Site personnel de Jean GEBAROWSKI sur la sécurité des systèmes informatiques
Archives de catégorie : Concepts
La catégorie concepts regroupe les généralités utiles en sécurité des SI et parfois d’autres plus globales à l’informatique, mais ayant un sens ou un intérêt particuliers en SSI.
La récente salve de francisation de termes informatiques n’a pas fait que des heureux. Plusieurs voix se sont élevées contre l’institutionnalisation de fait de termes abscons, comme darkweb et deepweb dont l’existence même prête à polémique.
Autant un portail de messagerie (« webmail ») est un concept clair pour tous, autant les notions d’internet clandestin (« darkweb ») ou de toile profonde (« deepweb ») n’ont pas de réalité si tangible que ce qu’on veut bien nous faire croire.
Le cas des clandestins
Le Larousse nous apprend que clandestin peut signifier « qui se cache » mais aussi « qui contrevient à la loi ou qui se dérobe au contrôle ». Cela peut tout à fait s’appliquer à l’internet de Mme Michu, car nombre de sites web d’accès public contreviennent allègrement à plusieurs lois françaises : tel site d’un journal people qui reprend des clichés violant la vie privée de personnalités, tel autre qui diffuse de annonces liées à des escroqueries diverses (la bague qui guérit tout, le gain assuré au loto, l’augmentation de volume de [ce qu’on veut], la promesse de gains mirobolifiques sur des marchés financiers qu’on cache être extrêmement risqués), la vente d’armes sur Facebook ou Instagram, etc.
Par ailleurs, se dérober au contrôle est parfois une mesure salutaire notamment dans les pays (grands ou petits) où la censure sévit et où la clandestinité est la seule option permettant de vivre (ou survivre). Aller sur l’onionland ou utiliser des VPN est nécessaire à certains.
Sombre internet
D’après S. Bortzmeyer, la définition correcte de deepweb serait :
Concept débile, peu ou pas défini, flou, et qui ne sert qu’aux politiciens et journalistes sensationnalistes.
La définition officiellement retenue est :
Partie de la toile qui n’est pas accessible aux internautes au moyen des moteurs de recherche usuels.
Ce qui est sans aucun rapport avec la notion qu’on veut mettre dans ce deepweb peuplé uniquement de méchants qui se cachent pour comploter, car il y a un tas de raisons pour lesquelles les moteurs de recherche n’indexent pas : je prenais le cas d’un portail de messagerie, dont la quasi-totalité du contenu n’est accessible qu’à un utilisateur authentifié (et donc inaccessible aux moteurs de recherche). Ce portail de messagerie serait donc à classer dans le deepweb. Or consulter ce deepweb vous expose directement à l’excommunication ou à des poursuites pénales, bien entendu. Idem pour tous les sites utilisant un fichier robots.txt.
Deep ou dark ? Blanc ou noir ?
J’avoue moi-même ne plus bien réussir à faire la différence entre ces deux notions, tant elles sont floues. Une distinction plus simple et plus claire serait peut-être de parler d’activités légales ou d’activités illégales sur internet, quels que soient les moyens employés, puisqu’on peut vendre de la drogue sur l’internet « classique » et tenter de sauver sa famille sur l’internet « clandestin ». Toutefois, le darkweb désigne plus généralement :
Réseau accessible uniquement via des outils spécifiques, comme le navigateur Tor.
Après, Tor ou Freenet ne sont pas vraiment des réseaux séparés, puisqu’ils utilisent l’infrastructure d’internet. On parle de réseaux « overlays », qui se superposent sur des réseaux existants.
Internet n’est qu’une sorte de reflet des activités humaines : les truands se cachent, sauf parfois pour escroquer les gens ou faire leur business. Et les gens normaux sont parfois tentés d’être discrets pour de bonnes raisons. Le darkweb sera d’ailleurs peut-être la dernière solution pour tenter de garder un soupçon de vie privée.
The Dark Web Boundaries Are Not Always Clear, and Many Sites Fall in a Gray Area
GnuPG est un système de chiffrement (ou cryptosystème) indépendant des grands acteurs de la sécurité et de la surveillance (lesquels se confondent parfois). Il se base sur l’utilisation de clés de chiffrement asymétriques, ce qui permet de les échanger plus facilement.
Principes
A quoi ça sert un crypto-machin ?
Ça sert à masquer vos très chères données à nos très chers GAFA et autres acteurs du web et de l’internet. Accessoirement, Mme Michu ne pourra pas non plus lire ce que vous échangez avec vos correspondants.
En gros, vous créez une paire de clés de chiffrement qui vous seront associée à vous personnellement. Un des clés sera publique, l’autre sera privée ; elles vous permettront de chiffrer vos données ou vos mails. La clé publique pourra et devra être diffusée partout, et la clé privée devra rester secrète et donc, au contraire, être la plus cachée possible. Le gros inconvénient est que lorsqu’on perd sa clé privée, et bien c’est foutu, ça marche plus ! Il n’y a plus qu’à en recréer une, et diffuser la nouvelle clé auprès de vos correspondants, car il n’existe aucun moyen de la récupérer.
Comment ça s’installe ?
Sur les systèmes Linux, les outils nécessaires sont généralement installés par défaut. Après, le plus important est de stocker la clé privée en lieu sûr. La première opération à réaliser est la génération d’une paire de clés avec la commande --gen-key :
gpg --gen-key
On aura besoin durant cette procédure de disposer d’une quantité d’aléa (ou entropie) suffisante. Afin de voir l’entropie disponible sur un système Linux, on peut utiliser la commande suivante1 :
watch cat /proc/sys/kernel/random/entropy_avail
S’il vous en manque, il peut être judicieux d’utiliser le package rng-tools (sur Ubuntu).
apt-get install -y rng-tools
Pour générer un peu d’entropie supplémentaire, on peut utiliser la commande suivante :
/usr/sbin/rngd -r /dev/urandom
La seconde mesure consiste à générer un certificat de révocation pour toute une nouvelle paire de clés. La raison de procéder ainsi est qu’il vous faut disposer de la clé privée pour générer son certificat de révocation. Générer le certificat de révocation le plus tôt possible vous met à l’abri de l’oubli de votre clef. Vous devrez bien sûr conserver ce certificat à l’abri. En outre, il doit rester facile et rapide de révoquer une clé, en cas de compromission.
Comment ça marche pour chiffrer/déchiffrer ?
Pour chiffrer :
gpg -e destinataire [message]
Pour déchiffrer :
gpg [-d] [message]
Et pour signer ?
Pour signer et chiffrer un message, la syntaxe complète est :
On peut faire un chouïa plus simple, pour signer un message avec l’identité par défaut de votre trousseau de clé :
gpg --sign|--clearsign|--detach-sign [message]
L’option --sign vous construit un fichier .gpg illisible, --clearsign produit un fichier au format texte avec le contenu en clair suivi de la signature, et enfin --detach-sign ne fournit que la signature dans un fichier .sig. Ajoutez l’option --armor pour avoir un fichier signature en clair, suffixé par .asc. Si vous prenez l’option --clearsign, cela vous construira un fichier de type :
root@rasp-janiko:/jean/test# cat essai.txt.asc -----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 Ceci est un test. -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.4.12 (GNU/Linux) iQEcBAEBAgAGBQJV+WSgAAoJEN+s4kEe3i4xT6AH/RlkQZyQQ5XkdGmIQGgk8H6h C8zK7/RO1XzzP4xyqA59yHfgPgwGJ9PASaaUlOHgLcIbbiTRTrow8ZIPNhBdF4fC gEvZfu9p27X6SXXRa/94Lt1uIHDVFhtzWf9YNoytToxRSIf/CvPpTXcHPbnYP7YD Gwdz+Qxz8u2vhKJKLk4uXHgJb97IvsgoSfpb7e7TMMqCRIKV2S6T1LyouW+Tyy1Y ZerF5rGIWle2rYVQoM5ujuM77q/XaxAZyGQ7fp5rndBSVMBWptK5W9k8Ji4vhCqa FqhVdzTvq+DwmsjigCUtLk9uxSdqBhNQ+xb3sSRlyXG1PmnQtigXlUnUs/wBVds= =t6tc -----END PGP SIGNATURE-----
Pour vérifier la signature, il suffit de taper :
gpg --verify [message]
Si tout va bien, vous aurez :
root@rasp-janiko:/jean/test# gpg --verify essai.txt.asc gpg: Signature faite le mer. 16 sept. 2015 14:46:24 CEST avec la clef RSA d'identifiant 1EDE2E31 gpg: Bonne signature de « Jean GEBAROWSKI (statodynamicien) <jean@geba.fr> » </jean@geba.fr>
Et si la signature est mauvaise ou que le fichier est modifié :
root@rasp-janiko:/jean/test# gpg --verify essai.txt.asc gpg: Signature faite le mer. 16 sept. 2015 14:46:24 CEST avec la clef RSA d'identifiant 1EDE2E31 gpg: MAUVAISE signature de « Jean GEBAROWSKI (statodynamicien) <jean@geba.fr> » </jean@geba.fr>
Ce qu’il faut vérifier
Comme toujours, ça ne sert à rien d’utiliser des moyens sûrs si on ne vérifie pas leur validité. Quand on reçoit une alerte sur un certificat, il ne faut pas cliquer sur OK sans réfléchir. Pour les clés PGP, on a vu des tentatives d’usurpation reposant sur l’identifiant court (ou short id), qui peut parfois être dupliqué ! Donc en utilisant et/ou important des clés, il ne faut pas de limiter à cet identifiant mais aussi vérifier l’adresse mail23…
Où vérifier ?
