’identité, qui est un STS ;
- Un fédérateur d’identité, qui est aussi un STS ;
- Une bibliothèque permettant d’utiliser les jetons, au niveau de l’application cible.
Chez Microsoft
Microsoft permet la mise en œuvre d’un tel mécanisme soit dans son propre système d’information, soit dans le cloud.
Attention : L’Active Directory d’Azure est différent de l’Active Directory classique, car ses fonctionnalités sont limitées à celles utiles pour la gestion d’identité. Il n’y a par exemple rien sur la gestion des politiques des postes Windows rattachés, ce qui est une fonctionnalité très importante dans Active Directory.
Dans le cas où on part d’un fournisseur d’identité interne (ex : Windows Server Active Directory with ADFS) pour se connecter à une application externe via Azure Active Directory, on a besoin d’une synchronisation entre le fournisseur d’identité et le fédérateur. ==> A creuser. A contrario, on peut utiliser Azure AD Access Control en tant que fédérateur d’identité, où la synchronisation est inutile, ce qui est beaucoup plus propre.
Voir aussi
Auth0
Atombombing
L’atombombing est une technique permettant l’injection de code de façon très furtive.
Antivirus
Un logiciel antivirus combat les virus. Après ça on est bien avancé, non ? Le nom antivirus est un nom générique donné aux programmes de sécurité, dont le but est de détecter et supprimer les virus (ce qui est un abus de langage pour désigner les programmes malveillants).
La question mérite d’être posée : a-t-on besoin d’un anti-virus ? Sur un serveur web ? Sur un poste client ? Sur un smartphone ?
Continuer la lectureAnonymisation
Les données personnelles sont précieuses, au moins encore quelques temps (je ne sais pas si cela va durer). En tout cas, plusieurs lois et règlements imposent à tous ceux qui en traitent de les protéger.
Pour cela, une techniques possible est l’anonymisation des données, qui consiste(rait) à faire en sorte que les données utilisées ne permettent pas de retrouver l’individu qui en est la source (volontaire ou pas).
Critères d’évaluation
En général, on en retient 3 :
- L’individualisation, qui consiste à voir si on peut isoler ou pas les données concernant une seule et même personne ;
- La corrélation, qui est la faculté de rapprocher des données a priori distinctes d’un seul et même individu (ou d’un groupe d’individus) ;
- L’inférence, qui est la possibilité de déduire d’un ensemble de données des caractéristiques d’un individu. Par exemple on arrive à savoir si c’est un homme ou une femme sans avoir aucune indication du sexe dans les données qu’on possède.
Si un seul de ces critères n’est pas respecté, l’anonymisation n’est que partielle. Autant dire qu’une véritable anonymisation est, en pratique, quasiment impossible à obtenir, surtout à l’heure du big data. D’autant que si elle était effective, cela poserait de gros soucis pour réaliser des tests, car l’anonymisation risque de rompre des contraintes d’intégrité ou des contraintes fonctionnelles dans les jeux de données concernés.
Un exemple : Yoodle, un broker de données (beurk), qui annonce suivre les recommandations de son régulateur, fournit à ses clients des données dont le niveau d’anonymisation est très faible (trop faible), car s’il anonymise unitairement les noms, prénoms, numéros de téléphone ou de sécurité sociale, certains libellés de transactions, etc., il suffit souvent de remettre dans un contexte, de croiser les donner avec d’autres infos pour ré-identifier les personnes. Au mieux on peut dire que les données sont pseudonymisées (et non anonymiser).
Voir : https://www.vice.com/en_us/article/jged4x/envestnet-yodlee-credit-card-bank-data-not-anonymous
Méthodes d’anonymisation
Il y en a plusieurs types, plus ou moins faciles à mettre en oeuvre, plus ou moins efficace, et plus ou moins utilisables ensuite (dans les tests). Voici une synthèse de ce qui a été publié par l’AFCDP :
Méthodes radicales
- La suppression de la donnée : si elle vraiment sensible, on la vire (un point c’est tout) ;
- La génération de données (données fictives), la plus efficace mais assez difficile à mettre en oeuvre ;
- Le hachage (de préférence avec salage), mais cela pose problème dans leur traitement ; cela ne peut s’appliquer qu’à des données transférées pour lecture et non pour traitement.
Méthodes de lutte contre l’inférence
- La variance (vieillissement, modification dans une certaine plage, etc.) ;
- Le mélange, où certaines données d’un enregistrement #1 sont mises dans un enregistrement #2, et ainsi de suite ;
- La concaténation où on fabrique une donnée à partir d’autres (à préciser…) ;
Dans tous les cas, on risque d’amener un incohérence fonctionnelle dans le jeu de données (par exemple des parents peuvent devenir trop jeunes par rapport à leurs enfants, dans le cas de modification des dates de naissance).
