Un botnet est un ensemble de bots informatiques qui sont reliés entre eux. Historiquement, ce terme s’est d’abord confondu avec des robots IRC (bien que le terme ne se limitait pas à cet usage spécifique), qui était un type de botnet particulier servant sur les canaux IRC.
Usage légitime
Sur IRC, leur usage est de gérer des canaux de discussions, ou de proposer aux utilisateurs des services variés, tels que des jeux, des statistiques sur le canal, etc. Être connectés en réseau leur permet de se donner mutuellement le statut d’opérateur de canal de manière sécurisée, de contrôler de manière efficace les attaques par flood ou autres. Le partage des listes d’utilisateurs, de bans, ainsi que de toute sorte d’informations, rend leur utilisation plus efficace.
Il existe d’autres usages légitimes de botnets, comme l’indexation web : le volume des données à explorer et le nécessaire usage de parallélisation impose l’usage de réseaux de bots.
Dérives et usages malveillants
Les premières dérives sont apparues sur les réseaux IRC1 : des botnets IRC (Eggdrop en décembre 1993, puis GTbot en avril 1998) furent utilisés lors d’affrontements pour prendre le contrôle du canal.
Aujourd’hui, ce terme est très souvent utilisé pour désigner un réseau de machines zombies, car l’IRC fut un des premiers moyens utilisés par des réseaux malveillants pour communiquer entre eux, en détournant l’usage premier de l’IRC. Le premier d’entre eux qui fut référencé a été W32/Pretty.worm2, appelé aussi PrettyPark, ciblant les environnements Windows 32 bits, et reprenant les idées d’Eggdrop et de GTbot. A l’époque, ils ne furent pas considérés comme très dangereux, et ce n’est qu’à partir de 2002 que plusieurs botnets malveillants (Agobot, SDBot puis SpyBot en 2003) firent parler d’eux et que la menace prit de l’ampleur.
Toute machine connectée à internet est susceptible d’être une cible pour devenir une machine zombie : des réseaux de botnets ont été découverts sur des machines Windows, Linux, mais également sur des Macintosh, voire consoles de jeu3 ou des routeurs4.
Usages principaux des botnets malveillants
La caractéristique principale des botnets est la mise en commun de plusieurs machines distinctes, parfois très nombreuses, ce qui rend l’activité souhaitée plus efficace (puisqu’on a la possibilité d’utiliser beaucoup de ressources) mais également plus difficile à stopper.
Usages des botnets
Les botnets malveillants servent principalement à :
- Relayer du spam pour du commerce illégal ou pour de la manipulation d’information (par exemple des cours de bourse) ;
- Réaliser des opérations de phishing ;
- Identifier et infecter d’autres machines par diffusion de virus et de programmes malveillants (malwares) ;
- Participer à des attaques groupées (DDoS)5 ;
- Générer de façon abusive des clics sur un lien publicitaire au sein d’une page web (fraude au clic) ;
- Capturer de l’information sur les machines compromises (vol puis revente d’information) ;
- Exploiter la puissance de calcul des machines ou effectuer des opérations de calcul distribué notamment pour cassage de mots de passe ;
- Servir à mener des opérations de commerce illicite en gérant l’accès à des sites de ventes de produits interdits ou de contrefaçons via des techniques de fast-flux, single ou double-flux ou RockPhish6 ;
- Miner de la cryptomonnaie ;
- Voler des sessions par credential stuffing.
Motivation des pirates
Motivation économique
L’aspect économique est primordial : la taille du botnet ainsi que la capacité d’être facilement contrôlé sont des éléments qui concourent à attirer l’activité criminelle, à la fois pour le propriétaire de botnet (parfois appelé « botherder » ou « botmaster ») que pour les utilisateurs, qui la plupart du temps louent les services d’un botnet pour l’accomplissement d’une tâche déterminée (envoi de pourriel, attaque informatique, déni de service5, vol d’information, etc). En avril 2009, un botnet de 1 900 000 machines7 mis au jour par la société Finjian engendrait un revenu estimé à {{formatnum:190000}} dollars par jour à ses « botmasters »8.
Motivation idéologique
En dehors de l’aspect économique, les attaques informatiques peuvent devenir une arme de propagande ou de rétorsion, notamment lors de conflits armés ou lors d’événements symboliques. Par exemple, lors du conflit entre la Russie et la Géorgie en 2008, le réseau géorgien a été attaqué sous de multiples formes (pour le rendre indisponible ou pour opérer à des défacements des sites officiels)9. En 2007, une attaque d’importance contre l’Estonie a également eu lieu10 : la motivation des pirates serait le déplacement d’un monument en hommage aux soldats russes du centre de la capitale estonienne11.
Motivation personnelle
La vengeance ou le chantage peuvent également faire partie des motivations des attaquants, sans forcément que l’aspect financier soit primordial : un employé mal payé12 ou des joueurs en ligne défaits3 peuvent chercher à se venger de l’employeur ou du vainqueur du jeu.