Le réseau SKS Keyserver (Synchronizing Key Server) a été historiquement le principal système de distribution des clés publiques. Le réseau SKS est en déclin (relatif) car il est vulnérable à des attaques comme l’empoisonnement de clés (« key poisoning »). On a, par exemple :
Une faille a été découverte en mai 20184 dans de nombreux outils de messagerie ou dans leurs plugins mettant en oeuvre PGP et S/MIME. Il s’agirait plus d’une mauvaise implémentation de ces protocoles dans les clients de messagerie que d’autre chose, mais le résultat est le même : il y a danger, même sil l’exploitation n’est pas triviale5.
Le seul conseil pour l’instant est de désactiver le déchiffrement automatique des messages dans les clients de messagerie concernés (tels que Outlook, Thunderbird, Apple Mail, etc.) en supprimant les clés qui y sont stockés, et de désactiver l’affichage HTML. Le déchiffrement ne doit être effectué que dans une application tierce, jusqu’à production du correctif.
Une autre faille a été mise au jour en juin 20186 permettant d’usurper n’importe quelle signature, ce qui est gênant. La version 2.2.8 de GnuPG corrige le tir de cette anomalie qui existait depuis très longtemps, apparemment !
La confiance n’exclut pas le contrôle, dit-on souvent. Il existe d’excellents outils pour évaluer la sécurité et la robustesse d’un serveur proposant une communication SSL.
Pour ma part, je recommande SSLScan, dont il existe plusieurs variantes. En fouillant un peu, celle qui me semble la plus pertinente est celle de rbsec, car elle est à peu près à jour (elle intègre les versions 1.1 et 1.2 de TLS), et ne mixe pas les technologies puisqu’il s’agit uniquement d’un programme en langage C. Ca permet d’éviter de trop nombreuses dépendances, et ça évite de cumuler les vulnérabilités de multiples technologies (bien que cet aspect puisse être débattu).
Kubernetes, ou k8s pour les intimes, est un orchestrateur. On pourrait dire parmi tant d’autres, vus qu’ils fleurissent pour nous aider à tout faire, mais pas tant que ça : il tend de facto à devenir un standard, ou tout du moins l’outil le plus utilisé dans son genre.
La cryptologie est la science de l’écriture secrète, comprenant la cryptographie (technique de chiffrement de message) et la cryptanalyse (technique de déchiffrement d’un message).
Heartbleed est le nom donné à une faille dans une implémentation d’openSSL.
OpenSSL : c’est quoi ?
Avant toute chose, il faut savoir que SSL (dont les versions récentes s’appellent TLS) est un protocole qui permet de chiffrer des communications sur internet et d’authentifier une machine (un serveur web par exemple). Chiffrer, c’est rendre illisible un message à tous ceux qui ne disposent pas de la clé de déchiffrement. Ce protocole est très utilisé sur internet, et openSSL est un des outils d’implémentation de SSL parmi les plus utilisés.
Quand vous vous connectez de manière sécurisée sur un site web, vous passez par https et plus de la moitié de serveurs web dans le monde utilisent openSSL pour réaliser cette connexion https.
Quelle est la faille ?
La faille permettrait à un attaquant d’avoir accès à certaines données chiffrées lors des communications SSL sur les sites utilisant les versions vulnérables. En conséquence, certains mots de passe (voire certains certificats) pourraient être compromis et donc réutilisés par l’attaquant.
Quel est le composant touché ?
La faille est exploitable quand une version vulnérable d’openSSL est installée sur le serveur web. OpenSSL est un logiciel open source. Seules certaines versions sont vulnérables :
La branche 0.9.8 n’est pas touchée, et la correction est présente à partir de la version 1.0.1g.
Un mois à peine après l’entrée en vigueur du Règlement Général sur la Protection des Données (RGPD en français, GDPR en anglais), voilà qu’arrive une première action concernant la collecte de données biométriques, en l’occurrence vocales1. Cela me réjouit vu ma position sur la biométrie, bien que je pense que cela n’aboutira à pas grand-chose.
Le contexte
Le service des impôts du Royaume-Uni (Majesty’s Revenue and Customs ou HMRC) s’est mis en tête d’utiliser la biométrie vocale (donc de type intermédiaire) pour authentifier les personnes appelant leurs services. Fluidifier le parcours utilisateur est souvent une très bonne idée, et la biométrie de ce point de vue y concourt assez bien.
Sauf que
Si le confort d’utilisation est au rendez-vous, les questions quant à l’utilisation de la biométrie sont légitimes. Il me semble reconnaître la solution dont il est question (il s’agit de la solution développée par Nuance23, que j’ai pu tester il y a quelques années pour mon employeur, avec leur célèbre sésame « ma voix est mon mot de passe ») et si Nuance respecte de bonnes pratiques en la matière, cela ne dédouane pas le responsable du traitement (le HMRC) de respecter les droits énoncés par le RGPD, notamment :
Le droit à l’effacement des données
L’obligation de recueillir de façon simple le consentement des utilisateurs pour l’usage de leurs données personnelles.
Les éléments biométriques font bien sûr partie des données personnelles, et il semble que le HMRC pousse un peu trop ses utilisateurs à utiliser la biométrie vocale, et que l’opacité entoure à la fois l’usage précis des données (qu’est-ce qui est utilisé, qu’est-ce qui est conservé et comment) et la possibilité de faire supprimer ses données.
Pourquoi ça n’aboutira pas
Parce que je vois mal le HMRC ne pas se mettre en conformité, même à contre-cœur. Il suffirait d’améliorer le processus de collecte, et de mieux gérer la suppression, en indiquant clairement comment procéder.
Pourquoi c’est important quand même
Cela prouve que ce n’est pas parce que ça plaît à plein de monde que la solution est bonne, ou qu’elle ne soulève pas d’inquiétudes chez d’autres personnes. Par exemple, comment savoir si des échantillons vocaux n’ont pas été conservés, ou pire transmis à d’autres entités ? Même s’il est peu probable que ça soit le cas, cette affaire montre que des citoyens sont inquiets sur l’usage de ces données.
La biométrie vocale demande de recueillir (au moins temporairement) des échantillons, pour former un modèle ou plus précisément un gabarit (au sens biométrique) caractérisant l’utilisateur, un peu comme un hash.
En France, recueillir une base biométrique centralisée, même si elle n’est constituée que de gabarits (et non d’échantillons) exige l’accord de la CNIL. On ne fait donc pas n’importe quoi avec ce type de données.
En sécurité informatique, il y a des vérités qu’on retrouve régulièrement et qu’on peut généraliser facilement. Microsoft en a énoncé une dizaine, très intéressantes, et sans être totalement absolues, indiscutables, ou complètes, elles contiennent de très nombreux points de repères et principes valables indépendamment de toute technologie.
Si un méchant peut vous convaincre de faire tourner son programme sur votre ordinateur, alors ce n’est plus tout à fait votre ordinateur.
Si un méchant peut modifier le système d’exploitation de votre ordinateur, alors ce n’est plus tout à fait votre ordinateur.
Si un méchant peut accéder physiquement à votre ordinateur, alors ce n’est plus tout à fait votre ordinateur.
Si un méchant peut exécuter du contenu actif sur votre site web, alors ce n’est plus tout à fait votre site web.