Méthodes partielles
Souvent inadaptées à une anonymisation réelle, elles peuvent néanmoins contribuer à une certaine sécurité, dans certaines conditions.
- Le masquage (comme le numéro de la carte de crédit) ou l’appauvrissement pour rendre les données moins précises ;
- Le chiffrement qui n’est qu’une anonymisation faible ;
- L’obfuscation qui n’a qu’une efficacité faible.
Pseudonymisation
La grande différence entre l’anonymisation et la pseudonymisation est que cette dernière est en principe réversible.
Voir aussi
Sources
- http://www.zdnet.fr/actualites/rgpd-comment-choisir-entre-anonymisation-et-pseudonymisation-des-donnees-39867798.htm
- http://www.zdnet.fr/actualites/comment-mettre-son-data-lake-au-service-de-la-conformite-au-rgpd-39868036.htm
- https://www.afcdp.net/IMG/pdf/AFCDP_Referentiel_Anonymisation_080522-3.pdf
Article lié
Sur l’anonymisation
Big data
Les grosses données sont des données nombreuses et volumineuses. Concept fumeux et marketing comme toujours, il n’en est pas moins vrai que l’augmentation des performances de stockage et de calcul posent de nouveaux problèmes de sécurité.
Technologie
D’où ça vient ?
Nous produisons de l’information depuis longtemps, bien avant le temps de l’informatique, mais la mémorisation (stockage) des informations (données) était limitée, tout comme leur analyse : il a fallu longtemps se contenter d’un support papier et de son cerveau !
Avec l’avènement de l’informatique, tout change : on peut à la fois stocker l’information et déléguer son traitement à une machine. Or plus on avance dans le temps, plus les capacités de stockage et d’analyse progressent, au point que certains usages qui nous paraissaient impossibles aux premiers temps de l’informatique sont maintenant à la porté d’un très grand nombre de personnes et d’entreprises.
Alors qu’autrefois, il fallait du matériel spécialisé, l’analyse de données est désormais possible avec du matériel standard. Ce qui relevait des capacités d’une organisation spécialisée est désormais possible à presque tout le monde, y compris des particuliers. Devenant grand public, le marketing inventa comme toujours un concept pour matérialiser cette évolution : le big data. L’analyse rapide de données en masse
Définition informatique formelle
Il n’y en a pas. Il y a plutôt certains critères qui font penser qu’on est dans une implémentation de big data :
- Beaucoup de données, généralement non structurée ;
- On utilise hadoop !
- L’architecture est distribuée et parallélisée ;
- On n’arrive pas à traiter les données avec une base de données classique ;
- Règle des 3V : Volume, Variété, Vélocité des données et de leur analyse.
En résumé : en cherchant bien, n’importe quoi peut être big data.
Domaines
Pour n’en citer que quelques uns où l’analyse rapide de données en masse le big data est utilisé :
- Ciblage publicitaire, suivi des consommateurs
- Analyse comportementale
- Lutte contre la fraude
- Recherche (santé par exemple)
- Détection et prévention des pannes de composants ou de systèmes failures
Les technologies en elles-mêmes
MapReduce
MapReduce est une technologie initiée par Google pour le traitement des données en masse. Les deux principales étapes sont :
- Map : On transforme la donnée brute en format exploitable (genre clé-valeur), et on les prépare au traitement.
- Reduce : On les traite effectivement, de façon statistique.
Hadoop
Hadoop est l’implémentation open source de MapReduce couplé à un système de fichiers distribué, HDFS. HDFS permet notamment de répliquer les données sur plusieurs noeuds pour éviter la perte de données, et la mise-à-jour est également interdite : elle s’effectue par la création d’un nouveau fichier.
D’autres technologies sont adossées à l’écosystème Hadoop :
- Des bases de données spécialisées sont également employées, comme Hbase ou Cassandra, opérant un système de fichier HDFS (ou compatible) ;
- Les requêtes sont générées en langage HiveQL ou Pig Latin ;
- L’import/export de données vers des bases classiques se fait via Sqoop (Sql-to-hadoop) ;
- Des composants de haut ou bas niveau, comme pour le machine learning (Mahout) ou l’intégration de logs (Flume).
Hive
Hive n’est ni plus ni moins qu’une infrastructure d’entrepôt de données (comme on disait dans le temps), mais basé sur les outils de type big data, comme HiveQL, HDFS, HBase, etc. Il est interopérable avec de nombreux outils de BI (Business Intelligence).
Autres technologies liées
- Massively Parallel Processing (MPP), basé sur des appliances, permettant des requêtes SQL distribuées ;
- NoSQL, bases non structurées privilégiant la disponibilité à la consistance (au sens SGBD), stockant sous les formes de clés/valeurs, documents, graphes, etc.
