Remettons tout cela en musique et replaçons les choses de façon compréhensible.
Continuer la lectureArchives de catégorie : Principes généraux
Fact-checking
Où vérifier les informations qui circulent à droite et à gauche ? La tâche est si complexe que même des journalistes s’y perdent et se font avoir. Voici, à titre informatif, quelques sites de vérification d’information. Quoi qu’il en soit, quoi qu’il arrive, multipliez les sources et allez voir les avis contraires pour ne pas vous enfermer dans un schéma (ni dans les statistiques des algorithmes qui vous proposeront toujours la même tendance). Je les ai tous vérifiés au 11/09/2025 mais signalez moi toute erreur ou changement d’URL !
Continuer la lectureDérogation ou acceptation du risque ?
Dans le cadre des normes ISO 27001 et ISO 27005, les notions de dérogation et acceptation du risque sont liées mais distinctes. Il est bon de se rappeler des bases et des définitions exactes et leur application en sécurité des systèmes d’information. Un vocabulaire précis permet souvent un raisonnement précis.
En résumé, l’acceptation du risque est une notion issue de l’analyse de risque et relève donc de la gestion du risque. Elle peut être temporaire ou permanente. La dérogation est issue d’une non conformité (en général à la PSSI) et ne peut être que temporaire.
Continuer la lectureVLAN
Un VLAN (Virtual Local Area Network) est un réseau local virtuel qui permet de regrouper un ensemble d’équipements au sein d’un même réseau local logique, même s’ils sont physiquement dispersés dans un réseau plus large. Un VLAN divise un réseau physique en plusieurs réseaux virtuels distincts, chacun avec ses propres segments, créant ainsi une séparation entre les groupes d’équipements.
Continuer la lectureDue care, due diligence
J’ai toujours eu du mal avec ces deux notions. D’origine juridique, elles s’appliquent également en sécurité informatique. En sécurité informatique, les concepts de « due care » et « due diligence » peuvent être appliqués de la manière suivante :
Continuer la lectureCI/CD
Continuous ceci, continuous cela… A quoi ça rime ? Ou plutôt à quoi ça rythme ? Car l’intégration continue et le déploiement continu sont une question de rythme, oserai-je dire.
Continuer la lectureBonnes pratiques : les bases
Un article fourni (pour une fois) de ZDNet reprend un ensemble de bonnes pratiques, pour un usage personnel. Les outils proposés vont évoluer dans le temps (de nouveaux non cités vont apparaître, d’autres vont disparaître), mais les bases devraient rester stables, et cet article est donc instructif à ce titre.
Continuer la lectureLogique et mathématique
Un ordinateur, c’est bien beau, mais c’est rien qu’une machine. Une machine avec des performances extraordinaires, dans son domaine, mais une machine quoi qu’on en dise : une machine répondant aux lois mathématiques (et donc à la logique mathématique).
Continuer la lectureC’est sûr, l’open source ?
Puisqu’on vous dit que oui car tout le monde peut regarder dans le code que tout va bien et que de toutes façons y a pas de méchant dans les développeurs qui font de l’open source c’est bien connu.
Continuer la lectureZero trust
Ne faites confiance à personne ! Je l’ai souvent entendu dans la vie, et c’est la première chose qu’on apprend quand on fait de la sécurité informatique. Le concept (marketing ou pas) de Zero Trust a vite émergé depuis que la SSI est devenue industrielle, mais c’est quoi ?
Continuer la lectureFake News
Moi qui suit un ardent défenseur de la langue française, je cède ici car l’expression est trop répandue pour ne pas la reprendre. Et surtout le terme fausses informations n’a pas exactement la même signification ni la même connotation complotiste.
Comment ça se passe
Définition
Commençons par tenter de définir ce que c’est. A mon sens, une fake new est une information fausse ou biaisée présentée comme incontestable, dans le but de manipuler les opinions.
Un exemple de manipulation
Création de la source (identité)
Plusieurs techniques sont possibles :
- le piratage pur et simple d’un site d’information ; c’est difficile car il faut s’introduire frauduleusement dans un SI, et risqué juridiquement ;
- la copie visuelle, un peu moins risquée ;
- l’usurpation de noms de domaines (prendre un nom de domaine proche d’un site connu) : on a l’embarras du choix avec les nouveaux TLD ;
- les campagnes de publicité sur des médias reconnus, avec des supports faisant croire à de l’information (genre publi-information, mais avec un but plus clairement malveillant) ;
- le site ad hoc, créé de toute pièces, avec des rédacteurs produisant du contenu régulièrement
Création du faux contenu
Circular reporting
Un mécanisme courant d’apparition et de crédibilisation d’une fausse information est le circular reporting. Le procédé est le suivant :
- Un agent A publie l’information souhaitée, sans source ;
- Un agent B (complice du premier ou trompé par celui-ci) publie l’information (toujours sans source) ;
- L’agent A reprend alors l’information, mais cette fois en citant l’agent B. La boucle est bouclée.
En fonction de la crédibilité ou de la force d’influence de l’agent B, l’information se diffusera plus ou moins rapidement, mais l’agent A pourra désormais donner son information totalement fabriquée avec une source connue (connue ne veut pas dire forcément fiable).
Wikipédia est souvent utilisé comme « agent A », car il est souvent (trop souvent) repris comme source d’information fiable…
Variante : la source cachée
En journalisme, on demande de croiser ses informations en utilisant plusieurs sources différentes.
Or, notamment avec le web, plusieurs médias réputés peuvent reprendre une information dont la source n’est pas connue du lecteur final. Ainsi, ce dernier souhaitant vérifier l’information, ira sur ces différents médias : il aura l’impression d’avoir plusieurs sons de cloche alors qu’en réalité, ces médias ne font que reprendre la même et unique source.
Ca me rappelle un peu ce que je disais à l’époque sur le Web 2.0, avec les flux RSS fleurissant comme des boutons de sébums chez les adolescents, avec pour résultat de vous renvoyer en 50 exemplaires sur 50 sites différents la même information à la virgule près.
Création des faux documents
Tellement facile de nos jours… L’important pour le manipulateur sera d’avoir quelque chose de crédible mais de qualité moyenne, afin d’empêcher toute expertise ou toute recherche de retouche sur une photo, par exemple. Même les vidéos sont facilement contrefaites…
La troncature
Un moyen simple de manipuler un support est de le tronquer pour ne garder qu’une partie en effaçant une partie signifiante du support.
Autre exemple de troncature : cette petite vidéo qui met également en exergue un mécanisme similaire, et très simple à réaliser.
https://embed.koreus.com/00071/201908/lancer-stylo-feutre-pot.mp4
Le doit de réponse oublié
Autre grand travers dans le domaine de fake news : l’absence de visibilité des droits de réponse. En avril 2019, en période de tension entre l’administration américaine et la société Huawei, une nouvelle tombe sur les téléscripteurs : des backdoors auraient été trouvé(e)s sur des équipements réseau Huawei. Or très peu de temps après, Vodafone Italie (pourtant source annoncée de l’information) dément1 en indiquant n’avoir trouvé qu’un accès telnet2. Ok, utiliser ce protocole en soit pourrait être considéré comme une faille, mais il restait pourtant très courant de s’en servir chez les équipementiers réseau.
Faites une recherche Google et vous trouverez cette nouvelle multipliée à l’infini à la date du 30 avril 2019. Ce qui n’apparaît pas clairement est que cette information ne vient que d’une seule source, Bloomberg, qui a pourtant connu des précédents d’informations douteuses34 avec l’affaire SuperMicro5.
Utiliser une information provenant d’une source unique (Bloomberg), ayant eu des problèmes de crédibilité sur le même domaine de la sécurité informatique, pour établir une opinion et des sanctions économiques me semble problématique.
Et ne pas (ou peu ou pas assez) entendre la réponse (crédible ou pas) de Huawei indiquant que ces faits dataient de plusieurs années en arrière (2011 et 2012), que ces problèmes avaient été corrigés et qu’ils n’auraient pas forcément permis un accès à distance par internet2 est tout aussi perturbant.
Diffusion du contenu
Il est impressionnant de voir qu’il n’est pas utile d’écrire beaucoup pour être lu : en positionnant bien son article, avec une accroche bien faite, quelques lignes et une image spectaculaires suffiront.
Un exemple ? Facile !
Le canal privilégié sera les réseaux sociaux, très peu modérés ou contrôlés. Mais l’information ne sera reprise que si elle est issue d’un compte ayant une certaine popularité ou s’étant construit une image de confiance (apparente) suffisante.
Le compte créé pour l’occasion
Les comptes créés spécialement pour diffuser des fake news ont souvent des caractéristiques communes :
- Compte récent (car les comptes douteux finissent heureusement souvent par être supprimés) ;
- L’activité est surtout du relais d’information, et peu de création par lui-même ;
- Beaucoup de mentions de type j’aime, ce qui s’achète facilement ;
- En général peu d’abonnés, ou des abonnés de profil douteux (mais c’est difficile à contrôler).
Le compte original (par compromission)
La compromission d’un compte légitime est aussi possible, via phishing ou grâce aux questions secrètes encore beaucoup trop utilisées. Quoi de mieux que l’original pour diffuser une info bidon ?
La contrepartie est la limitation dans le temps : souvent surveillés, ils finissent par être redonnés à leurs propriétaires.
Double switch
Plus subtil, cette technique consiste à compromettre n’importe quel compte ayant un bon niveau de confiance. Sur Twitter, l’attaquant change ensuite le nom du compte pour celui qu’il veut (Donal__Trump par exemple), ce qui libère l’ancien… qu’il peut ensuite reprendre puisqu’il vient lui-même de le libérer !
Ainsi il dispose d’un compte ayant de nombreux followers, avec une identité qu’il a choisie (le compte original), et un autre compte (sans réputation ni followers) mais avec le nom du compte original ! Pas mal avec une seule compromission, non ?
Autres voies (voix)
Tout s’achète, y compris certains comptes de réseaux sociaux (avec leur public de followers). Et les blogs ou autres forums peuvent aussi encore servir, tout comme les commentaires (issus de robots ou pas).
Propagation
Une fois diffusé, le mécanisme continue : il faut toucher le public le plus large possible, et les réseaux sociaux font merveilles dans le domaine (et encore plus s’ils sont aidés par des robots).
Comment on lutte
Comme on peut, surtout que les mesures préconisées sont souvent contradictoires avec la liberté d’expression ou la neutralité du net.
- https://www.theguardian.com/media/2018/apr/24/eu-to-warn-social-media-firms-over-fake-news-and-data-mining
- https://www.reuters.com/article/us-eu-internet-fakenews/eu-piles-pressure-on-social-media-over-fake-news-idUSKBN1HX15D
- http://europa.eu/rapid/press-release_IP-18-3370_fr.htm
Voir aussi
Formations
Voici une page spéciale avec différentes sources de sensibilisation et d’information :
- https://secnumacademie.gouv.fr/
- https://www.skillset.com/ pour évaluer ses connaissances, en vue d’une certification par exemple.