Architecture d’un botnet
Mode actuel de communication des botnets
Via canal un canal de commande et contrôle (C&C)
- Canaux IRC13 (le premier historiquement), souvent sur un canal privé.
Via des canaux décentralisés
- P2P61413, pour ne plus dépendre d’un nœud central ;
- HTTP613 (parfois via des canaux cachés15), ce qui a pour principal avantage de ne plus exiger de connexion permanente comme pour les canaux IRC ou le P2P mais de se fondre dans le trafic web traditionnel ;
- Fonctions du Web 2.013, en faisant une simple recherche sur certains mots-clés afin d’identifier les ordres ou les centres de commandes auxquels le réseau doit se connecter16.
Cycle de vie
Un botnet comporte plusieurs phases de vie117. Une conception modulaire lui permet de gérer ces plusieurs phases avec une efficacité redoutable, surtout dès que la machine ciblée est compromise. La phase d’infection est bien évidemment toujours la première, mais l’enchaînement de ces phases n’est pas toujours linéaire, et dépendent de la conception du botnet.
Infection de la machine
C’est logiquement la phase initiale. La contamination passe souvent par l’installation d’un outil logiciel primaire, qui n’est pas forcément l’outil final. Cette contamination de la machine utilise les mécanismes classiques d’infection :
Activation
Une fois installée, cette base logicielle peut déclarer la machine à un centre de contrôle, qui la considèrera alors comme active. C’est une des clés du concept de botnet, à savoir que la machine infectée peut désormais être contrôlée à distance par une (ou plusieurs) machine tierce. Dans certains cas, d’autres phases sont nécessaires (auto-protection, mise-à-jour, etc) pour passer en phase opérationnelle.
Mise-à-jour
Une fois la machine infectée et l’activation réalisée, le botnet peut se mettre-à-jour, s’auto-modifier, ajouter des fonctionnalités, etc. Cela a des impacts importants sur la dangerosité du botnet, et sur la capacité des outils de lutte à enrayer celui-ci, car un botnet peut ainsi modifier sa signature virale et d’autres caractéristiques pouvant l’amener à être découvert et identifié.
Auto-protection
D’origine, ou après une phase de mise-à-jour, le botnet va chercher à s’octroyer les moyens de continuer son action ainsi que des moyens de dissimulation. Cela peut comporter :
- Installation de rootkits ;
- Modification du système (changement des règles de filtrage réseau, désactivation d’outils de sécurité, etc) ;
- Auto-modification (pour modifier sa signature) ;
- Exploitation de failles du système hôte, etc.
Propagation
La taille d’un botnet est à la fois gage d’efficacité et de valeur supplémentaire pour les commanditaires et les utilisateurs du botnet. Il est donc fréquent qu’après installation, la machine zombie va chercher à étendre le botnet :
- Par diffusion virale, souvent au cours d’une campagne de spam (liens web, logiciel malveillant en PJ, etc)
- Par scan :
Phase opérationnelle
Une fois installé, et déclaré, la machine zombie peut obéir aux ordres qui lui sont donnés pour accomplir les actions voulues par l’attaquant (avec, au besoin, installation d’outils complémentaires via une mise-à-jour distante) :
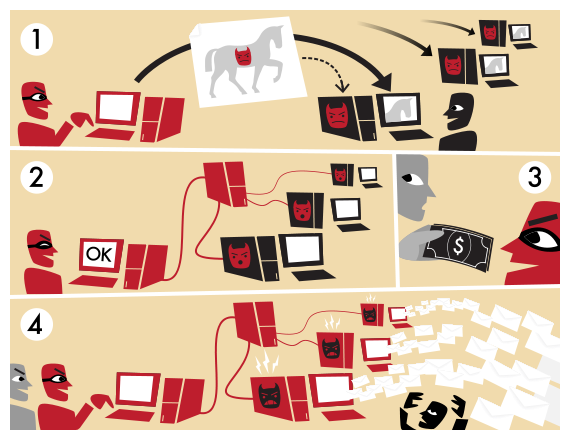
Illustration d’un exemple de botnet
Voici le principe de fonctionnement d’un botnet servant à envoyer du pourriel :
- Le pirate tente de prendre le contrôle de machines distantes, par exemple avec un virus, en exploitant une faille ou en utilisant un cheval de Troie.
- Une fois infectées, les machines vont terminer l’installation ou prendre des ordres auprès d’un centre de commande, contrôlé par le pirate, qui prend donc ainsi la main par rebond sur les machines contaminées (qui deviennent des machines zombies).
- Une personne malveillante loue un service auprès du pirate.
- Le pirate envoie la commande aux machines infectées (ou poste un message à récupérer, selon le mode de communication utilisé). Celles-ci envoient alors des courriers électroniques en masse.
