Sources
- https://duo.com/blog/the-beer-drinkers-guide-to-saml
- https://aws.amazon.com/fr/blogs/security/enabling-federation-to-aws-using-windows-active-directory-adfs-and-saml-2-0/
Pour faire simple :
Les contrôles d’accès sont les mécanismes permettant de préserver l’intégrité et la confidentialité des informations.
L’authentification dans un système informatique est des opérations les plus essentielles pour la sécurité globale de celui-ci. S’authentifier, c’est prouver qui on est au système. Cela comprend en réalité deux actions, qui ne sont pas que des élucubrations théoriques ni des lubies de chercheurs en sécurité : l’identification et l’authentification. Elles peuvent parfois être réalisées en une seule opération, parfois en deux.
L’identification consiste à donner au système une identité. C’est en fonction de cette identité qu’on aura plus ou moins de droits sur le système, et qu’on pourra mettre en œuvre l’ensemble des mécanismes de protection pour empêcher ou autoriser des actions sur le systèmes (lecture ou modification d’information, exécution de tâches, etc.).
Mais il ne suffit pas de dire qui on est, même en jurant sur la Bible. Ça serait trop facile sinon : je dis que je suis l’administrateur, et hop, j’ai tous les droits. Non, il faut aussi prouver que je suis bien celui que je prétends être ! Il existe plusieurs façons de le faire, plus ou moins sûres. Aucune de ces méthodes ne peut être parfaite, dans ce bas-monde ; chacune peut être plus ou moins sûre, plus ou moins facile à utiliser et malheureusement les méthodes les plus sûres sont souvent les plus pénibles à utiliser.
L’exemple le plus commun est celui du mot de passe : je donne mon identité (le « login ») et je prouve qu’il s’agit de moi en donnant un code secret (le « mot de passe »). Ce secret n’est censé être connu que de l’utilisateur et du système, et c’est cela qui prouve l’identité de l’utilisateur : normalement, seul l’utilisateur connaît ce secret en dehors du système.
Le bon facteur d’authentification, du point de vue théorique, est celui qui prouve de façon certainel’identité d’un utilisateur.
Dans un monde parfait, où il n’y aurait aucun malfaisant, où personne ne chercherait à prendre la place d’un autre pour voler des informations ou des valeurs quelconques à autrui, tout irait bien. Au risque de surprendre la plupart des lecteurs, ça n’est pas le cas. Il y a même toute une économie liée à la criminalité informatique, où le vol de session est une étape incontournable pour les attaquants.
Donc les criminels vont chercher à usurper votre identité, en s’attaquant aux facteurs d’authentification que vous possédez. Et pour cela il existe différentes techniques, auxquelles nous ne pensons pas forcément.
Prenons l’image d’un coffre-fort : seul celui qui détient la clé peut l’ouvrir. Théoriquement. Mais un voleur peut tenter de vous voler la clé, mais s’il n’y arrive pas, il peut aussi utiliser un chalumeau pour passer en force, écouter le cliquetis du mécanisme pour trouver la combinaison, essayer de retrouver les caractéristiques de la clé pour la reproduire (référence constructeur, prise d’empreintes ou de photos sous différents angles), etc.
Il faut donc partir du principe qu’une compromission de notre facteur d’authentification est toujours envisageable.
Un facteur d’authentification doit posséder plusieurs caractéristiques. Il doit notamment être, idéalement :
Si la clé de notre coffre-fort était volée, ou si on suspectait qu’elle ait pu être reproduite, il conviendrait alors de changer la serrure du coffre et le jeu de clé pouvant l’ouvrir. Idem pour un mot de passe. Et si on a utilisé la même clé sur plusieurs coffres, l’opération sera à répéter sur chacun des coffres.
Il est rare qu’un facteur d’authentification soit parfait. En pratique, c’est même impossible. Il faut souvent confronter ses caractéristiques au cas d’usage envisagé, pour voir s’il convient et s’il couvre les risques redoutés. Par exemple, dans un cadre bancaire, il est important de pouvoir répudier un facteur d’authentification, pour éviter qu’un malfaiteur puisse passer sans fin des opérations à son bénéfice depuis votre compte.
Un bon moyen de pallier à certaines faiblesses d’un facteur consiste à lui ajouter un second facteur d’authentification.
Voir aussi Le doigt dans l’œil de la biométrie (nextinpact.com).
La biométrie n’est pas, selon moi, adaptée aux processus informatiques. Point final. Et je ne parle même pas des problèmes d’implémentation1… Alors pourquoi ça a le vent en poupe ?
Alors pourquoi on nous en vend autant ? Parce qu’on peut en vendre, justement. Avant on ne pouvait pas, car les lecteurs biométriques étaient trop chers. Maintenant qu’ils sont bon marché, on profite de leur prétendue sécurité, issue probablement de l’image véhiculée par le cinéma de science fiction.
Un système de contrôle biométrique est un système automatique de mesure basé sur la reconnaissance de caractéristiques propres à l’individu (définition du CLUSIF). Il peut en être fait différents usages, mais en informatique, on l’utilise quasi-exclusivement dans des processus d’authentification.