- https://www.skillset.com/
- https://www.information-security.fr/
- https://www.root-me.org/
- https://podcloud.fr/podcast/comptoir-secu (podcasts)
- https://www.reddit.com/r/netsec
- https://www.zenk-security.com/
Outils
Sites, podcasts, etc.
Sensibilisation pour les enfants
- https://www.securitytuesday.com/wp-content/uploads/2018/10/ISSA.Cahier.SecNum777.pdf
- https://github.com/wavestone-cdt/1-2-3-Cyber
RGPD
- https://atelier-rgpd.cnil.fr/ (MOOC de la CNIL)
Biométrie
Voir aussi Le doigt dans l’œil de la biométrie (nextinpact.com).
La biométrie n’est pas, selon moi, adaptée aux processus informatiques. Point final. Et je ne parle même pas des problèmes d’implémentation1… Alors pourquoi ça a le vent en poupe ?
- Parce qu’il existe désormais des dispositifs grand public, comme sur les smartphones ;
- Parce que c’est confortable ;
- Parce que ça donne un faux sentiment de sécurité ;
- Parce que le marketing crie plus fort que la sécurité.
Alors pourquoi on nous en vend autant ? Parce qu’on peut en vendre, justement. Avant on ne pouvait pas, car les lecteurs biométriques étaient trop chers. Maintenant qu’ils sont bon marché, on profite de leur prétendue sécurité, issue probablement de l’image véhiculée par le cinéma de science fiction.
Définition
Un système de contrôle biométrique est un système automatique de mesure basé sur la reconnaissance de caractéristiques propres à l’individu (définition du CLUSIF). Il peut en être fait différents usages, mais en informatique, on l’utilise quasi-exclusivement dans des processus d’authentification.
Historiquement, la biométrie est une innovation datant de la préhistoire2 : les artistes utilisaient déjà la forme de leur main3 pour signer leurs peintures, ce qui constitue une forme d’identification biométrique (avec trace, cf ci-dessous).
Facteur d’authentification
Tout d’abord, il faut se rappeler ce qu’est un facteur d’authentification : un moyen de prouver au système que vous êtes bien celui que vous prétendez être.
L’illusion de la sécurité
Tout d’abord, le sentiment de sécurité en ce qui concerne la biométrie provient de l’idée fallacieuse que nous sommes les seuls à disposer des originaux : nos empreintes digitales, la forme de notre main, et donc de toutes les caractéristiques utilisées en biométrie.
Pour commencer, cela est tout d’abord variable selon le type de caractéristique utilisé. La CNIL propose une classification en trois grands groupes4.
Classification CNIL (ancienne)
- Biométrie sans trace
- Biométrie avec trace
- Biométrie intermédiaire
Les caractéristiques biométriques sans trace sont celles qu’on ne peut que lire, sans pouvoir les copier ou ne recueillir un échantillon. Le scan du réseau veineux de la main est un exemple de système de biométrie sans trace : seul un capteur peut lire la forme voulue, on ne peut pas la reproduire (c’est-à-dire qu’on ne sait pas faire de main artificielle ayant les mêmes caractéristiques), et l’utilisateur ne laisse pas derrière lui de trace permettant de retrouver ses caractéristiques biométriques. Les systèmes sans trace sont a priori les meilleurs candidats pour l’authentification biométrique.
Les systèmes avec traces semblent moins propices à l’utilisation, car ils sont par définition ceux où l’utilisateur peut laisser des traces, soit lors de l’authentification, soit en dehors. L’empreinte digitale en est l’exemple parfait : nous laissons nos empreintes partout, ce qui a fait dans un premier temps la joie des policiers de l’identification criminelle, et ce qui fait ou fera la joie des pirates d’ici peu.
Les systèmes intermédiaires sont entre les deux : ils ne laissent pas de trace directement, mais il est (plus ou moins) facile de se procurer un échantillon. La voix, la forme du visage ou la forme de l’iris en font partie. La voix peut être enregistrée, notre visage peut être retrouvé partout, y compris maintenant grâce aux système de vidéosurveillance.
Nouvelle doctrine CNIL
La CNIL considère désormais que toutes les biométries sont à traces. Je trouve ça un tantinet exagéré, mais pourquoi pas : nous laissons tellement de traces directes ou indirectes de nos jours… La biométrie veineuse doit encore être sans trace, mais elle reste trop contraignante pour atteindre le grand public.
De fait, la CNIL classe les solutions en fonction du contrôle que l’utilisateur peut exercer sur la biométrie :
- Solutions où l’utilisateur garde le contrôle complet de la biométrie (exemples : l’empreinte digitale stockée uniquement localement sur son smartphone ou sur un badge détenu par l’utilisateur). On parle de type 1 ;
- Solutions où le gabarit est stocké avec une responsabilité partagée (stockage du gabarit non contrôlé par l’utilisateur mais protégé en accès, par exemple avec un chiffrement dont la clé n’est détenue que par l’utilisateur). On parle alors de type 2 ;
- Solutions où l’utilisateur n’a pas de contrôle sur l’utilisation des gabarits (le gabarit biométrie peut être utilisé sans que la personne n’en soit informée), ou type 3.
Une note sur la centralisation
Autrefois, il était impossible d’avoir une base biométrique centralisée sans avoir une autorisation de la CNIL.
Aujourd’hui c’est un peu différent : il n’y a plus d’autorisation CNIL ! On passe sur le régime des PIA (Privacy Impact Assessment), déclaratif (mais obligatoire dans le cas de la biométrie). Mais la CNIL conserve une doctrine d’usage de la biométrie, et il faudra rester dans les clous : inutile d’espérer centraliser des tonnes de données biométriques sans savoir une bonne raison de le faire, notamment dans le cadre professionnel (cf. délibération 2019-001 de la CNIL).
Biométrie locale vs. base centralisée
L’avantage d’une base locale est évidente en termes de protection de la vie privée : seul l’utilisateur dispose du système biométrique et reste maître du stockage de la donnée, comme dans le cas des lecteurs d’empreinte des téléphones portables.
L’inconvénient est que cela ne permet que de vérifier que l’utilisateur est le bon lors de l’authentification : on ne compare la mesure qu’au seul individu connu dans le système : on fait une comparaison 1 à 1.
Dans une base centralisée, comme par exemple l’authentification vocale par téléphone, les données sont chez le fournisseur de l’accès, avec une maîtrise moins facile par l’utilisateur.
L’avantage de la centralisation est de permettre la confrontation 1 à n : un utilisateur essayant de s’authentifier vocalement avec des identités différentes pourra être signalé par le système, par exemple. Autre cas d’usage : un utilisateur appelle, et le système le reconnaît automatiquement, en comparant sa voix avec celles qu’il connaît : l’authentification se fait sans friction.
Dans certains cas il s’agit d’un choix à faire ; dans d’autres, c’est imposé par la solution.
Inattaquable
La plus grosse des erreurs
La plus grosse des erreurs quand on parle de biométrie est d’imaginer que c’est difficile voire impossible à contrefaire ou reproduire. Peut-être dans certains cas, mais cela ne rend pas la biométrie inattaquable, car il y a d’autres façons d’attaquer un système biométrique, comme l’attaque matérielle. Sans compter que si, les données biométriques peuvent être contrefaites ou reproduites.
Et si je ne me fais rien voler ?
Si on ne vous vole pas directement vos données biométriques, on peut encore les récupérer sur les interfaces physiques de liaison, trop souvent oubliées dans le domaine de la sûreté. Le dispositif pour lire le bus de données est en vente libre5 pour pas très cher…
Egalité et ressemblance
Une autre énorme erreur concernant la biométrie est de croire qu’elle est exacte. Or toutes les biométries sont basées sur des mesures, faites par des capteurs, ayant tous une marge d’erreur.
Ouvrons le score
Sans compter que certaines caractéristiques ne sont pas strictement identiques selon les mesures : l’ADN change peu, mais la voix ou même les empreintes peuvent connaître des modulations. Pour établir une correspondance biométrique, on utilise donc toujours un score et non une égalité parfaite (même pour l’ADN).
Ce score est issue de la mesure, transformée en score de ressemblance avec le gabarit de référence (= la voix de référence, l’empreinte de référence, etc.).
On considère ainsi que le spécimen mesuré par le capteur est bien celui qu’on attend quand la ressemblance est suffisante : une empreinte digitale sera considérée comme celle attendue si elle présente suffisamment de points correspondants à l’empreinte attendue.
C’est bien différent d’un mot de passe où soit le mot de passe est le bon, soit il est différent (processus binaire).
Faux et usage de taux
Il existe de nombreux faux en biométrie. C’est-à-dire des valeurs permettant de mesurer et de calibrer un système biométrie, dont les plus courants sont les faux positifs et les faux négatifs.
Faux positifs
Un faux positif est la situation où le système biométrique laisse passer un imposteur : on pense que l’authentification est positive, c’est-à-dire qu’on a identifié un utilisateur légitime, alors que c’est faux.
Faux négatifs
A l’inverse, l’authentification est négative quand on rejette un utilisateur. Or s’il s’agit d’un utilisateur légitime, il sera rejeté à tort : on sera donc dans le cas d’un faux négatif.
Taux et mesures
On utilise les taux de faux positifs (False Acceptance Rate) et de faux négatifs (False Rejection Rate) pour mesurer le fonctionnement d’un système biométrique.
On pense naïvement qu’il faut que les deux taux soient les plus bas possibles pour que le système soit parfait. Or c’est faux. Ces deux taux ne sont pas réglables si facilement et surtout ils ont une influence énorme sur le fonctionnement du système.
Revenons au score
Imaginons qu’une mesure donne un score de similarité de 99% (par exemple). Avons-nous identifié la bonne personne ?
Ca dépend
Ben oui : tout dépend de la tolérance qu’on va autoriser, par choix. Si on est très tolérant, alors cela implique qu’on sera moins strict et qu’une mesure donnant un résultat moins bon (98% par exemple) sera accepté pour identifier l’individu.
Augmenter la tolérance implique d’accepter plus facilement l’utilisateur, donc augmente le risque d’accepter un imposteur !
Ok ? Un utilisateur légitime aura moins de mal à s’authentifier puisqu’on est tolérant, et donc qu’on accepte le risque de laisser passer un imposteur, ce qui augmente les faux positifs.
Diminuer la tolérance implique d’accepter plus difficilement un utilisateur, donc diminue le risque d’accepter un imposteur !
C’est bien dans l’absolu, car on diminue le risque de fraude ; par contre on augmente l’inconfort pour l’utilisateur légitime qui risque de devoir s’y prendre à plusieurs fois pour s’authentifier.
Il faut choisir !