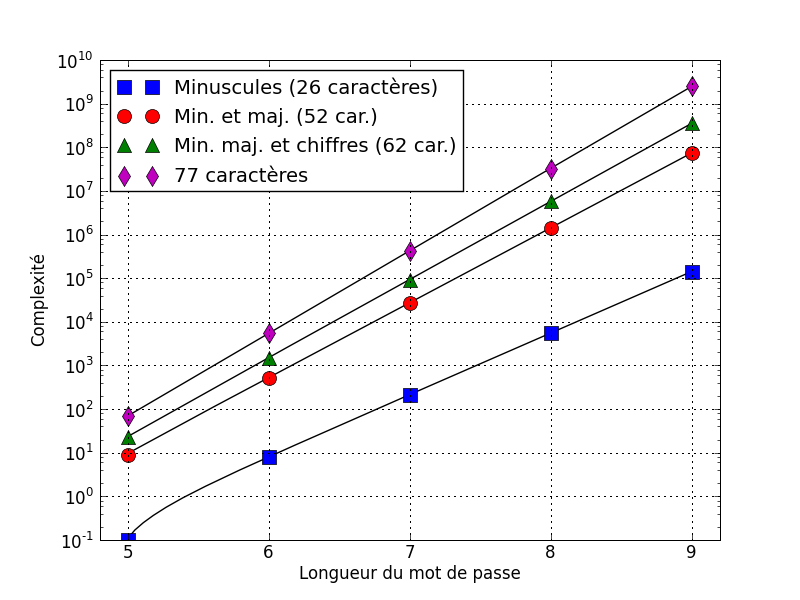
Les mots de passe faibles l’emportent sur la sécurité.
Un ordinateur n’est sécurisé qu’autant que son administrateur est digne de confiance.
La sécurité de données chiffrées est la même que celle de la clé de chiffrement.
Un anti-malwares (anti-virus) non mis à jour n’est que légèrement plus efficace que de ne rien faire.
L’anonymat absolu est inatteignable en pratique, en ligne ou hors ligne.
La technologie n’est pas la panacée.
Au sujet de la loi #10, Bruce Schneier dit même :
If you think technology can solve your security problems, then you don’t understand the problems and you don’t understand the technology.
Version originale, en anglais, sur le site de Microsoft :
If a bad guy can persuade you to run his program on your computer, it’s not solely your computer anymore.
If a bad guy can alter the operating system on your computer, it’s not your computer anymore.
If a bad guy has unrestricted physical access to your computer, it’s not your computer anymore.
If you allow a bad guy to run active content in your website, it’s not your website any more.
Weak passwords trump strong security.
A computer is only as secure as the administrator is trustworthy.
Encrypted data is only as secure as its decryption key.
An out-of-date antimalware scanner is only marginally better than no scanner at all.
Absolute anonymity isn’t practically achievable, online or offline.
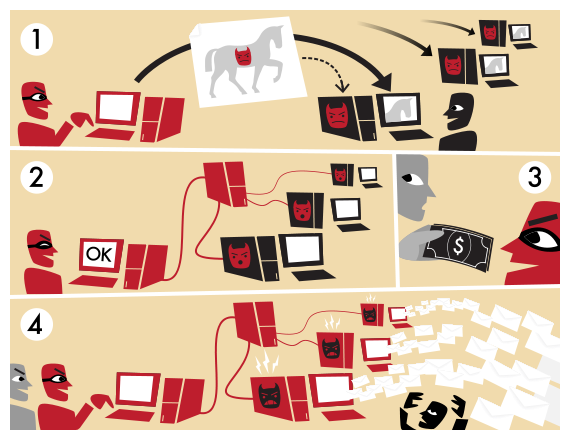
Une page spéciale est consacrée au phishing (ou en français « hameçonnage », mais c’est pas très joli). Il s’agit d’une menace classique mais très répandue.
Il s’agit d’un procédé dont le but est de vous faire avouer vos codes secrets (mot de passe) ou vos coordonnées bancaires en se faisant passer pour un mail officiel.
Principe
On vous envoie un mail qui imite ceux de l’organisme visé (une banque ou un site marchand en général) qui vous incite à resaisir vos mots de passe, sous un (fallacieux) prétexte de mise-à-jour de sécurité ou n’importe quoi d’autre. Pour cela, le mail contient un lien web sur lequel vous devez cliquer pour resaisir votre mot de passe. Or ce lien web vous envoie vers un faux site lui aussi semblable au site officiel, mais ce faux site n’a d’autre but que de stocker vos codes secrets…
Soyez extrêment vigilants !
Quelques indices doivent vous mettre la puce à l’oreille…
Le message n’est pas en français ou est dans un français approximatif : les organismes officiels et les banques français communiquent souvent en français et le texte est souvent lu, relu et vérifié… Le message vous incite à ressaisir votre mot de passe : à ma connaissance, aucune application informatique sérieuse n’a besoin qu’on ressaisisse des données (surtout un mot de passe !) suite à une mise-à-jour ni même suite à un piratage… Il n’y a que pour des petits sites web amateurs ou des informaticiens de (très) bas étage que des données sont perdues. Sinon les sauvegardes et les procédures sérieuses de test empêchent ce genre de problème. Le lien proposé ne correspond pas à ce qui est affiché : on vous affiche un lien avec un texte qui semble sérieux, mais en passant la souris par dessus, on peut voir l’adresse réelle vers où le lien vous dirige, en regardant en bas de votre navigateur.
Qu’est-ce qu’un « faux » lien web ?
Ça n’est pas à proprement parler un faux lien, c’est juste que naturellement on a tendance à croire ce qu’on voit. Il est également habituel sur les sites web que le texte affiché corresponde au lien vers lequel on est redirigé.
Passez votre souris par dessus le texte, et regardez en bas de votre navigateur : vous allez voir (tout en bas) l’adresse vers laquelle vous êtes redirigé. J’ai écrit cette page web de manière à ce que le texte de la page et l’adresse du lien soient les mêmes.
Mais tout ceci n’est pas obligatoire : rien n’empêche d’afficher un texte qui ne soit pas l’adresse du site mais un texte en clair…
Mais là où ça devient dangereux c’est quand des petits malins affichent un texte qui semble être une adresse web et qu’ils vous redirigent vers une autre adresse ! Ils jouent sur notre habitude que le lien web correspond très souvent au texte affiché. Rien de plus… Ci-dessous, vous avez un exemple qui vous permet de mettre ce que vous voulez comme texte. Et vous verrez que vous ne serez pas du tout dirigé vers le site que vous afficherez…
Une autre forme de filoutage, plus perverse : l’homographie. Ici, l’adresse semble correcte, visuellement, mais ce n’est qu’une apparence trompeuse, jouant sur la diversité des alphabets mondiaux et leur représentation graphique, parfois équivoque.
Les parades
Le bon sens
Taper soi-même l’url
L’évolution
Les attaques informatiques ciblent de plus en plus les utilisateurs, puisque les infrastructures sont de plus en plus sécurisées : il devient donc difficile d’attaquer directement les machines, donc on passe par l’utilisateur qui est faillible, et dont le niveau de vigilance ne peut être constant.
Il faut s’attendre (cf. tendances 2020) à ce que les mails soient de mieux en mieux écrits, comme dans le cas d’une attaque contre les Nations Unies1 début 2020.
Un rootkit (en français : « outil de dissimulation d’activité »1) est un type de programme (ou d’ensemble de programmes ou d’objets exécutables) dont le but est d’obtenir et de maintenir un accès frauduleux (ou non autorisé) aux ressources d’une machine, de la manière la plus furtive et indétectable possible.
Le terme peut désigner à la fois la technique de dissimulation ou son implémentation (c’est-à-dire un ensemble particulier d’objets informatiques mettant en œuvre cette technique).
Historique
Le phénomène n’est pas nouveau : des programmes manipulant les logs système, tout en se dissimulant des commandes donnant des informations sur les utilisateurs (telles que who, w, ou last), sont apparus en 1989{{Lien web | url = http://www.sans.org/reading_room/whitepapers/honors/linux_kernel_rootkits_protecting_the_systems_1500?show=1500.php&cat=honors | titre = Linux kernel rootkits: protecting the system’s « Ring-Zero » | date = mars 2004 | éditeur = SANS Institute }} ; les premiers rootkits sur Linux et Solaris ont été rencontrés au début des années 19902 et ont été répertoriés en tant que tels en octobre 1994. Le projet chkrootkit, dédié au développement d’un outil de détection de rootkits pour les plateformes Solaris et HP-UX, a été démarré en 1997.
Il existe des rootkits pour la plupart des systèmes d’exploitation. En 2002, Securityfocus constatait déjà des évolutions et des progrès en matière de rootkit pour les plate-formes Windows. Un des premiers rootkits pour Mac OS X (WeaponX) est apparu en novembre 20043.