- CAP Theorem : ?
- NewSQL : ?
La liste ne saurait être limitative, surtout que l’hybridation des architectures est souvent pratiquée dans les entreprises.
En ai-je besoin ?
La plupart du temps : non. Mais ça fait chouette sur sa carte de visite (au niveau personnel ou entreprise). Mais s’il fallait réfléchir avant de mettre en oeuvre une technologie informatique, ça se saurait. S’il y a de nombreux cas d’usage où les technologies big data se justifient, de trop nombreuses organisations ne le font que pour être à la mode. Une des conséquences de cet engouement irréfléchi est la pénurie de statisticiens, appelés data scientists dans le domaine du big data, capables de tirer parti des données.
Comment rester anonyme ?
Big data et respect de la vie privée sont deux notions contradictoires : dans ce monde de données abondantes et déferlantes, il devient bien difficile de rester anonyme, pour deux grandes raisons :
- D’abord parce que nous produisons de la donnée à ne plus savoir qu’en faire, en laissant partout un infinité de traces de nos activités (informatiques, ou non-informatiques mais mesurées ou reliées à des outils informatiques) ;
- Parallèlement à cette production, les moyens de traitement sont désormais capables d’effectuer des rapprochements ou des corrélations dont on était incapable il y a peu.
Un exemple (théorique) de désanonymisation par corrélation
Cet exemple a été donné par une juriste de ma société, et il est très parlant. Imaginons qu’on dispose d’une vue partielle de l’ensemble des logs d’activité des bornes téléphoniques. Par partiel, j’entends qu’on dispose de données sur l’ensemble des bornes, sur une période suffisamment grande, mais anonymes a priori : on ne disposerait que de l’identité (l’emplacement) de la borne, la date précise (au moins à la minute) et l’identifiant des téléphones (genre IMEI). Un exemple simple de ligne pourrait être :
numéro de ligne ; identité/localisation borne ; date et heure ; IMEI
A prori rien de personnel. Ou plutôt rien que des données anonymes, car les identifiants techniques comme l’adresse IP, l’adresse MAC ou l’IMEI sont indirectement personnelles : les opérateurs disposent d’une base faisant le lien entre ces identifiants techniques et leurs clients. De ces informations brutes, on ne peut tirer aucune information personnelle. On suppose aussi qu’on ne dispose pas d’une base faisant un lien entre IMEI et les clients, bien sûr.
En premier lieu, on isolera toutes les données d’un IMEI, en supposant qu’il n’y ait qu’un seul utilisateur principal. On tracera vite une cartographie de la géographie de ses déplacements, et on trouvera vite l’adresse de son travail (les lieux où le téléphone se trouve durant les heures de travail) et celle de son domicile (aux autres heures), de façon statistique. Puis, à partir d’une annuaire classique, on cherchera sur les adresses proches de la localisation du domicile un premier ensemble de candidats potentiels.
Ensuite, on identifiera les entreprises présentes sur le lieu de travail. Là aussi des données facilement accessibles. Pour continuer, on cherchera sur les réseaux sociaux toutes les personnes de notre première liste de candidats travaillant pour une des sociétés de notre 2e liste, si possible en affinant par localisation.
Dans mon cas, je travaille sur un site de 5000 personnes et j’habite Paris ; or je n’ai jamais rencontré de collègue ou très peu près de mon domicile. Dans le pire des cas, une petite dizaine de personnes doivent à la fois travailler à proximité du lieu de travail et du domiciles identifiés par les logs bruts.
En continuant une corrélation un peu plus ciblée, on finit par donner une identité quasi-certaines à l’IMEI a priori anonyme. Et en repartant sur les logs, on finit par tracer une grande partie des activités de la personne. Merci à nos smartphones !
Après y avoir pensé en théorie, voici l’application pratique, rapportée par le New York Times !
Inférence
On peut déterminer des caractéristiques d’une personne sans rien lui demander. Il faut souvent un niveau un peu plus élevé d’informations, mais à peine. Imaginons qu’en plus des données précédentes, on dispose du niveau de signal (assez précis, quand même). Dans les toilettes hommes, je mets une borne wifi. Une autre est placée dans les toilettes femmes. Les téléphones vont interroger les bornes lorsqu’ils sont à proximité. On en déduit facilement le sexe du propriétaire d’un téléphone quand il se rend aux toilettes : le meilleur signal sera du côté où se trouve la personne !
On a donc ainsi déterminé le sexe d’une personne sans rien lui demander : c’est un mécanisme d’inférence.
Ok mais ça marche pas à tous les coups
Oui. Mais rapportons ça à l’échelle du temps, du volume exponentiel de données et de signaux que nous produisons.
Cherchons bien
Comme prévu, et comme prouvé, l’anonymisation est un art délicat !