Dilemne : souhaite-t-on privilégier le confort de l’utilisateur ou la sécurité ? Pour cela le seul moyen est de varier la sensibilité de la mesure (et du score de ressemblance) mais tout est lié : augmenter la sensibilité fait baisser le FAR mais augmente le FRR ! Et inversement. Donc soit c’est le confort, soit c’est la sécurité.
Taux d’erreur équivalent
Une mesure souvent utilisée pour mesurer la qualité d’un système biométrique est le taux d’erreur équivalent (Equivalent Error Rate). C’est conventionnellement le taux où FAR = FRR.
On a vu que les taux FAR et FRR peuvent varier, mais en restant liés l’un avec l’autre : augmenter l’un diminue l’autre. Donc ne prendre en compte que l’un des deux n’a pas de signification puisqu’ils sont… variables ! Et pour avoir un chiffre qui caractérise les deux, on prend le point où ces taux se rencontrent.
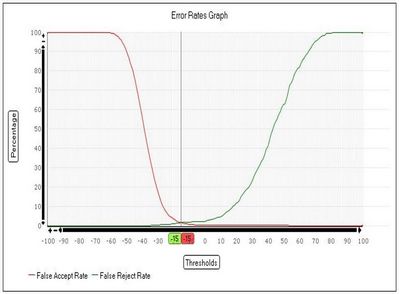
et FRR (faux négatifs), pour de la biométrie vocale.
Cette courbe (ou son équivalent) est souvent
appelée Detection error trade-off (DET).
L’intérêt de ce point fixe est qu’il caractérise toutes les solutions de biométrie. Plus il est bas, plus la solution est précise. Ici, pour la biométrie vocale, on est aux alentours de 1-1,5%.
Autre critère important : la forme de la courbe. Elle indique comment varie les FAR et FRR selon qu’on le bouge dans un sens ou dans l’autre.
Un autre critère oublié
Pour qu’une authentification biométrique soit utilisable, elle doit combiner plusieurs caractéristiques ; elle doit être :
- Discriminante (deux individus différents doivent avoir des caractéristiques différentes, idéalement uniques) ;
- Universelle (ce qui n’est jamais le cas en biométrie, d’où l’obligation d’avoir une solution alternative) ;
- Permanente (ou au moins relativement stable dans le temps) ;
- Mesurable et enregistrable ;
- Infalsifiable.
Or il est impossible d’affirmer qu’une solution est infalsifiable : on peut tout au plus affirmer qu’à notre connaissance, elle est infalsifiable. A contrario, on peut affirmer qu’elle est attaquable quand il existe au moins un scénario d’attaque.
En 2018, quasiment toutes les caractéristiques biométriques peuvent être reproduites de façon à tromper les capteurs, car quasiment aucun d’eux ne vérifie que la personne est effectivement présente lors de l’authentification !
La liveness detection (la vivantitude en français, la détection du vivant) est oublié de quasiment toutes les solutions de biométrie, ou elle n’est que très sommaire (et elle peut être également trompée).
- Dans le cas d’une empreinte digitale, certains capteurs (perfectionnés) vérifient la conductivité de la peau ou sa chaleur, caractéristiques pouvant être reproduites facilement ;
- Dans l’authentification du visage, le capteur peut demander à bouger la tête pour éviter le présentation d’une photo ; il suffit alors de présenter… une vidéo !
A partir du moment où presque toutes les biométries laissent des traces, et qu’on peut donc reproduire les caractéristiques souhaitées, la détection de vie devrait être un impératif pour tous les systèmes biométriques : personne n’est capable (pour l’instant) de reproduire un être vivant (ou suffisamment vivant) pouvant tromper les capteurs. Or cette liveness detection est délaissée, probablement car elle est très complexe à mettre en oeuvre.
Or tant que cette détection de vie ne sera pas en place, toutes les biométries présentées à froid ne seront pas dignes de confiance. Et si on arrive à un niveau élevé de détection de vie, il faudra garder à l’esprit que les pirates ont plus d’imagination que nous pour tromper les systèmes.
Premières attaques industrielles
Beaucoup de hacks et du bon sens
L’empreinte digitale est curieusement très utilisée, alors que c’est un assez mauvais candidat puisqu’étant avec traces. Le Chaos Computer Club a pu tromper très rapidement le système biométrique de l’iPhone, puis du Samsung S5, et surtout à démontré qu’il était possible de récupérer une image de l’empreinte suffisamment précise pour être utilisée à partir d’un appareil photo du commerce, à une distance de trois mètres6.
Ensuite il faut faire preuve de bon sens : sécuriser un terminal grâce à une empreinte qu’on retrouve… partout sur le terminal lui-même, car il est rare de porter des gants avec nos smartphones ! Surtout si on veut utiliser la saisie tactile ou le lecteur d’empreinte. Et comme la mode est aux surfaces brillantes…
Bien que je préfère espérer que certains faits divers stupéfiants ne restent qu’exceptionnels, mais il y a déjà des précédents :
- Trois individus arrêtés après avoir kidnappé une fillette afin de falsifier un test ADN7 ;
- Alsace : Il utilisait le doigt coupé de sa victime pour usurper son identité8.
J’ai peur que la nature humaine ne pousse des criminels à des actions de plus en plus insensées pour contourner la quasi-exactitude d’une identification biométrique. Comme il est précisément impossible de modifier ses caractéristiques biométriques, des malfrats vont (et l’ont déjà fait) mettre en oeuvre des scenarii insensés et violents soit pour récupérer les identifiants biométriques, soit pour disposer d’échantillons permettant de créer une fausse identité. Au lieu de nous protéger, la biométrie forcera les malfaiteurs à attaquer physiquement les individus, avec la part de violence que cela peut engendrer.
Quelques chiffres et éléments de comparaison
Je me base ici sur les chiffres fournis par les constructeurs ou intégrateur de systèmes biométriques (tels qu’Apple, Samsung9 ou ZTE10). Apple indique que le taux d’erreur de son système de biométrie (EER) par empreinte est de l’ordre de 1 pour 50 000. Pour Fujitsu, qui équipe le ZTE, ce taux est meilleur puisqu’il est de 1 pour 250 000.
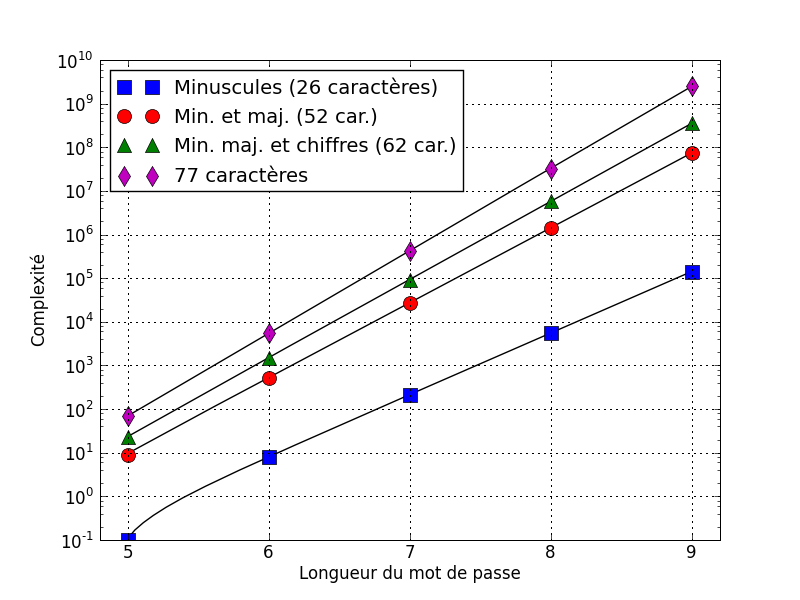
Un petit rappel : un mot de passe ne comprenant que des lettres (majuscules et minuscules) et faisant 8 caractères de long, on est à 1 pour 218 340 105 584 896. C’est donc 200 millions de fois plus complexe qu’un scan de l’iris.
A contrario, un code PIN sur 5 chiffres donne 1 pour 100 000, sachant qu’un code PIN peut être répudié. Donc un scan de l’iris est comparable à un code PIN de 5 chiffres, en moins bien (car impossible à répudier). Côté Apple, le lecteur d’empreinte Apple donné 1 pour 50 00011 n’équivaut donc qu’à un code PIN de 4 chiffres (je me répète : en moins bien, car impossible à répudier).
Donc contrairement aux discours commerciaux comme ceux de ZTE, ça n’est absolument pas en termes de sécurité qu’il faut voir les choses mais en termes de confort et d’expérience utilisateur12.
Et le vol de données biométriques ?
Si je me fais voler mon empreinte, c’est grave ?
La réponse est : non, tout va bien. Enfin presque. Normalement. Dans l’état actuel de la technologie. Rassurant, non ?
Oui, car il faut tempérer les propos rassurants comme suite à l’affaire de vol de données confidentielles de l’OPM13 : après quelques investigations, ils se rendent compte que ça n’est pas 1 mais 5 millions d’empreintes qui sont dans la nature 14, mais qu’heureusement il est difficile d’en faire quelque chose… dans l’état actuel des technologies…

Par chance, le gouvernement américain reviendra vers les victimes si, dans le futur, cela devenait possible. Comme vous le voyez, la biométrie des empreintes digitales est une technique sûre !
Un petit rappel : si une donnée biométrique est compromise (par exemple votre empreinte), non seulement c’est à vie mais également sur tous les autres dispositifs utilisant cette empreinte. Dire qu’on conseille de ne pas réutiliser le même mot de passe sur différents sites, avec une empreinte (ou n’importe quelle donnée biométrique), vous l’utilisez partout à l’identique !
Or où peut-on trouver facilement l’original d’une empreinte utilisée pour déverrouiller un smartphone ?
Et la voix ?
En tant que technologie intermédiaire, c’est plus risqué. Cela dit, il faut que le pirate puisse enregistrer votre voix, de préférence lorsque vous prononcez la phrase servant à l’authentification. Et encore, les systèmes de reconnaissance ont des mécanismes anti-rejeu. Enfin, parfois. A moins que… A moins qu’on puisse à partir d’échantillons divers de votre voix reconstruire la phrase qu’on veut. Mais ça, c’est de la science-fiction15. Et je ne parle même pas des frères jumeaux16 !
Et l’iris ?
Ayé, c’est fait : le CCC a réussi à en faire son affaire17…
Et la tête ?
Alouette. Maintenant (2018) on peut déverrouiller son smartphone en montrant sa tronche. Il va donc falloir se promener cagoulé pour éviter la compromission de mon moyen d’authentification.
Biométrie révocable
Une solution idéale en biométrie serait de pouvoir révoquer la donnée biométrique utilisée. Or les quelques propositions qu’ont trouve dans la nature n’évoquent que la révocation des minuties stockées, et non de la donnée de base. De plus, la sécurité du stockage est trop souvent perfectible, et quoi qu’il en soit ce stockage sera toujours attaquable.
Voir https://hal.archives-ouvertes.fr/hal-01591593/document
Et dans les autres pays : c’est comment ?