Certains rootkits peuvent être légitimes, pour permettre aux administrateurs de reprendre le contrôle d’une machine défaillante, pour suivre un ordinateur ayant été volé4, ou dans des outils comme Daemon Tools ou Alcohol 120%5. Mais aujourd’hui le terme n’évoque quasiment plus que des outils à finalité malveillante.
Mode opératoire
Contamination
La première phase d’action d’un rootkit consiste à chercher un accès au système, sans forcément que celui-ci soit un accès privilégié (ou en mode administrateur). La contamination d’un système peut avoir lieu de différentes façons, en utilisant les techniques habituelles des programmes malveillants. Les moyens les plus courants sont :
utilisation des techniques virales : un rootkit n’est pas un virus à proprement parler, mais il peut se transmettre par les techniques utilisées par les virus, notamment par un [[Cheval_de_Troie_(informatique)|cheval de Troie]]. Un virus peut avoir pour objet de répandre des rootkits sur les machines infectées (a contrario, un virus peut aussi utiliser les techniques de rootkits pour parfaire sa dissimulation) ;
mise en œuvre d’un [[Exploit_(informatique)|exploit]], c’est-à-dire l’exploitation d’une vulnérabilité de sécurité, à n’importe quel niveau du système : application, système d’exploitation, BIOS, etc. Cette mise en œuvre peut être le fait d’un virus, mais elle résulte aussi souvent de botnets qui réalisent des scans de machines pour identifier les failles et exploiter celles qui sont utiles à l’attaque ;
attaque par force brute, afin de profiter de la faiblesse des mots de passe de certains utilisateurs, et obtenir ainsi un accès au système.
Modification du système et dissimulation
Une fois la contamination effectuée et l’accès obtenu, la phase suivante du mode opératoire consiste en l’installation de l’ensemble des objets et outils nécessaires au rootkit. Il s’agit des objets permettant la mise en place de la charge utile du rootkit, s’ils n’ont pas pu être installés durant la phase de contamination, ainsi que les outils et les modifications nécessaires à la dissimulation.
Mise en place de la charge utile
Un [[botnet
permet d’avoir un accès sur des centaines de machines.]]
La charge utile est la partie active du rootkit (et de tout programme malveillant en général), dont le rôle est d’accomplir la (ou les) tâche(s) assignée au système. La charge utile permet d’avoir accès aux ressources de la machine infectée, et notamment :
CPU, pour décoder des mots de passe ou plus généralement pour effectuer des calculs distribués à des fins malveillantes ;
serveur de messagerie, pour envoyer des mails (pourriel ou spam) en quantité ;
ressources réseaux, pour servir de base de lancement pour des attaques diverses (déni de service, exploits) ou pour snifferl’activité réseau ;
pilotes de périphériques, pour installer des enregistreurs de frappe ou keyloggers (par exemple) ;
prise de contrôle total de la machine (par exemple en remplaçant le procédé de connexion, comme /bin/login sous Linux).
Certains rootkits sont utilisés pour l’exploitation de botnets, la machine infectée devenant alors une machine zombie, comme par exemple pour le botnet Srizbi6.
Dissimulation
Le rootkit cherchera également à « dissimuler » son activité. Ce procédé de dissimulation permet évidemment de minimiser le risque de découverte du rootkit, afin de profiter le plus longtemps possible de l’accès frauduleux. Une des caractéristiques principales d’un rootkit est donc sa faculté à se dissimuler, alors qu’un virus cherche principalement à se répandre, ces deux fonctions étant parfois jumelées pour une efficacité supérieure. Selon les cas, plusieurs méthodes peuvent être employées et combinées :
en ouvrant des portes dérobées, afin de pérenniser l’accès au système et permettre le contrôle de la machine, l’installation de la charge utile, etc27 ;
en cachant des processus informatiques ou des fichiers ; sous Windows, une technique consiste à modifier certaines clés de la base de registre ; sous Linux, on peut par exemple modifier les fichiers /usr/include/proc.h (processus à masquer) ou /usr/include/file.h (fichiers à masquer) ;
en remplaçant certains exécutables ou certaines librairies par des programmes malveillants et des chevaux de Troie, contrôlables à distance ;
en obtenant des droits supérieurs (par élévation des privilèges), afin de désactiver les mécanismes de défense ou pour agir sur des objets de haut niveau de privilèges ;
en utilisant des techniques de type « {{lang|en|Stealth by Design}} » (littéralement « furtif par conception »)8, à savoir implémenter à l’intérieur du rootkit des fonctions système afin de ne pas avoir à appeler les fonctions standards du système d’exploitation et ainsi éviter l’enregistrement d’événements système suspects ;
en détournant certains appels aux tables de travail utilisées par le système{{pdf}} {{Lien web |url=http://www.security-labs.org/fred/docs/sstic07-rk-article.pdf|titre=De l’invisibilité des rootkits : application sous Linux|auteur=E. Lacombe, F. Raynal, V. Nicomette|éditeur=CNRS-LAAS/Sogeti ESEC}} par [[Hook (informatique)|hooking]] ;
en effaçant physiquement toute trace d’activité, notamment dans les journaux de logs système, etc.
Niveau de privilège
Bien que le terme a souvent désigné des outils ayant la faculté à obtenir un niveau de privilège de type administrateur (utilisateur root) sur les systèmes Unix et Linux, un rootkit ne cherche pas obligatoirement à obtenir un tel accès sur une machine (par [[Élévation_des_privilèges|élévation de privilège]]), et ne nécessite pas non plus d’accès administrateur pour s’installer, fonctionner et se dissimuler9. Le programme malveillant Haxdoor10, même s’il était un rootkit du type noyau11 pour parfaire sa dissimulation, écoutait les communications sous Windows en mode utilisateur12 afin de tenter de capturer des identifiants avant cryptage, en interceptant les API de haut niveau.
Cependant, l'[[Élévation_des_privilèges|élévation de privilège]] est souvent nécessaire pour que le camouflage soit efficace : le rootkit peut utiliser certains [[Exploit_(informatique)|exploits]] afin de parfaire sa dissimulation en opérant à un niveau de privilège très élevé, pour atteindre des bibliothèques du système, des éléments du noyau, pour désactiver les défenses du système, etc.
Types
Il existe cinq types principaux de rootkits selon leur cible : les kits de niveau micrologiciel, hyperviseur, noyau, bibliothèque et applicatif.
Niveau micrologiciel/hardware
Il est possible d’installer des rootkits directement au niveau du micrologiciel (ou {{lang|en|firmware}}). De nombreux produits proposent désormais des mémoires flash, ce qui peut être utilisé pour implanter durablement du code13, en détournant par exemple l’usage d’un module de persistance souvent implanté dans le BIOS de certains systèmes.
Un outil légitime utilise d’ailleurs cette technique : LoJack, d’AbsolutSoftware4, qu’on trouve sur des ordinateurs portables car il permet ainsi de suivre un ordinateur à l’insu de l’utilisateur (en cas de vol). Ce code peut « survivre » à un changement de disque dur voire à un flashage du BIOS14 si le module de persistance est présent et actif. Tout périphérique disposant d’un tel type de mémoire est donc potentiellement vulnérable.
Une piste évoquée pour contrer ce genre de rootkit serait d’interdire l’écriture du BIOS (grâce à un cavalier sur la carte-mère ou par l’emploi d’un mot de passe) ou d’utiliser des EFI à la place du BIOS15, mais cette méthode reste à tester et à confirmer16.
Niveau hyperviseur
Ce type de rootkit se comporte comme un hyperviseur classique (de niveau 1) : après s’être installé et avoir modifié la séquence de démarrage, pour être lancé en tant qu’hyperviseur de la machine infectée au démarrage. Le système d’exploitation original se retrouve alors être un hôte (invité) du rootkit, lequel peut alors intercepter tout appel matériel. Il devient quasiment impossible à détecter depuis le système original.
Une étude conjointe de chercheurs de l’université du Michigan et de Microsoft ont démontré la possibilité d’un tel type de rootkit, qu’ils ont baptisé « {{lang|en|virtual-machine based rootkit}} » (VMBR)17. Ils ont pu l’installer sur un système Windows XP et sur un système Linux. Les parades proposées sont la sécurisation du boot, le démarrage à partir d’un média vérifié et contrôlé (réseau, CD-ROM, clé USB, etc) ou l’emploi d’un moniteur de machine virtuelle sécurisé.
Niveau noyau
Certains rootkits arrivent à s’implanter dans les couches du noyau du système d’exploitation soit dans le noyau lui-même, soit dans des objets exécutés avec un niveau de privilèges équivalent au système, ce qui est le cas pour certains pilotes de périphériques.