Taille des botnets
Il est extrêmement difficile d’avoir des chiffres fiables et précis, puisque la plupart des botnets ne peuvent être détectés qu’indirectement. Certains organismes comme shadowserver.org tentent d’établir des chiffres à partir de l’activité réseau, de la détection des centres de commandes (C&C), etc.
Nombre de réseaux (botnets)
Au mois de février 2010, on estimait qu’il existait entre {{formatnum:4000}} et {{formatnum:5000}} botnets actifs18. Ce chiffre est à considérer comme une fourchette basse, puisque les botnets gagnent en furtivité et que la surveillance de tout le réseau internet est impossible.
Taille d’un réseau
La taille d’un botnet varie mais il devient courant qu’un réseau puisse comprendre des milliers de machines zombies. En 2008, lors de la conférence RSA, le top 10 des réseaux comprenait de 10 000 à 315 000 machines, avec une capacité d’envoi de mail allant de 300 millions à 60 milliards par jour (pour Srizbi, le plus important botnet à cette date)1920.
En 2018, l’activité des botnets se concentrait sur deux grands réseaux : Necurs et Gatmut. Pour McAfee, ils sont à eux seuls responsables de 97 % du trafic des réseaux de robots (botnets) de spam21 au 4e trimestre 2018.
Nombre total de machines infectées
Dans son rapport de 2009, la société MessageLabs estime également que 5 millions de machines20 sont compromises dans un réseau de botnets destiné au spam.
Botnets de tous pays, unissez-vous !
La dernière mode dans le monde des botnets est de s »unir, car il est bien connu que l’union fait la force. La difficulté croissante pour effectuer des fraudes bancaires pousserait les criminels à combiner leurs forces22 afin de disposer de plusieurs méthodes de capture de données, ainsi que pour compromettre de façon plus efficace les cibles.
Lutte contre l’action des botnets
La constitution même d’un botnet, formé parfois de très nombreuses machines, rend la traçabilité des actions et des sources délicate. Plus le botnet est grand, plus il devient également difficile de l’enrayer et de l’arrêter puisqu’il faut à la fois stopper la propagation des agents activant le botnet et nettoyer les machines compromises.
Les anciennes générations s’appuyaient souvent sur un centre de contrôle centralisé ou facilement désactivable (adresse IP fixe pouvant être bannie, canal IRC pouvant être fermé, etc). Désormais, le pair à pair permet une résilience du système de communication, et les fonctions Web 2.0 détournées rendent l’interception très complexe : le botnet recherche un mot clé sur le web et l’utilise pour déterminer l’emplacement du centre de contrôle auprès duquel il doit recevoir ses ordres.
Détection
- Empreintes
- Observation du trafic
- Analyse de logs
Prévention
- Liste noires
- Mesures habituelles de protection du réseau (cloisonnement, restrictions, etc)
- Mesures habituelles de protection des machines (anti-virus, HIDS/HIPS, mot de passe, gestion des droits utilisateurs, anti-spam, gestion des mises-à-jour, etc)
Examples
L’évolution probable des botnets
BITB (Botnet In The Browser)
Les futurs botnets pourraient évoluer dans leur architecture avec l’arrivée d’HTML5 : les nouvelles fonctionnalités offertes par la nouvelle spécification HTML pourrait permettre de réaliser des botnets d’une nouvelle nature, à l’intérieur même d’un navigateur web (et non plus codé en dur et installé sur une machine)23.
Il est également fort probable de les voir continuer à exister, persistants en dépit de efforts réalisés pour les éradiquer (comme le botnet Satori)24 : ils exploiteront toute faille pouvant être exploitée à grande échelle, dans les réseaux traditionnels mais aussi les smartphones ou les objets connectés.
Les objets connectés
Merci à eux, objets si nombreux, et si peu sécurisés. On a trouvé traces d’objets connectés dans des botnets dès 201325, mais depuis 2016, ils ont commencé à représenter une véritable menace en raison de la facilité de leur prise de contrôle, alors que leurs capacités suffisaient pour construire une attaque réseau puissante, les attaques DDoS dont l’origine était un botnet d’objets connectés pouvant atteindre le Tb/s, c’est-à-dire la limite technique des structures d’absorption à la même époque. L’hébergeur OVH en a subi les conséquences et a communiqué26 sur le sujet afin d’alerter les spécialistes sur ce risque. En 2018, la chasse au botnet représentait toujours un travail conséquent27 pour l’hébergeur.
Conférences et action coordonnée
A vue de l’importance des dégâts des botnets, et de leur répartition autour du globe, une action coordonnée est souvent le seul moyen de diminuer significativement l’activité d’un botnet. Le sujet a également pris suffisamment d’ampleur et d’importance que des conférences sont dédiées à ce problème, telle que la BotConf qui existe depuis 2013.
Voir aussi
Articles connexes
Liens externes