Il me semble que pour l’instant c’est pire chez les autres, et pas trop mal chez nous, les petits zeuropéens protégés un peu par le RGPD.
Vulnérabilités
- (Android) https://www.forbes.com/sites/thomasbrewster/2018/12/13/we-broke-into-a-bunch-of-android-phones-with-a-3d-printed-head/
- https://www.theguardian.com/technology/2018/nov/15/fake-fingerprints-can-imitate-real-fingerprints-in-biometric-systems-research
- https://www.theguardian.com/technology/2014/dec/30/hacker-fakes-german-ministers-fingerprints-using-photos-of-her-hands
- https://www.theguardian.com/technology/2017/may/23/samsung-galaxy-s8-iris-scanner-german-hackers-biometric-security
- Reconnaissance faciale : officiellement interdite, elle se met peu à peu en place
- Empreinte digitale, Samsung S10 fraîchement sorti
https://threatpost.com/samsung-galaxy-s10-fingerprint-sensor-duped-with-3d-print/143624/
Voir aussi
Liens web
- Your phone’s biggest vulnerability is your fingerprint https://www.theverge.com/2016/5/2/11540962/iphone-samsung-fingerprint-duplicate-hack-security
- https://threatpost.com/biometrics-security-solution-issue/139781/
- https://threatpost.com/biometrics-in-2019-increased-security-or-new-attack-vector/140683/
- https://www.infosecurity-magazine.com/opinions/strengths-weaknesses-biometrics/
- http://www.zdnet.fr/actualites/iphone-6-touchid-reste-vulnerable-selon-lookout-39806767.htm
- http://www.zdnet.fr/actualites/iphone-5s-la-securite-du-lecteur-biometrique-deja-contournee-39794213.htm
- http://fr.ubergizmo.com/2014/03/galaxy-s5-lecteur-empreinte-digitale-aurait-problemes/
- http://www.cnet.com/news/apples-touch-id-still-vulnerable-to-hack-security-researcher-finds/
- http://www.techinsights.com/teardown.com/apple-iphone-6/http://support.apple.com/kb/HT5949?viewlocale=fr_FR
- http://support.apple.com/kb/HT5883?viewlocale=fr_FR
- https://www.apple.com/fr/iphone-6/touch-id/
- http://techcrunch.com/2014/02/26/the-fingerprint-scanner-on-the-samsung-galaxy-s5-will-be-accessible-by-developers/?ncid=rss
- http://techcrunch.com/2014/02/26/how-touch-id-and-secure-enclave-work/
- http://web.mit.edu/6.857/OldStuff/Fall03/ref/gummy-slides.pdf
- https://www.schneier.com/blog/archives/2013/09/iphone_fingerpr.html
- https://www.schneier.com/blog/archives/2013/09/apples_iphone_f.html
- http://appleinsider.com/articles/14/09/17/apple-opens-touch-id-to-third-party-applications-with-ios-8
- http://www.zdnet.fr/actualites/securite-d-ios-le-ver-et-la-pomme-39798417.htm
- http://techzei.com/apple-touch-id-and-secure-enclave/
- http://www.quora.com/What-is-Apple%E2%80%99s-new-Secure-Enclave-and-why-is-it-important/answers/3136875
- http://www.arm.com/products/processors/technologies/trustzone/index.php
- http://www.cnis-mag.com/hacking-mobile-mon-petit-doigt-m%e2%80%99a-dit%e2%80%a6.html
- http://www.cnil.fr/les-themes/identite-numerique/fiche-pratique/article/les-francais-plutot-reserves-sur-lusage-de-la-biometrie-dans-la-vie-quotidienne-selon-une/
- http://www.cnil.fr/documentation/fiches-pratiques/fiche/article/biometrie-des-dispositifs-sensibles-soumis-a-autorisation-de-la-cnil/
- http://www.zdnet.fr/actualites/smartphones-lg-met-au-point-un-ecran-capable-de-lire-les-empreintes-digitales-39836286.htm
- http://www.slate.com/articles/technology/future_tense/2015/02/future_crimes_excerpt_how_hackers_can_steal_fingerprints_and_more.html
- https://www.theguardian.com/technology/2014/dec/30/hacker-fakes-german-ministers-fingerprints-using-photos-of-her-hands
- http://www.telegraph.co.uk/technology/2016/05/26/biometrics-will-replace-passwords-but-its-a-bad-idea/
- https://securitycommunity.tcs.com/infosecsoapbox/articles/2017/01/05/15-important-pros-and-cons-biometric-authentication(avec des arguments à réfuter)
- https://www.forbes.com/sites/thomasbrewster/2015/03/05/clone-putins-eyes-using-google-images/#2d662be2214a
- https://hackaday.com/2015/11/10/your-unhashable-fingerprints-secure-nothing/ Principaux arguments
- http://www.zdnet.fr/actualites/la-reconnaissance-faciale-se-trompe-dans-98-des-cas-39868094.htm
- https://www.nytimes.com/2018/07/08/business/china-surveillance-technology.html Paradis de l’AI et de la biométrie faciale
- https://www.securiteinfo.com/conseils/biometrie.shtml
- https://www.aware.com/quest-ce-que-la-biometrie/
- https://www.iis.sinica.edu.tw/~swc/pub/trajectory_analysis_verification.html
- Mouvement des yeux https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0194475
- Gemalto (très complet)
Sources et autres présentations
- https://www.beat-eu.org/project/deliverables-public/d3.3-description-of-metrics-for-the-evaluation-of-biometric-performance
- https://www.lebigdata.fr/donnees-biometriques-definition-securite
- https://www.legifrance.gouv.fr/affichTexte.do?cidTexte=JORFTEXT000038277620&categorieLien=id
- Règles d’utilisation : https://www.futura-sciences.com/sciences/questions-reponses/sciences-sont-regles-identification-empreintes-digitales-12499/
- Authentification biométrique: Les points positifs, négatifs et le côté obscur | OneLogin’
- MasterPrint: Exploring the Vulnerability of Partial Fingerprint-Based Authentication Systems – IEEE Journals & Magazine
Darkweb
La récente salve de francisation de termes informatiques n’a pas fait que des heureux. Plusieurs voix se sont élevées contre l’institutionnalisation de fait de termes abscons, comme darkweb et deepweb dont l’existence même prête à polémique.
Autant un portail de messagerie (« webmail ») est un concept clair pour tous, autant les notions d’internet clandestin (« darkweb ») ou de toile profonde (« deepweb ») n’ont pas de réalité si tangible que ce qu’on veut bien nous faire croire.
Le cas des clandestins
Le Larousse nous apprend que clandestin peut signifier « qui se cache » mais aussi « qui contrevient à la loi ou qui se dérobe au contrôle ». Cela peut tout à fait s’appliquer à l’internet de Mme Michu, car nombre de sites web d’accès public contreviennent allègrement à plusieurs lois françaises : tel site d’un journal people qui reprend des clichés violant la vie privée de personnalités, tel autre qui diffuse de annonces liées à des escroqueries diverses (la bague qui guérit tout, le gain assuré au loto, l’augmentation de volume de [ce qu’on veut], la promesse de gains mirobolifiques sur des marchés financiers qu’on cache être extrêmement risqués), la vente d’armes sur Facebook ou Instagram, etc.
Par ailleurs, se dérober au contrôle est parfois une mesure salutaire notamment dans les pays (grands ou petits) où la censure sévit et où la clandestinité est la seule option permettant de vivre (ou survivre). Aller sur l’onionland ou utiliser des VPN est nécessaire à certains.
Sombre internet
D’après S. Bortzmeyer, la définition correcte de deepweb serait :
Concept débile, peu ou pas défini, flou, et qui ne sert qu’aux politiciens et journalistes sensationnalistes.
La définition officiellement retenue est :
Partie de la toile qui n’est pas accessible aux internautes au moyen des moteurs de recherche usuels.
Ce qui est sans aucun rapport avec la notion qu’on veut mettre dans ce deepweb peuplé uniquement de méchants qui se cachent pour comploter, car il y a un tas de raisons pour lesquelles les moteurs de recherche n’indexent pas : je prenais le cas d’un portail de messagerie, dont la quasi-totalité du contenu n’est accessible qu’à un utilisateur authentifié (et donc inaccessible aux moteurs de recherche). Ce portail de messagerie serait donc à classer dans le deepweb. Or consulter ce deepweb vous expose directement à l’excommunication ou à des poursuites pénales, bien entendu. Idem pour tous les sites utilisant un fichier robots.txt.
Deep ou dark ? Blanc ou noir ?
J’avoue moi-même ne plus bien réussir à faire la différence entre ces deux notions, tant elles sont floues. Une distinction plus simple et plus claire serait peut-être de parler d’activités légales ou d’activités illégales sur internet, quels que soient les moyens employés, puisqu’on peut vendre de la drogue sur l’internet « classique » et tenter de sauver sa famille sur l’internet « clandestin ». Toutefois, le darkweb désigne plus généralement :
Réseau accessible uniquement via des outils spécifiques, comme le navigateur Tor.
Après, Tor ou Freenet ne sont pas vraiment des réseaux séparés, puisqu’ils utilisent l’infrastructure d’internet. On parle de réseaux « overlays », qui se superposent sur des réseaux existants.
Internet n’est qu’une sorte de reflet des activités humaines : les truands se cachent, sauf parfois pour escroquer les gens ou faire leur business. Et les gens normaux sont parfois tentés d’être discrets pour de bonnes raisons. Le darkweb sera d’ailleurs peut-être la dernière solution pour tenter de garder un soupçon de vie privée.
The Dark Web Boundaries Are Not Always Clear, and Many Sites Fall in a Gray Area
Idan Aharoni on SecurityWeek.com
Sources
- http://www.zdnet.fr/blogs/50-nuances-d-internet/
- https://www.nextinpact.com/news/105256-ne-dites-plus-darknet-mais-internet-clandestin-dark-web-mais-toile-profonde.htm
Articles externes
Rootkit
Un rootkit (en français : « outil de dissimulation d’activité »1) est un type de programme (ou d’ensemble de programmes ou d’objets exécutables) dont le but est d’obtenir et de maintenir un accès frauduleux (ou non autorisé) aux ressources d’une machine, de la manière la plus furtive et indétectable possible.
Le terme peut désigner à la fois la technique de dissimulation ou son implémentation (c’est-à-dire un ensemble particulier d’objets informatiques mettant en œuvre cette technique).
Historique
Le phénomène n’est pas nouveau : des programmes manipulant les logs système, tout en se dissimulant des commandes donnant des informations sur les utilisateurs (telles que who, w, ou last), sont apparus en 1989{{Lien web | url = http://www.sans.org/reading_room/whitepapers/honors/linux_kernel_rootkits_protecting_the_systems_1500?show=1500.php&cat=honors | titre = Linux kernel rootkits: protecting the system’s « Ring-Zero » | date = mars 2004 | éditeur = SANS Institute }} ; les premiers rootkits sur Linux et Solaris ont été rencontrés au début des années 19902 et ont été répertoriés en tant que tels en octobre 1994. Le projet chkrootkit, dédié au développement d’un outil de détection de rootkits pour les plateformes Solaris et HP-UX, a été démarré en 1997.