Sous Linux, il s’agit souvent de modules pouvant être chargés au niveau du noyau (modules de noyau chargeables, ou {{lang|en|loadable kernel modules}}), sous Windows de pilotes informatiques. Avec un tel niveau de privilèges, la détection et l’éradication du rootkit n’est souvent possible que de manière externe au système en redémarrant (en bootant) depuis un système sain, installé sur CD, sur une clé USB ou par réseau.
Ce type de rootkit est dangereux à la fois parce qu’il a acquis des privilèges élevés (il est alors plus facile de leurrer un logiciel de protection), mais aussi par les instabilités qu’il peut causer sur le système infecté comme cela a été le cas lors de la correction de la vulnérabilité MS10-01518, où des [[Écran_bleu_de_la_mort|écrans bleus]] sont apparus en raison d’un conflit entre cette correction et le fonctionnement du rootkit Alureon19.
Niveau bibliothèque
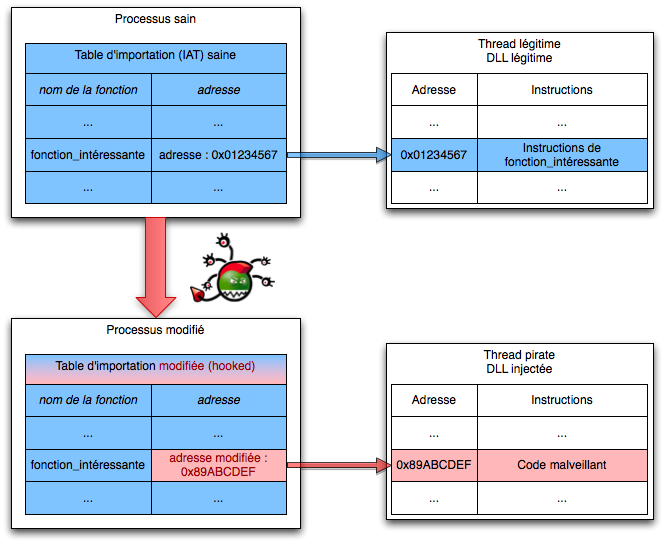
À ce niveau, le rootkit détourne l’utilisation de bibliothèques légitimes du système d’exploitation. Plusieurs techniques peuvent être utilisées :
en patchant un objet d’une bibliothèque, c’est-à-dire en ajoutant du code à l’objet en question ;
en détournant l’appel d’un objet (« hooking »), ce qui revient à appeler une autre fonction puis à revenir à la fonction initiale ;
en remplaçant des appels système par une version spécifique, ce qui correspond à remplacer l’appel système initial par du code malveillant.
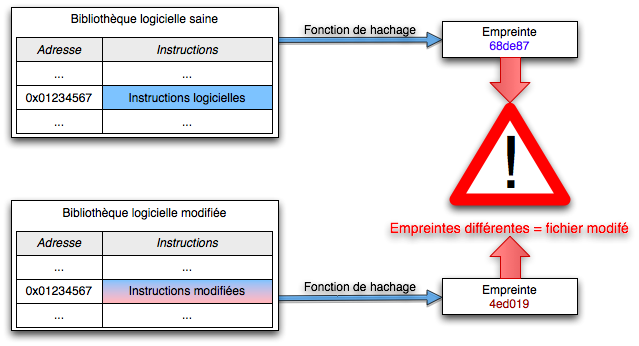
Ce type de rootkit est assez fréquent, mais il est aussi le plus facile à contrer, notamment par un contrôle d’intégrité des fichiers essentiels en surveillant leur empreinte grâce à une fonction de hachage, par détection de signature du programme malveillant, ou par exemple par examen des {{lang|en|hooks}} par des outils comme unhide sous Linux ou HijackThis sous Windows.
Niveau applicatif
Un rootkit applicatif implante des programmes malveillants de type [[Cheval_de_Troie_(informatique)|cheval de Troie]], au niveau utilisateur. Ces programmes prennent la place de programmes légitimes ou en modifient le comportement, afin de prendre le contrôle des ressources accessibles par ces programmes.
Exemples
Rootkits Sony
À deux reprises, Sony a été confronté à la présence masquée de rootkits dans ses produits : dans ses clés usb biométriques20 et dans son composant de gestion numérique des droits (DRM)2122 présent notamment sur ses CD audio. Ce rootkit possède lui-même des failles qui peuvent être exploitées.
Ces affaires ont fait un tort important à Sony, aussi bien pour sa respectabilité que financièrement. Dans plusieurs pays, Sony a été poursuivi en justice et obligé de reprendre les CD contenant un rootkit et de dédommager les clients23.
Voir aussi : [[:en:Sony BMG CD copy protection scandal|Sony BMG CD copy protection scandal]].
Exploitation de la vulnérabilité de LPRng
Le CERTA (Centre d’Expertise Gouvernemental de Réponse et de Traitement des Attaques informatiques) a publié, dans une note d’information, l’analyse d’une attaque ayant permis d’installer un rootkit (non identifié), n’utilisant à l’origine qu’une seule faille (répertoriée CERTA-2000-AVI-08724) qui aurait pu être stoppée soit par la mise-à-jour du système, soit par le blocage d’un port spécifique grâce à un pare-feu25.
Cette attaque a été menée en moins de deux minutes. L’attaquant a identifié la vulnérabilité, puis envoyé une requête spécialement formée sur le port 515 (qui était le port exposé de cette vulnérabilité) pour permettre l’exécution d’un code arbitraire à distance. Ce code, nommé « SEClpd », a permis d’ouvrir un port en écoute (tcp/3879) sur lequel le pirate est venu se connecter pour déposer une archive (nommée rk.tgz, qui contenait un rootkit) avant de la décompresser et de lancer le script d’installation.
Ce script a fermé certains services, installé des [[Cheval_de_Troie_(informatique)|chevaux de Troie]], caché des processus, envoyé un fichier contenant les mots de passe du système par mail, et il a même été jusqu’à corriger la faille qui a été exploitée, afin qu’un autre pirate ne vienne pas prendre le contrôle de la machine.
Prévention
Moyens de détection
La mise en œuvre de la détection peut parfois demander un examen du système ou d’un périphérique suspect en mode « inactif » (démarrage à partir d’un système de secours ou d’un système réputé sain), selon le type de rootkit. Les moyens de détection peuvent être :
Le calcul régulier des empreintes de fichiers sensibles permet de détecter une modification inattendue.
contrôle de l’intégrité des fichiers : on cherche à détecter toutes modifications des fichiers sensibles (bibliothèques, commandes systèmes, etc)8 en vérifiant régulièrement leur intégrité, en calculant pour chacun d’eux leur empreinte : toute modification inattendue de cette somme indiquera une modification du fichier et une contamination potentielle. Cela demande cependant une analyse car tout système subit aussi des modifications légitimes (comme lors des mises-à-jour du système) ; idéalement, l’outil de contrôle aura la possibilité d’accéder à une base de référence de ces sommes de contrôles, qui variera donc en fonction du système et des versions utilisées (comme rkhunter, par exemple) ;
détection de leur signature spécifique : il s’agit du procédé classique d’analyse de signature, comme cela se fait pour les virus. On cherche à retrouver dans le système la trace d’une infection, soit directement (signature des objets du rootkit), soit par le vecteur d’infection (virus utilisé par le rootkit)8 ;
Le hooking consiste à détourner un appel de fonction légitime par un autre qui contient du code malveillant.
analyse des appels systèmes : cette technique consiste à analyser la table des appels système, les tables d’interruption (ou Interrupt Descriptor Table)2627 et de manière générale les tables de travail utilisées par le système par des outils comme HijackThis qui permettent de voir si ces appels sont détournés ou non, par exemple en comparant ce qui est chargé en mémoire avec les données brutes de bas niveau (ce qui est écrit sur le disque) ;
analyse des flux réseau anormaux : cette analyse28 permet de détecter une surcharge ou une utilisation de ports logiciels inhabituels qui peut être observée à partir de la contamination de la machine, grâce aux traces issues d’un pare-feu ou grâce à un outil spécialisé. Il est également possible de faire une recherche des ports logiciels ouverts et de la comparer à ce que connaît le système, avec des outils d’investigation comme unhide-tcp. Toute différence peut être considérée comme anormale. Il existe cependant des moyens de dissimulation réseau, comme de la stéganographie ou l’utilisation de canaux cachés, qui rend la détection directe impossible, et seule une analyse statistique peut éventuellement répondre à cette difficulté29 ;
analyse des logs système : ce type d’analyse30 automatisée s’appuie sur le principe de corrélation, avec des outils de type HIDS qui disposent de règles paramétrables31 pour distinguer les événements anormaux et mettre en relation des événements systèmes distincts, sans rapport apparent ou différés dans le temps ;
analyse de la charge système : une surveillance continue peut mettre en évidence un surcharge, à partir de la contamination de la machine. Il s’agit essentiellement d’une analyse statistique de la charge habituelle d’une machine, comme le nombre de mails sortants ou la charge CPU. Toute modification (en surcharge) sans cause apparente est suspecte, mais cela demandera une analyse complémentaire pour écarter toute cause légitime (mise-à-jour du système, installation de logiciels, etc).
recherche d’objets cachés, tels que des processus informatiques, des clés de registre, des fichiers, etc. Des outils comme unhide sous Linux réalisent cette tâche pour les processus. Sous Windows, des outils comme RootkitRevealer recherchent les fichiers cachés en listant les fichiers via l’API normale de Windows puis en comparant cette liste à une lecture physique du disque ; tout fichier caché (à l’exception des fichiers légitimes connus de Windows, tels que les fichiers métadata de NTFS comme $MFT ou $Secure) est alors suspect32.