Historiquement, la biométrie est une innovation datant de la préhistoire2 : les artistes utilisaient déjà la forme de leur main3 pour signer leurs peintures, ce qui constitue une forme d’identification biométrique (avec trace, cf ci-dessous).
Tout d’abord, il faut se rappeler ce qu’est un facteur d’authentification : un moyen de prouver au système que vous êtes bien celui que vous prétendez être.
Tout d’abord, le sentiment de sécurité en ce qui concerne la biométrie provient de l’idée fallacieuse que nous sommes les seuls à disposer des originaux : nos empreintes digitales, la forme de notre main, et donc de toutes les caractéristiques utilisées en biométrie.
Pour commencer, cela est tout d’abord variable selon le type de caractéristique utilisé. La CNIL propose une classification en trois grands groupes4.
Les caractéristiques biométriques sans trace sont celles qu’on ne peut que lire, sans pouvoir les copier ou ne recueillir un échantillon. Le scan du réseau veineux de la main est un exemple de système de biométrie sans trace : seul un capteur peut lire la forme voulue, on ne peut pas la reproduire (c’est-à-dire qu’on ne sait pas faire de main artificielle ayant les mêmes caractéristiques), et l’utilisateur ne laisse pas derrière lui de trace permettant de retrouver ses caractéristiques biométriques. Les systèmes sans trace sont a priori les meilleurs candidats pour l’authentification biométrique.
Les systèmes avec traces semblent moins propices à l’utilisation, car ils sont par définition ceux où l’utilisateur peut laisser des traces, soit lors de l’authentification, soit en dehors. L’empreinte digitale en est l’exemple parfait : nous laissons nos empreintes partout, ce qui a fait dans un premier temps la joie des policiers de l’identification criminelle, et ce qui fait ou fera la joie des pirates d’ici peu.
Les systèmes intermédiaires sont entre les deux : ils ne laissent pas de trace directement, mais il est (plus ou moins) facile de se procurer un échantillon. La voix, la forme du visage ou la forme de l’iris en font partie. La voix peut être enregistrée, notre visage peut être retrouvé partout, y compris maintenant grâce aux système de vidéosurveillance.
La CNIL considère désormais que toutes les biométries sont à traces. Je trouve ça un tantinet exagéré, mais pourquoi pas : nous laissons tellement de traces directes ou indirectes de nos jours… La biométrie veineuse doit encore être sans trace, mais elle reste trop contraignante pour atteindre le grand public.
De fait, la CNIL classe les solutions en fonction du contrôle que l’utilisateur peut exercer sur la biométrie :
Autrefois, il était impossible d’avoir une base biométrique centralisée sans avoir une autorisation de la CNIL.
Aujourd’hui c’est un peu différent : il n’y a plus d’autorisation CNIL ! On passe sur le régime des PIA (Privacy Impact Assessment), déclaratif (mais obligatoire dans le cas de la biométrie). Mais la CNIL conserve une doctrine d’usage de la biométrie, et il faudra rester dans les clous : inutile d’espérer centraliser des tonnes de données biométriques sans savoir une bonne raison de le faire, notamment dans le cadre professionnel (cf. délibération 2019-001 de la CNIL).
L’avantage d’une base locale est évidente en termes de protection de la vie privée : seul l’utilisateur dispose du système biométrique et reste maître du stockage de la donnée, comme dans le cas des lecteurs d’empreinte des téléphones portables.
L’inconvénient est que cela ne permet que de vérifier que l’utilisateur est le bon lors de l’authentification : on ne compare la mesure qu’au seul individu connu dans le système : on fait une comparaison 1 à 1.
Dans une base centralisée, comme par exemple l’authentification vocale par téléphone, les données sont chez le fournisseur de l’accès, avec une maîtrise moins facile par l’utilisateur.
L’avantage de la centralisation est de permettre la confrontation 1 à n : un utilisateur essayant de s’authentifier vocalement avec des identités différentes pourra être signalé par le système, par exemple. Autre cas d’usage : un utilisateur appelle, et le système le reconnaît automatiquement, en comparant sa voix avec celles qu’il connaît : l’authentification se fait sans friction.
Dans certains cas il s’agit d’un choix à faire ; dans d’autres, c’est imposé par la solution.
La plus grosse des erreurs quand on parle de biométrie est d’imaginer que c’est difficile voire impossible à contrefaire ou reproduire. Peut-être dans certains cas, mais cela ne rend pas la biométrie inattaquable, car il y a d’autres façons d’attaquer un système biométrique, comme l’attaque matérielle. Sans compter que si, les données biométriques peuvent être contrefaites ou reproduites.
Si on ne vous vole pas directement vos données biométriques, on peut encore les récupérer sur les interfaces physiques de liaison, trop souvent oubliées dans le domaine de la sûreté. Le dispositif pour lire le bus de données est en vente libre5 pour pas très cher…
Une autre énorme erreur concernant la biométrie est de croire qu’elle est exacte. Or toutes les biométries sont basées sur des mesures, faites par des capteurs, ayant tous une marge d’erreur.