Il existe des rootkits pour la plupart des systèmes d’exploitation. En 2002, Securityfocus constatait déjà des évolutions et des progrès en matière de rootkit pour les plate-formes Windows. Un des premiers rootkits pour Mac OS X (WeaponX) est apparu en novembre 20043.
Certains rootkits peuvent être légitimes, pour permettre aux administrateurs de reprendre le contrôle d’une machine défaillante, pour suivre un ordinateur ayant été volé4, ou dans des outils comme Daemon Tools ou Alcohol 120%5. Mais aujourd’hui le terme n’évoque quasiment plus que des outils à finalité malveillante.
Mode opératoire
Contamination
La première phase d’action d’un rootkit consiste à chercher un accès au système, sans forcément que celui-ci soit un accès privilégié (ou en mode administrateur). La contamination d’un système peut avoir lieu de différentes façons, en utilisant les techniques habituelles des programmes malveillants. Les moyens les plus courants sont :
- utilisation des techniques virales : un rootkit n’est pas un virus à proprement parler, mais il peut se transmettre par les techniques utilisées par les virus, notamment par un [[Cheval_de_Troie_(informatique)|cheval de Troie]]. Un virus peut avoir pour objet de répandre des rootkits sur les machines infectées (a contrario, un virus peut aussi utiliser les techniques de rootkits pour parfaire sa dissimulation) ;
- mise en œuvre d’un [[Exploit_(informatique)|exploit]], c’est-à-dire l’exploitation d’une vulnérabilité de sécurité, à n’importe quel niveau du système : application, système d’exploitation, BIOS, etc. Cette mise en œuvre peut être le fait d’un virus, mais elle résulte aussi souvent de botnets qui réalisent des scans de machines pour identifier les failles et exploiter celles qui sont utiles à l’attaque ;
- attaque par force brute, afin de profiter de la faiblesse des mots de passe de certains utilisateurs, et obtenir ainsi un accès au système.
Modification du système et dissimulation
Une fois la contamination effectuée et l’accès obtenu, la phase suivante du mode opératoire consiste en l’installation de l’ensemble des objets et outils nécessaires au rootkit. Il s’agit des objets permettant la mise en place de la charge utile du rootkit, s’ils n’ont pas pu être installés durant la phase de contamination, ainsi que les outils et les modifications nécessaires à la dissimulation.
Mise en place de la charge utile
permet d’avoir un accès sur des centaines de machines.]]
La charge utile est la partie active du rootkit (et de tout programme malveillant en général), dont le rôle est d’accomplir la (ou les) tâche(s) assignée au système. La charge utile permet d’avoir accès aux ressources de la machine infectée, et notamment :
- CPU, pour décoder des mots de passe ou plus généralement pour effectuer des calculs distribués à des fins malveillantes ;
- serveur de messagerie, pour envoyer des mails (pourriel ou spam) en quantité ;
- ressources réseaux, pour servir de base de lancement pour des attaques diverses (déni de service, exploits) ou pour sniffer l’activité réseau ;
- pilotes de périphériques, pour installer des enregistreurs de frappe ou keyloggers (par exemple) ;
- accès à d’autres machines, par rebond ;
- prise de contrôle total de la machine (par exemple en remplaçant le procédé de connexion, comme
/bin/loginsous Linux).
Certains rootkits sont utilisés pour l’exploitation de botnets, la machine infectée devenant alors une machine zombie, comme par exemple pour le botnet Srizbi6.
Dissimulation
Le rootkit cherchera également à « dissimuler » son activité. Ce procédé de dissimulation permet évidemment de minimiser le risque de découverte du rootkit, afin de profiter le plus longtemps possible de l’accès frauduleux. Une des caractéristiques principales d’un rootkit est donc sa faculté à se dissimuler, alors qu’un virus cherche principalement à se répandre, ces deux fonctions étant parfois jumelées pour une efficacité supérieure. Selon les cas, plusieurs méthodes peuvent être employées et combinées :
- en ouvrant des portes dérobées, afin de pérenniser l’accès au système et permettre le contrôle de la machine, l’installation de la charge utile, etc27 ;
- en cachant des processus informatiques ou des fichiers ; sous Windows, une technique consiste à modifier certaines clés de la base de registre ; sous Linux, on peut par exemple modifier les fichiers
/usr/include/proc.h(processus à masquer) ou/usr/include/file.h(fichiers à masquer) ; - en remplaçant certains exécutables ou certaines librairies par des programmes malveillants et des chevaux de Troie, contrôlables à distance ;
- en obtenant des droits supérieurs (par élévation des privilèges), afin de désactiver les mécanismes de défense ou pour agir sur des objets de haut niveau de privilèges ;
- en utilisant des techniques de type « {{lang|en|Stealth by Design}} » (littéralement « furtif par conception »)8, à savoir implémenter à l’intérieur du rootkit des fonctions système afin de ne pas avoir à appeler les fonctions standards du système d’exploitation et ainsi éviter l’enregistrement d’événements système suspects ;
- en détournant certains appels aux tables de travail utilisées par le système{{pdf}} {{Lien web |url=http://www.security-labs.org/fred/docs/sstic07-rk-article.pdf|titre=De l’invisibilité des rootkits : application sous Linux|auteur=E. Lacombe, F. Raynal, V. Nicomette|éditeur=CNRS-LAAS/Sogeti ESEC}} par [[Hook (informatique)|hooking]] ;
- en effaçant physiquement toute trace d’activité, notamment dans les journaux de logs système, etc.
Niveau de privilège
Bien que le terme a souvent désigné des outils ayant la faculté à obtenir un niveau de privilège de type administrateur (utilisateur root) sur les systèmes Unix et Linux, un rootkit ne cherche pas obligatoirement à obtenir un tel accès sur une machine (par [[Élévation_des_privilèges|élévation de privilège]]), et ne nécessite pas non plus d’accès administrateur pour s’installer, fonctionner et se dissimuler9. Le programme malveillant Haxdoor10, même s’il était un rootkit du type noyau11 pour parfaire sa dissimulation, écoutait les communications sous Windows en mode utilisateur12 afin de tenter de capturer des identifiants avant cryptage, en interceptant les API de haut niveau.
Cependant, l'[[Élévation_des_privilèges|élévation de privilège]] est souvent nécessaire pour que le camouflage soit efficace : le rootkit peut utiliser certains [[Exploit_(informatique)|exploits]] afin de parfaire sa dissimulation en opérant à un niveau de privilège très élevé, pour atteindre des bibliothèques du système, des éléments du noyau, pour désactiver les défenses du système, etc.
Types
Il existe cinq types principaux de rootkits selon leur cible : les kits de niveau micrologiciel, hyperviseur, noyau, bibliothèque et applicatif.
Niveau micrologiciel/hardware
Il est possible d’installer des rootkits directement au niveau du micrologiciel (ou {{lang|en|firmware}}). De nombreux produits proposent désormais des mémoires flash, ce qui peut être utilisé pour implanter durablement du code13, en détournant par exemple l’usage d’un module de persistance souvent implanté dans le BIOS de certains systèmes.
Un outil légitime utilise d’ailleurs cette technique : LoJack, d’AbsolutSoftware4, qu’on trouve sur des ordinateurs portables car il permet ainsi de suivre un ordinateur à l’insu de l’utilisateur (en cas de vol). Ce code peut « survivre » à un changement de disque dur voire à un flashage du BIOS14 si le module de persistance est présent et actif. Tout périphérique disposant d’un tel type de mémoire est donc potentiellement vulnérable.
Une piste évoquée pour contrer ce genre de rootkit serait d’interdire l’écriture du BIOS (grâce à un cavalier sur la carte-mère ou par l’emploi d’un mot de passe) ou d’utiliser des EFI à la place du BIOS15, mais cette méthode reste à tester et à confirmer16.
Niveau hyperviseur
Ce type de rootkit se comporte comme un hyperviseur classique (de niveau 1) : après s’être installé et avoir modifié la séquence de démarrage, pour être lancé en tant qu’hyperviseur de la machine infectée au démarrage. Le système d’exploitation original se retrouve alors être un hôte (invité) du rootkit, lequel peut alors intercepter tout appel matériel. Il devient quasiment impossible à détecter depuis le système original.
Une étude conjointe de chercheurs de l’université du Michigan et de Microsoft ont démontré la possibilité d’un tel type de rootkit, qu’ils ont baptisé « {{lang|en|virtual-machine based rootkit}} » (VMBR)17. Ils ont pu l’installer sur un système Windows XP et sur un système Linux. Les parades proposées sont la sécurisation du boot, le démarrage à partir d’un média vérifié et contrôlé (réseau, CD-ROM, clé USB, etc) ou l’emploi d’un moniteur de machine virtuelle sécurisé.
Niveau noyau
Certains rootkits arrivent à s’implanter dans les couches du noyau du système d’exploitation soit dans le noyau lui-même, soit dans des objets exécutés avec un niveau de privilèges équivalent au système, ce qui est le cas pour certains pilotes de périphériques.
Sous Linux, il s’agit souvent de modules pouvant être chargés au niveau du noyau (modules de noyau chargeables, ou {{lang|en|loadable kernel modules}}), sous Windows de pilotes informatiques. Avec un tel niveau de privilèges, la détection et l’éradication du rootkit n’est souvent possible que de manière externe au système en redémarrant (en bootant) depuis un système sain, installé sur CD, sur une clé USB ou par réseau.
Ce type de rootkit est dangereux à la fois parce qu’il a acquis des privilèges élevés (il est alors plus facile de leurrer un logiciel de protection), mais aussi par les instabilités qu’il peut causer sur le système infecté comme cela a été le cas lors de la correction de la vulnérabilité MS10-01518, où des [[Écran_bleu_de_la_mort|écrans bleus]] sont apparus en raison d’un conflit entre cette correction et le fonctionnement du rootkit Alureon19.
Niveau bibliothèque
À ce niveau, le rootkit détourne l’utilisation de bibliothèques légitimes du système d’exploitation. Plusieurs techniques peuvent être utilisées :
- en patchant un objet d’une bibliothèque, c’est-à-dire en ajoutant du code à l’objet en question ;
- en détournant l’appel d’un objet (« hooking »), ce qui revient à appeler une autre fonction puis à revenir à la fonction initiale ;
- en remplaçant des appels système par une version spécifique, ce qui correspond à remplacer l’appel système initial par du code malveillant.