Moyens de protection et de prévention
Les moyens de détection peuvent également servir à la prévention, même si celle-ci sera toujours postérieure à la contamination. D’autres mesures en amont peuvent limiter l’installation d’un rootkit33 :
correction des failles par mise-à-jour de l’OS : cela permet de réduire la surface d’exposition du système en éliminant le temps où une faille est présente sur le système34 et dans les applications30, afin de prévenir les [[Exploit_(informatique)|exploits]] pouvant être utilisés pour la contamination ;
utilisation d’un pare-feu : cela fait partie des bonnes pratiques dans le domaine de la sécurité informatique, et se révèle efficace dans le cas des rootkits273034 car cela empêche des communications inattendues (téléchargements de logiciel, dialogue avec un centre de contrôle et de commande d’un botnet, etc.) dont ont besoin les rootkits ;
utilisation d’outil de prévention de type HIPS : ces outils30, de type logiciel ou appliance, répondent dès qu’une alerte est suspectée, en bloquant des ports ou en interdisant la communication avec une source (adresse IP) douteuse, ou toute autre action appropriée. La détection sera d’autant meilleure que l’outil utilisé sera externe au système examiné, puisque certains rootkit peuvent atteindre des parties de très bas niveau dans le système, jusqu’au BIOS même. Un des avantages de ces outils est l’automatisation des tâches de surveillance8 ;
contrôle d’intégrité des fichiers : des outils spécialisés existent pour remplir cette tâche, et peuvent produire des alertes lors de modifications inattendues. Cependant, ce contrôle à lui seul seul est insuffisant si d’autres mesures préventives ne sont pas mises en œuvre, si aucune réponse du système n’est déclenchée, ou si ces différences ne sont pas analysées. Les HIPS/HIDS, ainsi que certains outils anti-rootkits comme rkhunter peuvent interpréter ces contrôles via une base de sommes de contrôle (pour des versions connues de systèmes d’exploitation) ou par corrélation ;
attaque par force brute
.]]
renforcement de la robustesse des mots de passe : il s’agit là encore d’une des bonnes pratiques de sécurité informatique, qui éliminera une des sources principales de contamination. Des éléments d’authentification triviaux sont des portes ouvertes pour tous type d’attaque informatique ;
démarrage du système à partir d’une image saine : le démarrage à partir d’une image saine, contrôlée et réputée valide du système d’exploitation, via un support fixe (comme un LiveCD, une clé USB) ou par réseau, permet de s’assurer que les éléments logiciels principaux du système ne sont pas compromis, puisqu’à chaque redémarrage de la machine concernée, une version valide de ces objets est chargée. Un système corrompu serait donc remis en état au redémarrage (sauf dans le cas de rootkit ayant infecté le BIOS, qui ne sera lui pas rechargé automatiquement) ;
moyens de protection habituels : {{citation étrangère |lang=en |Do everything so that attacker doesn’t get into your system}}29. Tous les moyens habituels et classiques de protection d’un système informatique sont utiles, tels que [[Durcissement_(informatique)|durcissement du système]]27, filtrages applicatifs (type mod_security), utilisation de programmes antivirus2734 pour minimiser la surface d’attaque et surveiller en permanence les anomalies et tentatives de contamination, sont bien sûr à mettre en œuvre pour éviter la contamination du système et l’exposition aux [[Exploit (informatique)|exploits]].
Windows 10
Microsoft a travaillé pour rendre l’installation de rootkits plus difficile. Leur travail a porté ses fruits, mais être mieux protégé ne signifie pas être totalement protégé, car un malware (Zacinlo) présent à 90%35 sur des machines Windows a réussi à assurer sa persistance grâce à un rootkit.
Outils et programmes de détection
Bien que les rootkits existent depuis un certain temps, l’industrie de la sécurité informatique ne les a pris en compte (en masse) que récemment, les virus puis les chevaux de Troie accaparant l’attention des éditeurs. Il existe cependant quelques programmes de détection et de prévention spécifiques à Windows, tels que Sophos Anti-Rootkit, ou AVG Anti-Rootkit. Sous Linux, on peut citer rkhunter et chkrootkit ; plusieurs projets open-source existent sur Freshmeat et Sourceforge.net.
Aujourd’hui, il reste difficile de trouver des outils spécifiques de lutte contre les rootkits, mais heureusement leur détection et leur prévention sont de plus en plus intégrées dans les HIPS et même dans les anti-virus classiques, lesquels sont de plus en plus obligés de se transformer en suites de sécurité pour faire face à la diversité des menaces ; ils proposent en effet de plus en plus souvent des protections contre les rootkits, comme Avast, AVG 8.0 ou Microsoft Security Essentials.
Bonne question ! L‘attribution d’une attaque est un des problèmes récurrent et quasi-insoluble auquel est confronté la communauté de la sécurité informatique. Il va de soi qu’on souhaite toujours savoir qui nous attaque, mais à l’inverse des attaques militaires (quoique…), il est en pratique très difficile de savoir d’où vient la menace.
ITIL fait partie de ces bonnes pratiques qui donnent bonne conscience mais également beaucoup d’activité (et donc de revenus) à beaucoup de sociétés de conseil et de formation. ITIL signifie Information Technology Infrastructure Library et est une marque déposée (par Axelos).
Pourquoi je n’aime pas ITIL
Sur le principe, ITIL est une bonne chose : il doit permettre de gérer convenablement son système d’information, tout au long de son cycle de vie : c’est un framework ou cadre de travail pour l’ITSM, ou Information Technology Service Management. Il ne s’agit pas d’un standard.
Cependant, je lui reproche (mais qu’on peut toujours discuter) d’engendrer de la paperasse et de la bureaucratie, sans compter une uniformisation des façons de travailler, qui risque selon moi de conduire à une totale indifférenciation entre les entreprises. Ça peut paraître anecdotique, mais je pense pourtant que toute la richesse d’une industrie est construite par la diversité des points de vue et, plus prosaïquement, par les différences concurrentielles entre les entreprises : telle entreprise est meilleure sur tel produit ou tel service, telle autre se rattrape sur un service concurrent ou complémentaire, etc. Si tout le monde travaille de la même façon, qu’est-ce qui va me faire choisir une entreprise (un produit) plutôt qu’un autre ?
Un autre de mes ennemis : lean six sigma, la méthode pseudo-magique pour produire plus et mieux. Mais dans des secteurs industriels, pas tertiaires comme l’informatique, où la matière première est de la matière grise.
Regardons quand même ce que c’est
Il est toujours utile de connaître ses ennemis. Un des gros avantages d’ITIL est d’être public (à défaut d’être open source), pouvant ainsi être adopté par tous ceux qui le souhaitent. Comme ITIL regroupe un ensemble de bonnes pratiques, on ne peut qu’approuver.
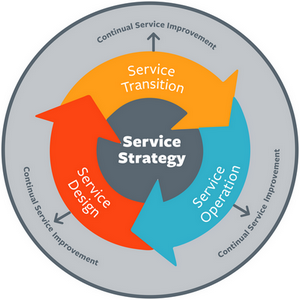
Le cycle de vie
ITIL distingue 5 grandes composantes dans le cycle de vie d’un système informatique : la stratégie, la conception, la transition (ou la mise en place au démarrage), l’opérationnel, et enfin l’amélioration continue.
Source: BMC Software (bmc.com)
Ben que ça ne soit pas un standard à respecter, cela permet quand même de :
D’avoir des références communes (fonctions, rôles, intitulés de métier, etc.) ;
De savoir quelles sont les compétences utiles pour mettre en oeuvre ces bonnes pratiques (par exemple, quelqu’un travaillant dans un centre d’appel doit savoir communiquer mais aussi avoir les compétences techniques pour répondre aux demandes, connaître les procédures d’escalade, etc.).
Service IT
Un service IT rendu à un client s’articule autour de technologies informatiques mais aussi de personnes et de processus qui le mettent en oeuvre, et il a pour objet de produire le résultat attendu par ce client (comme résoudre un incident, traiter un appel commercial, etc.). Un service peut être en lien direct avec le client, mais pas forcément : cela peut être une fonction de support. Enfin, un service peut être destiné à l’interne ou à l’externe.
ITIL distingue trois grands type de service :
De base (ou core), pour un service rendu au client et qui constitue leur cœur du métier ;
Essentiel (ou enabling) pour les services permettant de rendre le service de base (cf ci-dessus), pas forcément visible du client ;
D’amélioration (ou enhancing) pour des services non essentiels mais qui améliorent ou enrichissent le service rendu.
Le but principal est d’améliorer le service rendu, soit en augmentant l’efficacité des différentes tâches, soit en réduisant l’effet des contraintes sur le service (comme le budget, le nombre de ressources, etc.).
Les fournisseurs de service
Le fournisseur de service ou service provider peut être de 3 types :
Type 1 : Fournisseur interne (Internal Service Provider), dédié à une ligne métier. Il est ainsi expert pour le métier, mais au risque de « silotage » des activités.
Type 2 : Fournisseur interne partagé, ou mutualisé (Shared Services Unit) entre différentes lignes métiers, ce qui permet une rationalisation de son emploi.
Type 3 : Fournisseur externe à l’entreprise.
Autres éléments de vocabulaire
Une ressource est un élément tangible (matériel) rentrant dans un processus. Une capacité (ou capability) est un élément immatériel, comme un processus justement, un savoir-faire, etc.
Un processus, au sens ITIL, doit être mesurable, identifiable (et spécifique), doit être destiné à des clients identifiés, et enfin il doit être réactif (à un déclenchement par exemple). Le résultat attendu, tout comme les entrées du processus, doivent aussi être clairs et connus.
Les processus
Le modèle de processus inclus dans ITIL est assez détaillé. Autant cela paraît normal, autant cela peut venir alourdir au quotidien les activités d’une entreprise.
Un des moyens d’améliorer l’efficacité de ses processus est son automatisation, qu’il convient d’appliquer avec du bon sens.
Les différents rôles dans ITIL
Process Owner, qui est le responsable côté métier du processus. Il s’assure notamment que le processus fait bien ce qu’on attend de lui, et en définit la stratégie, les moyens, etc. ;
Process Manager, responsable opérationnel du processus. Il est souvent confondu avec le Process Owner dans de petites structures ;
Process Practitionner, qui sont les opérateurs effectifs du processus ;
Service Owner, qui est le responsable de l’exposition du service rendu. C’est lui qui est au plus près du client.
Bien sûr, un RACI1 est un élément fondamental utilisé dans ITIL.
De nombreux sites peuvent fournir des compléments d’information sur tous ces thèmes2.
L’informatique, c’est aussi physique, comme je le dis quelque part sur ce site. On pense souvent que pirater un système informatique revient à trouver le mot de passe ou la formule magique qui vous permet de rentrer dans le système ou d’en prendre le contrôle. Et qu’il s’agit donc d’une action logique et immatérielle.
Or les systèmes informatiques sont faits de composants électroniques et électriques qu’il est tout aussi envisageable d’attaquer et de modifier pour en prendre le contrôle. Il existe même des sites web qui proposent toute une panoplie d’outils matériels servant à vérifier la sécurité des vos systèmes (car le piratage est interdit), ou à aider à une conception sécurisée grâce à la connaissance des composants critiques qu’on peut être amené à utiliser.
Différentes techniques d’attaques
Imaginer que la recherche du mot de passe (du code secret) est la seule méthode d’attaque et la seule préoccupation des pirates vous amènera à de très cruelles désillusions. Même si votre code secret reste parfaitement secret, un pirate pourra prendre le contrôle du système que vous voulez protéger.
La sécurité de la biométrie repose en partie sur des idées fausses. On pense en effet qu’il suffit qu’il soit impossible de copier ou reproduire la minutie (la caractéristique biométrique telle que l’empreinte digitale, la forme de l’iris, l’ADN, etc.) pour que ce type d’authentification soit sur. D’une part c’est faut, mais en plus il est aussi possible (et facile) d’attaque le capteur biométrique qui est un élément trop souvent négligé.
Outils intéressants
iPhone
GrayKey iPhone Unlocker, système permettant de déverrouiller un iPhone (récent)1
Les cryptomonnaies ne sont pas des monnaies, en tout cas pas au sens légal du terme. Il s’agit de systèmes d’échange, basé sur des blockchains, On parle aussi de monnaies virtuelles.
Fonctionnement
Le fonctionnement est assez simple : un utilisateur détient un ou plusieurs portefeuilles, pour une cryptomonnaie donnée, et chaque portefeuille détient un certain nombre d’unités de valeur de cette cryptomonnaie.
Pour échanger des valeurs entre deux utilisateurs, il suffit d’inscrire la transaction dans la blockchain de la cryptomonnaie. Une fois que cette transaction est validée selon les règles de la chaîne, elle devient irréfutable (non répudiable), à la manière d’un livre de comptabilité : la seule façon d’annuler la transaction est de contre-passer celle-ci (réaliser la transaction inverse).
Validation des transactions
Il existe plusieurs façons de valider une transaction, ou un bloc contenant un ensemble de transactions.
Preuve de travail
La preuve de travail est à la base du bitcoin et de nombreuses cryptomonnaies. Pour valider un bloc (un ensemble de données) d’une chaîne, on lui attribue une signature. Pour le bitcoin, c’est un hash informatique qui a une forme déterminée (un nombre défini de 0).
Obtenir un hash avec de nombreux 0 est difficile car il n’y a aucune règle pour l’obtenir : il faut essayer différentes combinaisons, ce qui nécessite de nombreux calculs répétitifs. Pour cela, on ajoute une valeur (appelée nonce) au bloc et on calcule son hash. S’il a la forme désirée, c’est le gros lot ! Sinon on recommence.
Ainsi, la moindre modification du bloc changera complètement la valeur du hash : pour obtenir une valeur de hash valide et acceptable, il faudra recommencer à rechercher la valeur du nonce, ce qui prendra beaucoup de temps de calcul. C’est cette difficulté qui fait l’intérêt de la règle : il est très difficile de modifier un bloc validé. Par ailleurs, les blocs étant chaînés, plus on avance dans le temps, plus il est difficile de revenir en arrière : si on modifie un bloc ancien, il faudra le valider lui (c’est-à-dire trouver une valeur nonce convenable) mais aussi tous les blocs qui le suivent chonologiquement. Valider un bloc prend déjà beaucoup de puissance de calcul, alors plusieurs, je vous laisse imaginer.
Transparence
L’atout majeur de cette technique est d’être transparente et décentralisée. Ainsi, tout le monde peut consulter la chaîne et voir ainsi toutes les transactions ayant été effectuées (depuis la création en général), et par un calcul simple en déduire le solde de n’importe quel portefeuille.
Cette transparence, associée au fait que la validation se fait sur la base d’une règle commune, publique, et décentralisée, empêche théoriquement toute manipulation de la chaîne
Anonymat
Un des grands reproches faits aux cryptomonnaies porte sur l’anonymat des détenteurs de portefeuilles, qui faciliterait le blanchiment d’argent ou qui aiderait à réaliser des transactions illégales.
Non, le bitcoin n’est pas anonyme
Monnaie classique et virtuelle
Je pense que la critique est recevable dans certains cas, pour certaines monnaies, mais on prend trop souvent en exemple le bitcoin alors que justement cette monnaie est un mauvais candidat pour des échanges criminels.
Dans ce type d’utilisation, les défauts du bitcoin sont :
L’absence d’anonymat, justement : les portefeuilles ne sont que pseudonymisés, c’est-à-dire qu’ils ont un identifiant sans signification et sans lien direct avec le possesseur, mais les transactions sont publiques et tracées ! Il y a une différence subtile à comprendre, mais elle est de taille : on peut ainsi suivre toutes les dépenses et tous les transferts d’un compte donné, ainsi que tous les portefeuilles qui sont en lien avec lui. De plus, la plupart des plateformes d’échange (pour passer de bitcoin en monnaie sonnante et trébuchante) imposent de plus en plus souvent d’identifier le détenteur du compte.