Ce type de rootkit est assez fréquent, mais il est aussi le plus facile à contrer, notamment par un contrôle d’intégrité des fichiers essentiels en surveillant leur empreinte grâce à une fonction de hachage, par détection de signature du programme malveillant, ou par exemple par examen des {{lang|en|hooks}} par des outils comme unhide sous Linux ou HijackThis sous Windows.
Niveau applicatif
Un rootkit applicatif implante des programmes malveillants de type [[Cheval_de_Troie_(informatique)|cheval de Troie]], au niveau utilisateur. Ces programmes prennent la place de programmes légitimes ou en modifient le comportement, afin de prendre le contrôle des ressources accessibles par ces programmes.
Exemples
Rootkits Sony
À deux reprises, Sony a été confronté à la présence masquée de rootkits dans ses produits : dans ses clés usb biométriques20 et dans son composant de gestion numérique des droits (DRM)2122 présent notamment sur ses CD audio. Ce rootkit possède lui-même des failles qui peuvent être exploitées.
Ces affaires ont fait un tort important à Sony, aussi bien pour sa respectabilité que financièrement. Dans plusieurs pays, Sony a été poursuivi en justice et obligé de reprendre les CD contenant un rootkit et de dédommager les clients23.
Voir aussi : [[:en:Sony BMG CD copy protection scandal|Sony BMG CD copy protection scandal]].
Exploitation de la vulnérabilité de LPRng
Le CERTA (Centre d’Expertise Gouvernemental de Réponse et de Traitement des Attaques informatiques) a publié, dans une note d’information, l’analyse d’une attaque ayant permis d’installer un rootkit (non identifié), n’utilisant à l’origine qu’une seule faille (répertoriée CERTA-2000-AVI-08724) qui aurait pu être stoppée soit par la mise-à-jour du système, soit par le blocage d’un port spécifique grâce à un pare-feu25.
Cette attaque a été menée en moins de deux minutes. L’attaquant a identifié la vulnérabilité, puis envoyé une requête spécialement formée sur le port 515 (qui était le port exposé de cette vulnérabilité) pour permettre l’exécution d’un code arbitraire à distance. Ce code, nommé « SEClpd », a permis d’ouvrir un port en écoute (tcp/3879) sur lequel le pirate est venu se connecter pour déposer une archive (nommée rk.tgz, qui contenait un rootkit) avant de la décompresser et de lancer le script d’installation.
Ce script a fermé certains services, installé des [[Cheval_de_Troie_(informatique)|chevaux de Troie]], caché des processus, envoyé un fichier contenant les mots de passe du système par mail, et il a même été jusqu’à corriger la faille qui a été exploitée, afin qu’un autre pirate ne vienne pas prendre le contrôle de la machine.
Prévention
Moyens de détection
La mise en œuvre de la détection peut parfois demander un examen du système ou d’un périphérique suspect en mode « inactif » (démarrage à partir d’un système de secours ou d’un système réputé sain), selon le type de rootkit. Les moyens de détection peuvent être :
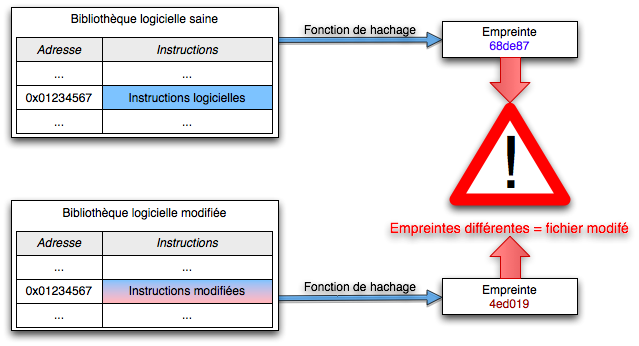
- contrôle de l’intégrité des fichiers : on cherche à détecter toutes modifications des fichiers sensibles (bibliothèques, commandes systèmes, etc)8 en vérifiant régulièrement leur intégrité, en calculant pour chacun d’eux leur empreinte : toute modification inattendue de cette somme indiquera une modification du fichier et une contamination potentielle. Cela demande cependant une analyse car tout système subit aussi des modifications légitimes (comme lors des mises-à-jour du système) ; idéalement, l’outil de contrôle aura la possibilité d’accéder à une base de référence de ces sommes de contrôles, qui variera donc en fonction du système et des versions utilisées (comme rkhunter, par exemple) ;
- détection de leur signature spécifique : il s’agit du procédé classique d’analyse de signature, comme cela se fait pour les virus. On cherche à retrouver dans le système la trace d’une infection, soit directement (signature des objets du rootkit), soit par le vecteur d’infection (virus utilisé par le rootkit)8 ;
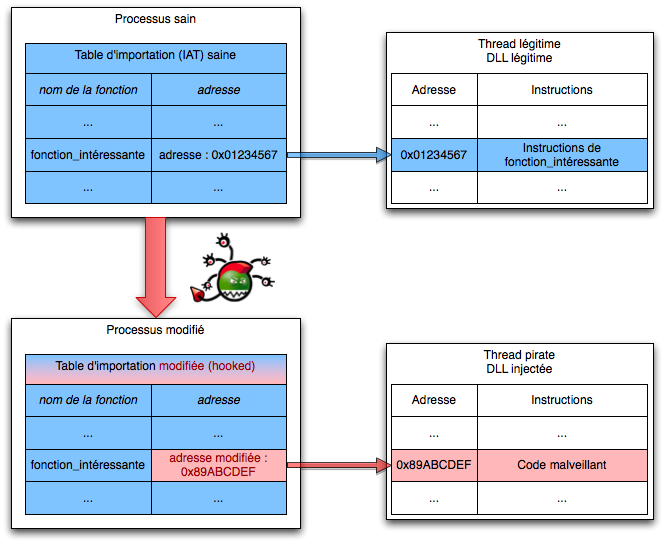
- analyse des appels systèmes : cette technique consiste à analyser la table des appels système, les tables d’interruption (ou Interrupt Descriptor Table)2627 et de manière générale les tables de travail utilisées par le système par des outils comme HijackThis qui permettent de voir si ces appels sont détournés ou non, par exemple en comparant ce qui est chargé en mémoire avec les données brutes de bas niveau (ce qui est écrit sur le disque) ;
- analyse des flux réseau anormaux : cette analyse28 permet de détecter une surcharge ou une utilisation de ports logiciels inhabituels qui peut être observée à partir de la contamination de la machine, grâce aux traces issues d’un pare-feu ou grâce à un outil spécialisé. Il est également possible de faire une recherche des ports logiciels ouverts et de la comparer à ce que connaît le système, avec des outils d’investigation comme unhide-tcp. Toute différence peut être considérée comme anormale. Il existe cependant des moyens de dissimulation réseau, comme de la stéganographie ou l’utilisation de canaux cachés, qui rend la détection directe impossible, et seule une analyse statistique peut éventuellement répondre à cette difficulté29 ;
- analyse des logs système : ce type d’analyse30 automatisée s’appuie sur le principe de corrélation, avec des outils de type HIDS qui disposent de règles paramétrables31 pour distinguer les événements anormaux et mettre en relation des événements systèmes distincts, sans rapport apparent ou différés dans le temps ;
- analyse de la charge système : une surveillance continue peut mettre en évidence un surcharge, à partir de la contamination de la machine. Il s’agit essentiellement d’une analyse statistique de la charge habituelle d’une machine, comme le nombre de mails sortants ou la charge CPU. Toute modification (en surcharge) sans cause apparente est suspecte, mais cela demandera une analyse complémentaire pour écarter toute cause légitime (mise-à-jour du système, installation de logiciels, etc).
- recherche d’objets cachés, tels que des processus informatiques, des clés de registre, des fichiers, etc. Des outils comme unhide sous Linux réalisent cette tâche pour les processus. Sous Windows, des outils comme RootkitRevealer recherchent les fichiers cachés en listant les fichiers via l’API normale de Windows puis en comparant cette liste à une lecture physique du disque ; tout fichier caché (à l’exception des fichiers légitimes connus de Windows, tels que les fichiers métadata de NTFS comme
$MFTou$Secure) est alors suspect32.
Moyens de protection et de prévention
Les moyens de détection peuvent également servir à la prévention, même si celle-ci sera toujours postérieure à la contamination. D’autres mesures en amont peuvent limiter l’installation d’un rootkit33 :
- correction des failles par mise-à-jour de l’OS : cela permet de réduire la surface d’exposition du système en éliminant le temps où une faille est présente sur le système34 et dans les applications30, afin de prévenir les [[Exploit_(informatique)|exploits]] pouvant être utilisés pour la contamination ;
- utilisation d’un pare-feu : cela fait partie des bonnes pratiques dans le domaine de la sécurité informatique, et se révèle efficace dans le cas des rootkits273034 car cela empêche des communications inattendues (téléchargements de logiciel, dialogue avec un centre de contrôle et de commande d’un botnet, etc.) dont ont besoin les rootkits ;
- utilisation d’outil de prévention de type HIPS : ces outils30, de type logiciel ou appliance, répondent dès qu’une alerte est suspectée, en bloquant des ports ou en interdisant la communication avec une source (adresse IP) douteuse, ou toute autre action appropriée. La détection sera d’autant meilleure que l’outil utilisé sera externe au système examiné, puisque certains rootkit peuvent atteindre des parties de très bas niveau dans le système, jusqu’au BIOS même. Un des avantages de ces outils est l’automatisation des tâches de surveillance8 ;
- contrôle d’intégrité des fichiers : des outils spécialisés existent pour remplir cette tâche, et peuvent produire des alertes lors de modifications inattendues. Cependant, ce contrôle à lui seul seul est insuffisant si d’autres mesures préventives ne sont pas mises en œuvre, si aucune réponse du système n’est déclenchée, ou si ces différences ne sont pas analysées. Les HIPS/HIDS, ainsi que certains outils anti-rootkits comme rkhunter peuvent interpréter ces contrôles via une base de sommes de contrôle (pour des versions connues de systèmes d’exploitation) ou par corrélation ;
.]]
- renforcement de la robustesse des mots de passe : il s’agit là encore d’une des bonnes pratiques de sécurité informatique, qui éliminera une des sources principales de contamination. Des éléments d’authentification triviaux sont des portes ouvertes pour tous type d’attaque informatique ;
- démarrage du système à partir d’une image saine : le démarrage à partir d’une image saine, contrôlée et réputée valide du système d’exploitation, via un support fixe (comme un LiveCD, une clé USB) ou par réseau, permet de s’assurer que les éléments logiciels principaux du système ne sont pas compromis, puisqu’à chaque redémarrage de la machine concernée, une version valide de ces objets est chargée. Un système corrompu serait donc remis en état au redémarrage (sauf dans le cas de rootkit ayant infecté le BIOS, qui ne sera lui pas rechargé automatiquement) ;
- moyens de protection habituels : {{citation étrangère |lang=en |Do everything so that attacker doesn’t get into your system}}29. Tous les moyens habituels et classiques de protection d’un système informatique sont utiles, tels que [[Durcissement_(informatique)|durcissement du système]]27, filtrages applicatifs (type mod_security), utilisation de programmes antivirus2734 pour minimiser la surface d’attaque et surveiller en permanence les anomalies et tentatives de contamination, sont bien sûr à mettre en œuvre pour éviter la contamination du système et l’exposition aux [[Exploit (informatique)|exploits]].