La volatilité du cours, qui empêche des opérations trop importantes ou étalées dans le temps, en raison du risque de change.
Dans une moindre mesure la lenteur actuelle du réseau, alors que la fluidité peut concourir à faciliter la fuite et le masquage des transactions.
Des études ont analysé le processus de blanchiment, et l’usage du bitcoin reste l’exception.
Par exemple, dans l’attaque de la plateforme Akropolis en novembre 20201, le fraudeur a transféré ses fonds sur un portefeuille Ethereum, dont tout le monde peut suivre l’évolution dans la chaîne de blocs…
Peut-on quand même être anonyme ?
Oui, on peut, à peu près. Mais pas avec le bitcoin. Les criminels auront plutôt recours à d’autres cryptomonnaies plus adaptées : Monero2 est souvent citée comme meilleur candidate. Leur construction et leur fonctionnement ont été pensés de façon à rendre le plus anonyme possible les opérations (et les opérateurs), mais ce degré d’anonymisation dépend de chaque monnaie, et cela reste faillible3, même pour Monero. Rappelons-nous aussi qu’une blockchain est initialement un registre de transaction distribué, accessible à tous !
Quel est le meilleur moyen d’être anonyme ?
L’argent liquide. Rien de plus pratique : anonymat complet et aucun traçage par défaut.
Faut-il investir dans les cryptomonnaies ?
On peut le faire aujourd’hui, mais à une condition : n’investir que ce qu’on accepte de perdre. En d’autres termes, considérez votre investissement en cryptomonnaie comme perdu au moment même où vous investissez, en raison des incertitudes beaucoup trop nombreuses pesant sur ces monnaies.
Personne n’est en mesure de prédire comment évolueront les différentes réglementations et lois encadrant les placements financiers et les cryptomonnaies, ni la solvabilité d’aucun système d’échange. On a déjà vu des places d’échanges avoir de gros soucis, voire même disparaître. Et la valeur d’une cryptomonnaie dépend de l’appréciation que les investisseurs en ont, sachant que certaines de ces monnaies sont plus ou moins liées à un sous-jacent (une vraie valeur économique, qui n’est d’ailleurs pas forcément elle-même très sûre), alors que d’autres n’en ont même pas.
Les attaques sur les cryptomonnaies
Basée sur des outils informatiques, les cryptomonnaies sont forcément attaquables, plus ou moins facilement.
Attaque des 51%
L’attaque la plus connue pour les cryptomonnaies à preuve de travail est l’attaque des 51%. Le principe de la validation d’un bloc dans ce cas est simple : si la majorité des mineurs sont d’accord, alors le bloc est validé. Fort logiquement, si 51% des mineurs sont contrôlés par une seule entité, celle-ci peut décider ce qu’elle veut : modifier le bloc, le rejeter, etc. De nombreux pools de mineurs de bitcoin se sont scindés pour amoindrir le risque de cette attaque. D’autres cryptomonnaies, moins répandues, ayant moins de mineurs, sont beaucoup plus vulnérables et plusieurs attaques ont déjà été recensées, comme sur le VertCoin4 par exemple.
Le cloud computing est avant tout un terme marketing qui, comme souvent en informatique, ne fait que remettre en avant des notions existantes (mais qui évoluent au cours du temps, les rendant tantôt plus accessibles, tantôt plus pratiques que d’autres). Brut de fonderie, je dirais que ce qu’on appelle couramment cloud consiste principalement à faire tourner son informatique (infrastructure ou applicative) sur les ordinateurs de quelqu’un d’autre.
Définition
Je ne définirai pas forcément le cloud comme le NIST1 qui indique (traduction approximative) :
Le cloud computing est un modèle permettant l’accès en réseau à un pool de ressources partagées de ressources informatiques configurables pouvant être rapidement provisionnées avec un effort minimal de gestion et d’interactions avec le fournisseur.
Les principales caractéristiques sont :
Ressources disponibles à la demande ;
Large accès via un réseau ;
Mise en commun des ressources ;
Elasticité (en gros : on peut créer ou supprimer très rapidement des ressources de taille et de caractéristiques très variables) ;
Mesurabilité ;
Bien que très intéressante et très réfléchie, je l’adapterai un peu au vu de mon expérience personnelle. D’autant que les modèles proposés ne sont pas vraiment le reflet des pratiques industrielles.
Cloud public, privé, hybride
Le NIST définit (à mon sens) correctement les types privé et public, qui sont respectivement dédié à l’usage d’un seul client (ou organisation) et ouvert à tout client, mais il introduit un type communautaire, constitué de plusieurs organisations ayant un intérêt commun, et qui n’est jamais utilisé en pratique, sauf peut-être dans les clouds gouvernementaux proposés par Amazon.
Point intéressant : aucune mention n’est faite de la localisation des infrastructures clouds par rapport au client. Que le cloud soit interneou externe n’a que peu d’importance dans cette définition, alors qu’en pratique la localisation est une préoccupation constante des directions informatiques.
Leur définition du cloud hybride est également bancale : en gros ça n’est qu’un mix de clouds, alors qu’en général on parle souvent de cloud hybride pour désigner un mélange de cloud et d’infrastructures classiques possédées par le client (ou organisation).
Responsabilité
Un point crucial selon moi a été oublié par le NIST : la responsabilité des ressources. En effet, la virtualisation est une composante intrinsèque des infrastructures clouds (en terme d’elasticité principalement), et elle marque la frontière entre ce qui est de la responsabilité du fournisseur et celle du client.
Ainsi, le niveau hyperviseur (qui est de la responsabilité du fournisseur) sépare la partie matérielle (également de la responsabilité du fournisseur), cachée du client, des services exposés et proposés au client dont la gestion est de sa responsabilité. En clair, le fournisseur doit s’assurer qu’il peut proposer des services fiables et conformes aux clients qui les gèrent selon leurs besoins.
Ce modèle de responsabilité partagée, cher à Amazon2, est pourtant fondamental dans l’usage du cloud pour toutes les questions relatives à la sécurité et à la conformité.
Afin d’avoir les idées claires, voici quelques définitions aidant à appréhender la structuration d’une gestion de droits informatiques. Il est également utile d’être à l’aise avec la notion de DICP.
Un rôle est un ensemble d’habilitations nécessaires à un type d’utilisation d’une ressource.
Un rôle applicatif est un rôle propre à une (et une seule) application.
Un profil est un ensemble de rôles, souvent regroupés par métier.
L’habilitation est le droit d’effectuer une action sur une ressource, souvent associée à un périmètre (temporel, fonctionnel, géographique). C’est le niveau « unitaire ».
Pour une gestion claire, les rôles ne devraient être liés qu’à des profils, lesquels correspondent généralement à une fonction exercée au sein d’une organisation.
XACML (eXtensible Access Control Markup Language), langage permettant de définir :
des autorisations ou des contrôles d’accès basés sur des attributs,
des contrôles d’accès à des points de décision (PDP, Policy Decision Point) puis de les transmettre à des points d’application (PEP, Policy Enforcement Point).
SCIM (System for Cross-domain Identity Management), système d’échanges de données, d’attributs, entre systèmes externes.
XACML permet par exemple de définir les droits d’un utilisateur chez un fournisseur cloud à partir de son IAM interne.
Un hacker n’est pas un pirate. D’ailleurs la grande mode des hackathons ne cherche pas à faire la promotion des pirates mais de la programmation (collaborative généralement) ou de la bidouille dans n’importe quel domaine.
La bonne traduction de hack devrait être bidouille : un hacker n’est rien d’autre qu’un bidouilleur.
Le bon et le méchant
Nous commettons souvent l’erreur d’assimiler hacker et cracker. Le cracker pirate les systèmes informatiques et casse les sécurités mises en place. J’essaye souvent d’employer les mots pirate, fraudeur, cybercriminel, criminel, attaquant à la place, mais je me laisse parfois aller.
Le protocole DNS permet de connaître l’adresse réelle d’un serveur web. Plus précisément cela transforme le nom de domaine inclus dans une URL (adresse symbolique du genre https://secu.si) en adresse technique (adresse IP).
Pour cela, de très nombreux serveurs se répartissent la tâche sur toute la planète web. Pour des raisons d’efficacité, nous nous retrouvons souvent connectés directement à un serveur géré par notre fournisseur d’accès internet. Rien de bien fameux, sauf que les fournisseurs d’accès gardent souvent des traces, pour leur usage propre ou parce qu’on leur demande1.