Windows 10
Microsoft a travaillé pour rendre l’installation de rootkits plus difficile. Leur travail a porté ses fruits, mais être mieux protégé ne signifie pas être totalement protégé, car un malware (Zacinlo) présent à 90%35 sur des machines Windows a réussi à assurer sa persistance grâce à un rootkit.
Outils et programmes de détection
Bien que les rootkits existent depuis un certain temps, l’industrie de la sécurité informatique ne les a pris en compte (en masse) que récemment, les virus puis les chevaux de Troie accaparant l’attention des éditeurs. Il existe cependant quelques programmes de détection et de prévention spécifiques à Windows, tels que Sophos Anti-Rootkit, ou AVG Anti-Rootkit. Sous Linux, on peut citer rkhunter et chkrootkit ; plusieurs projets open-source existent sur Freshmeat et Sourceforge.net.
Aujourd’hui, il reste difficile de trouver des outils spécifiques de lutte contre les rootkits, mais heureusement leur détection et leur prévention sont de plus en plus intégrées dans les HIPS et même dans les anti-virus classiques, lesquels sont de plus en plus obligés de se transformer en suites de sécurité pour faire face à la diversité des menaces ; ils proposent en effet de plus en plus souvent des protections contre les rootkits, comme Avast, AVG 8.0 ou Microsoft Security Essentials.
Liens externes
- Vidéo sur le rootkit Trojan.Alureon/Trojan.TDSS
- Le danger et fonctionnement des rootkits
- cert-ist.com, CERT dédié à la communauté Industrie, Services et Tertiaire française
- antirootkit.com, site (ancien) listant de nombreux outils
{{Portage}}
Serveur FTP
Pour mettre en œuvre un serveur FTP, il faut penser à quelques éléments de sécurité. Par exemple :
- Cloisonner les utilisateurs
- Interdire les shells
- Contrôler la provenance des requêtes
L’informatique, c’est physique
Je suis un des premiers à le reconnaître, mais j’avais oublié que l’informatique était un objet éminemment physique. A l’ère du tout numérique et de la dématérialisation à tout va, à une époque où on se demande où sont stockées nos données (car bien souvent on ne le sait pas), j’ai suivi une présentation très intéressante au cours du FIC 2018 faite par un géographe, chercheur à l’université (ref), qui nous a remis à l’esprit que derrière l’immatérialité apparente de l’informatique il y avait une réalité bien tangible.
Cette réalité prenait forme d’une très éclairante approche cartographique du cyberespace, au sens très large.
Réalité contre projection
Le cyberespace est d’abord une construction physique, informatique, faite de machines et de câbles désormais répartis partout tout le monde réel.
Ensuite, ce cyberespace sert bien à quelque chose : tout comme l’informatique, il sert à manipuler et interagir sur une projection (une représentation) d’idées et de concepts, dont la plupart sont liés à notre monde réel (mais pas forcément). Si l’informatique a servi dans un premier temps à nous aider à accomplir ou accompagner des tâches réelles (techniques, scientifiques, professionnelles), son évolution a conduit à être utilisée pour interagir avec des objets chimériques ou imaginaires. Un exemple simple de cela est ce que peut représenter un jeu vidéo, qui représente un univers purement imaginaire.
L’idée n’est pas ici de différencier l’usage de l’informatique et du cyberespace en réel ou imaginaire, le fait est qu’on utilise l’informatique et que le contenu traité nous importe. Or comme il nous importe, il est également important d’examiner cet outil qui, bien que traitant d’immatériel (une projection de notre monde ou des concepts), il s’appuie sur des équipements physiques dont l’usage, la géographie et le contrôle sont des enjeux désormais stratégiques, au niveau des Etats.
Exemple de la Géorgie (guerre 2008, rachat d’un opérateur câble).
Cartographie du passage des flux. Tbilissi est plus proche de Sofia que de l’Abkhazie.
Importance militaire et stratégique (coupure en Géorgie et en Crimée).
En cas d’incident
Difficile de donner des consignes générales en cas d’incident. Le CERT-FR a tenté l’exercice avec une infographie assez générique, plutôt destinée aux petites structures1.
Toutefois, dans le cas d’un ransomware, la meilleure solution est d’éteindre immédiatement la machine.
En cas de découverte d’une faille, il est normalement obligatoire de le déclarer en bonne et due forme.2.

NFC
NFC est un acronyme pour Near Field Communication, dont je laisse la description aux spécialistes (ou aux amateurs, selon les points de vue) de wikipedia. Il s’agit d’une technologie radio qui peut être utilisée pour l’échange de données informatiques sans contact, à courte distance.
Dans le milieu où j’évolue (la banque), on redoute les concurrents de type fintechs tout en cherchant à rester en tête de l’innovation. Le NFC a évidemment alimenté les discussions, pour ne pas rater le coche, mais il est souvent judicieux d’attendre un peu avant de se lancer tête baissée dans une technologie, surtout quand elle peine à décoller : les nombreuses expérimentations menées en France ne sont guère convaincantes, et même Gartner qui fait souvent montre d’optimisme, a un avis très mesuré sur cette technologie1.
Pire : fin 2015, un an après le lancement d’un service basé sur le NFC, Apple lui-même semble échouer à faire adopter cette technologie2, principalement en raison de l’usage peu naturel pour les utilisateurs d’un téléphone comme moyen de paiement. Les banques, pourtant, ont tendance à considérer les smartphones comme le Graal des futurs moyens de paiement. Graal ? Peut-être. Mais pas tout de suite. Un autre frein à l’adoption, probablement moins important mais sans doute assez présent, est le niveau de sécurité de la technologie.
NFC : est-ce sûr ou pas ?
Comme souvent, ce n’est pas la technologie en elle-même qui possède des faiblesses (bien que cela puisse arriver), c’est plutôt la manière dont on l’utilise et dont on la met en œuvre qui est perfectible. Or pour le NFC, comme pour l’internet des objets, tout le monde ne jure que par l’usage et l’adoption, sans penser sécurité, alors que pourtant ce point est crucial pour l’adoption d’un moyen de paiement. Et tôt ou tard on s’en mordra les doigts… Or même les grands opérateurs sont parfois légers sur le sujet3. Les premières attaques seraient déjà en cours (attaque réelle ou proof-of-concept sur un utilisateur ciblé ?)4.
Références
- http://www.zdnet.fr/actualites/apple-pay-aurait-deja-vecu-son-age-d-or-39824616.htm
- http://www.gartner.com/newsroom/id/2846017
Botnet
Un botnet est un ensemble de bots informatiques qui sont reliés entre eux. Historiquement, ce terme s’est d’abord confondu avec des robots IRC (bien que le terme ne se limitait pas à cet usage spécifique), qui était un type de botnet particulier servant sur les canaux IRC.
Usage légitime
Sur IRC, leur usage est de gérer des canaux de discussions, ou de proposer aux utilisateurs des services variés, tels que des jeux, des statistiques sur le canal, etc. Être connectés en réseau leur permet de se donner mutuellement le statut d’opérateur de canal de manière sécurisée, de contrôler de manière efficace les attaques par flood ou autres. Le partage des listes d’utilisateurs, de bans, ainsi que de toute sorte d’informations, rend leur utilisation plus efficace.
Il existe d’autres usages légitimes de botnets, comme l’indexation web : le volume des données à explorer et le nécessaire usage de parallélisation impose l’usage de réseaux de bots.
Dérives et usages malveillants
Les premières dérives sont apparues sur les réseaux IRC1 : des botnets IRC (Eggdrop en décembre 1993, puis GTbot en avril 1998) furent utilisés lors d’affrontements pour prendre le contrôle du canal.
Aujourd’hui, ce terme est très souvent utilisé pour désigner un réseau de machines zombies, car l’IRC fut un des premiers moyens utilisés par des réseaux malveillants pour communiquer entre eux, en détournant l’usage premier de l’IRC. Le premier d’entre eux qui fut référencé a été W32/Pretty.worm2, appelé aussi PrettyPark, ciblant les environnements Windows 32 bits, et reprenant les idées d’Eggdrop et de GTbot. A l’époque, ils ne furent pas considérés comme très dangereux, et ce n’est qu’à partir de 2002 que plusieurs botnets malveillants (Agobot, SDBot puis SpyBot en 2003) firent parler d’eux et que la menace prit de l’ampleur.
Toute machine connectée à internet est susceptible d’être une cible pour devenir une machine zombie : des réseaux de botnets ont été découverts sur des machines Windows, Linux, mais également sur des Macintosh, voire consoles de jeu3 ou des routeurs4.
Usages principaux des botnets malveillants
La caractéristique principale des botnets est la mise en commun de plusieurs machines distinctes, parfois très nombreuses, ce qui rend l’activité souhaitée plus efficace (puisqu’on a la possibilité d’utiliser beaucoup de ressources) mais également plus difficile à stopper.
Usages des botnets
Les botnets malveillants servent principalement à :
- Relayer du spam pour du commerce illégal ou pour de la manipulation d’information (par exemple des cours de bourse) ;
- Réaliser des opérations de phishing ;
- Identifier et infecter d’autres machines par diffusion de virus et de programmes malveillants (malwares) ;
- Participer à des attaques groupées (DDoS)5 ;
- Générer de façon abusive des clics sur un lien publicitaire au sein d’une page web (fraude au clic) ;
- Capturer de l’information sur les machines compromises (vol puis revente d’information) ;
- Exploiter la puissance de calcul des machines ou effectuer des opérations de calcul distribué notamment pour cassage de mots de passe ;
- Servir à mener des opérations de commerce illicite en gérant l’accès à des sites de ventes de produits interdits ou de contrefaçons via des techniques de fast-flux, single ou double-flux ou RockPhish6 ;
- Miner de la cryptomonnaie ;
- Voler des sessions par credential stuffing.
Motivation des pirates
Motivation économique
L’aspect économique est primordial : la taille du botnet ainsi que la capacité d’être facilement contrôlé sont des éléments qui concourent à attirer l’activité criminelle, à la fois pour le propriétaire de botnet (parfois appelé « botherder » ou « botmaster ») que pour les utilisateurs, qui la plupart du temps louent les services d’un botnet pour l’accomplissement d’une tâche déterminée (envoi de pourriel, attaque informatique, déni de service5, vol d’information, etc). En avril 2009, un botnet de 1 900 000 machines7 mis au jour par la société Finjian engendrait un revenu estimé à {{formatnum:190000}} dollars par jour à ses « botmasters »8.
Motivation idéologique
En dehors de l’aspect économique, les attaques informatiques peuvent devenir une arme de propagande ou de rétorsion, notamment lors de conflits armés ou lors d’événements symboliques. Par exemple, lors du conflit entre la Russie et la Géorgie en 2008, le réseau géorgien a été attaqué sous de multiples formes (pour le rendre indisponible ou pour opérer à des défacements des sites officiels)9. En 2007, une attaque d’importance contre l’Estonie a également eu lieu10 : la motivation des pirates serait le déplacement d’un monument en hommage aux soldats russes du centre de la capitale estonienne11.
Motivation personnelle
La vengeance ou le chantage peuvent également faire partie des motivations des attaquants, sans forcément que l’aspect financier soit primordial : un employé mal payé12 ou des joueurs en ligne défaits3 peuvent chercher à se venger de l’employeur ou du vainqueur du jeu.
Architecture d’un botnet
Mode actuel de communication des botnets
Via canal un canal de commande et contrôle (C&C)
Via des canaux décentralisés
- P2P61413, pour ne plus dépendre d’un nœud central ;
- HTTP613 (parfois via des canaux cachés15), ce qui a pour principal avantage de ne plus exiger de connexion permanente comme pour les canaux IRC ou le P2P mais de se fondre dans le trafic web traditionnel ;
- Fonctions du Web 2.013, en faisant une simple recherche sur certains mots-clés afin d’identifier les ordres ou les centres de commandes auxquels le réseau doit se connecter16.
Cycle de vie
Un botnet comporte plusieurs phases de vie117. Une conception modulaire lui permet de gérer ces plusieurs phases avec une efficacité redoutable, surtout dès que la machine ciblée est compromise. La phase d’infection est bien évidemment toujours la première, mais l’enchaînement de ces phases n’est pas toujours linéaire, et dépendent de la conception du botnet.
Infection de la machine
C’est logiquement la phase initiale. La contamination passe souvent par l’installation d’un outil logiciel primaire, qui n’est pas forcément l’outil final. Cette contamination de la machine utilise les mécanismes classiques d’infection :
- Virus, qui peut prendre la forme de :
- Logiciel malveillant en pièce-jointe ;
- Cheval de Troie (fichier d’apparence anodine) ;
- Faille de navigateur ou de logiciel ;
- P2P où le code malveillant se fait passer pour un fichier valide.
- Combiné avec une action d’ingénierie sociale pour tromper l’utilisateur.
Activation
Une fois installée, cette base logicielle peut déclarer la machine à un centre de contrôle, qui la considèrera alors comme active. C’est une des clés du concept de botnet, à savoir que la machine infectée peut désormais être contrôlée à distance par une (ou plusieurs) machine tierce. Dans certains cas, d’autres phases sont nécessaires (auto-protection, mise-à-jour, etc) pour passer en phase opérationnelle.
Mise-à-jour
Une fois la machine infectée et l’activation réalisée, le botnet peut se mettre-à-jour, s’auto-modifier, ajouter des fonctionnalités, etc. Cela a des impacts importants sur la dangerosité du botnet, et sur la capacité des outils de lutte à enrayer celui-ci, car un botnet peut ainsi modifier sa signature virale et d’autres caractéristiques pouvant l’amener à être découvert et identifié.
Auto-protection
D’origine, ou après une phase de mise-à-jour, le botnet va chercher à s’octroyer les moyens de continuer son action ainsi que des moyens de dissimulation. Cela peut comporter :
- Installation de rootkits ;
- Modification du système (changement des règles de filtrage réseau, désactivation d’outils de sécurité, etc) ;
- Auto-modification (pour modifier sa signature) ;
- Exploitation de failles du système hôte, etc.
Propagation
La taille d’un botnet est à la fois gage d’efficacité et de valeur supplémentaire pour les commanditaires et les utilisateurs du botnet. Il est donc fréquent qu’après installation, la machine zombie va chercher à étendre le botnet :
- Par diffusion virale, souvent au cours d’une campagne de spam (liens web, logiciel malveillant en PJ, etc)
- Par scan :
- Pour exploiter des failles qu’il saura reconnaître ;
- Pour utiliser des backdoors connues ou déjà installées ;
- Par réaliser des attaques par force brute, etc.
Phase opérationnelle
Une fois installé, et déclaré, la machine zombie peut obéir aux ordres qui lui sont donnés pour accomplir les actions voulues par l’attaquant (avec, au besoin, installation d’outils complémentaires via une mise-à-jour distante) :
- Envoi de spam;
- Attaques réseau ;
- Participation au service de serveur DNS dynamique, ou DDNS (fast flux) ;
- Utilisation des ressources systèmes pour du calcul distribué (cassage de mot de passe), etc
Illustration d’un exemple de botnet
Voici le principe de fonctionnement d’un botnet servant à envoyer du pourriel :
- Le pirate tente de prendre le contrôle de machines distantes, par exemple avec un virus, en exploitant une faille ou en utilisant un cheval de Troie.
- Une fois infectées, les machines vont terminer l’installation ou prendre des ordres auprès d’un centre de commande, contrôlé par le pirate, qui prend donc ainsi la main par rebond sur les machines contaminées (qui deviennent des machines zombies).
- Une personne malveillante loue un service auprès du pirate.
- Le pirate envoie la commande aux machines infectées (ou poste un message à récupérer, selon le mode de communication utilisé). Celles-ci envoient alors des courriers électroniques en masse.
Taille des botnets
Il est extrêmement difficile d’avoir des chiffres fiables et précis, puisque la plupart des botnets ne peuvent être détectés qu’indirectement. Certains organismes comme shadowserver.org tentent d’établir des chiffres à partir de l’activité réseau, de la détection des centres de commandes (C&C), etc.
Nombre de réseaux (botnets)
Au mois de février 2010, on estimait qu’il existait entre {{formatnum:4000}} et {{formatnum:5000}} botnets actifs18. Ce chiffre est à considérer comme une fourchette basse, puisque les botnets gagnent en furtivité et que la surveillance de tout le réseau internet est impossible.
Taille d’un réseau
La taille d’un botnet varie mais il devient courant qu’un réseau puisse comprendre des milliers de machines zombies. En 2008, lors de la conférence RSA, le top 10 des réseaux comprenait de 10 000 à 315 000 machines, avec une capacité d’envoi de mail allant de 300 millions à 60 milliards par jour (pour Srizbi, le plus important botnet à cette date)1920.
En 2018, l’activité des botnets se concentrait sur deux grands réseaux : Necurs et Gatmut. Pour McAfee, ils sont à eux seuls responsables de 97 % du trafic des réseaux de robots (botnets) de spam21 au 4e trimestre 2018.
Nombre total de machines infectées
Dans son rapport de 2009, la société MessageLabs estime également que 5 millions de machines20 sont compromises dans un réseau de botnets destiné au spam.
Botnets de tous pays, unissez-vous !
La dernière mode dans le monde des botnets est de s »unir, car il est bien connu que l’union fait la force. La difficulté croissante pour effectuer des fraudes bancaires pousserait les criminels à combiner leurs forces22 afin de disposer de plusieurs méthodes de capture de données, ainsi que pour compromettre de façon plus efficace les cibles.
Lutte contre l’action des botnets
La constitution même d’un botnet, formé parfois de très nombreuses machines, rend la traçabilité des actions et des sources délicate. Plus le botnet est grand, plus il devient également difficile de l’enrayer et de l’arrêter puisqu’il faut à la fois stopper la propagation des agents activant le botnet et nettoyer les machines compromises.
Les anciennes générations s’appuyaient souvent sur un centre de contrôle centralisé ou facilement désactivable (adresse IP fixe pouvant être bannie, canal IRC pouvant être fermé, etc). Désormais, le pair à pair permet une résilience du système de communication, et les fonctions Web 2.0 détournées rendent l’interception très complexe : le botnet recherche un mot clé sur le web et l’utilise pour déterminer l’emplacement du centre de contrôle auprès duquel il doit recevoir ses ordres.
Détection
- Empreintes
- Observation du trafic
- Analyse de logs
Prévention
- Liste noires
- RBL
- DNSBL
- Mesures habituelles de protection du réseau (cloisonnement, restrictions, etc)
- Mesures habituelles de protection des machines (anti-virus, HIDS/HIPS, mot de passe, gestion des droits utilisateurs, anti-spam, gestion des mises-à-jour, etc)
Examples
L’évolution probable des botnets
BITB (Botnet In The Browser)
Les futurs botnets pourraient évoluer dans leur architecture avec l’arrivée d’HTML5 : les nouvelles fonctionnalités offertes par la nouvelle spécification HTML pourrait permettre de réaliser des botnets d’une nouvelle nature, à l’intérieur même d’un navigateur web (et non plus codé en dur et installé sur une machine)23.
Il est également fort probable de les voir continuer à exister, persistants en dépit de efforts réalisés pour les éradiquer (comme le botnet Satori)24 : ils exploiteront toute faille pouvant être exploitée à grande échelle, dans les réseaux traditionnels mais aussi les smartphones ou les objets connectés.
Les objets connectés
Merci à eux, objets si nombreux, et si peu sécurisés. On a trouvé traces d’objets connectés dans des botnets dès 201325, mais depuis 2016, ils ont commencé à représenter une véritable menace en raison de la facilité de leur prise de contrôle, alors que leurs capacités suffisaient pour construire une attaque réseau puissante, les attaques DDoS dont l’origine était un botnet d’objets connectés pouvant atteindre le Tb/s, c’est-à-dire la limite technique des structures d’absorption à la même époque. L’hébergeur OVH en a subi les conséquences et a communiqué26 sur le sujet afin d’alerter les spécialistes sur ce risque. En 2018, la chasse au botnet représentait toujours un travail conséquent27 pour l’hébergeur.
Conférences et action coordonnée
A vue de l’importance des dégâts des botnets, et de leur répartition autour du globe, une action coordonnée est souvent le seul moyen de diminuer significativement l’activité d’un botnet. Le sujet a également pris suffisamment d’ampleur et d’importance que des conférences sont dédiées à ce problème, telle que la BotConf qui existe depuis 2013.
Voir aussi
Articles connexes
Liens externes
- http://thehill.com/policy/cybersecurity/389917-dhs-commerce-release-cyber-report-on-combatting-botnets
- https://www.commerce.gov/page/report-president-enhancing-resilience-against-botnets
- Blog ESET, Nine bad botnets and the damage they did
- Shadowserver.org, organisme surveillant l’activité des botnets
- « L’Espagne démantèle le plus vaste réseau de PC fantômes », Le Figaro, 3 mars 2010
- https://securingtomorrow.mcafee.com/mcafee-labs/necurs-botnet-leads-the-world-in-sending-spam-traffic/
- http://www.zdnet.fr/actualites/un-botnet-inspire-de-mirai-vise-le-secteur-de-la-finance-39866582.htm
- http://thehill.com/policy/cybersecurity/389917-dhs-commerce-release-cyber-report-on-combatting-botnets