Sans compter que certaines caractéristiques ne sont pas strictement identiques selon les mesures : l’ADN change peu, mais la voix ou même les empreintes peuvent connaître des modulations. Pour établir une correspondance biométrique, on utilise donc toujours un score et non une égalité parfaite (même pour l’ADN).
Ce score est issue de la mesure, transformée en score de ressemblance avec le gabarit de référence (= la voix de référence, l’empreinte de référence, etc.).
On considère ainsi que le spécimen mesuré par le capteur est bien celui qu’on attend quand la ressemblance est suffisante : une empreinte digitale sera considérée comme celle attendue si elle présente suffisamment de points correspondants à l’empreinte attendue.
C’est bien différent d’un mot de passe où soit le mot de passe est le bon, soit il est différent (processus binaire).
Il existe de nombreux faux en biométrie. C’est-à-dire des valeurs permettant de mesurer et de calibrer un système biométrie, dont les plus courants sont les faux positifs et les faux négatifs.
Un faux positif est la situation où le système biométrique laisse passer un imposteur : on pense que l’authentification est positive, c’est-à-dire qu’on a identifié un utilisateur légitime, alors que c’est faux.
A l’inverse, l’authentification est négative quand on rejette un utilisateur. Or s’il s’agit d’un utilisateur légitime, il sera rejeté à tort : on sera donc dans le cas d’un faux négatif.
On utilise les taux de faux positifs (False Acceptance Rate) et de faux négatifs (False Rejection Rate) pour mesurer le fonctionnement d’un système biométrique.
On pense naïvement qu’il faut que les deux taux soient les plus bas possibles pour que le système soit parfait. Or c’est faux. Ces deux taux ne sont pas réglables si facilement et surtout ils ont une influence énorme sur le fonctionnement du système.
Imaginons qu’une mesure donne un score de similarité de 99% (par exemple). Avons-nous identifié la bonne personne ?
Ben oui : tout dépend de la tolérance qu’on va autoriser, par choix. Si on est très tolérant, alors cela implique qu’on sera moins strict et qu’une mesure donnant un résultat moins bon (98% par exemple) sera accepté pour identifier l’individu.
Augmenter la tolérance implique d’accepter plus facilement l’utilisateur, donc augmente le risque d’accepter un imposteur !
Ok ? Un utilisateur légitime aura moins de mal à s’authentifier puisqu’on est tolérant, et donc qu’on accepte le risque de laisser passer un imposteur, ce qui augmente les faux positifs.
Diminuer la tolérance implique d’accepter plus difficilement un utilisateur, donc diminue le risque d’accepter un imposteur !
C’est bien dans l’absolu, car on diminue le risque de fraude ; par contre on augmente l’inconfort pour l’utilisateur légitime qui risque de devoir s’y prendre à plusieurs fois pour s’authentifier.
Dilemne : souhaite-t-on privilégier le confort de l’utilisateur ou la sécurité ? Pour cela le seul moyen est de varier la sensibilité de la mesure (et du score de ressemblance) mais tout est lié : augmenter la sensibilité fait baisser le FAR mais augmente le FRR ! Et inversement. Donc soit c’est le confort, soit c’est la sécurité.
Une mesure souvent utilisée pour mesurer la qualité d’un système biométrique est le taux d’erreur équivalent (Equivalent Error Rate). C’est conventionnellement le taux où FAR = FRR.
On a vu que les taux FAR et FRR peuvent varier, mais en restant liés l’un avec l’autre : augmenter l’un diminue l’autre. Donc ne prendre en compte que l’un des deux n’a pas de signification puisqu’ils sont… variables ! Et pour avoir un chiffre qui caractérise les deux, on prend le point où ces taux se rencontrent.
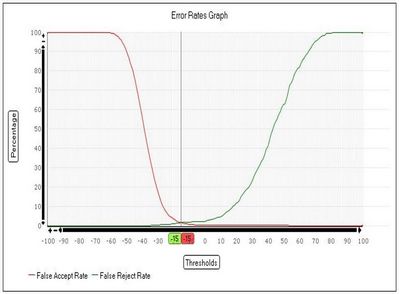
L’intérêt de ce point fixe est qu’il caractérise toutes les solutions de biométrie. Plus il est bas, plus la solution est précise. Ici, pour la biométrie vocale, on est aux alentours de 1-1,5%.
Autre critère important : la forme de la courbe. Elle indique comment varie les FAR et FRR selon qu’on le bouge dans un sens ou dans l’autre.
Pour qu’une authentification biométrique soit utilisable, elle doit combiner plusieurs caractéristiques ; elle doit être :
Or il est impossible d’affirmer qu’une solution est infalsifiable : on peut tout au plus affirmer qu’à notre connaissance, elle est infalsifiable. A contrario, on peut affirmer qu’elle est attaquable quand il existe au moins un scénario d’attaque.
En 2018, quasiment toutes les caractéristiques biométriques peuvent être reproduites de façon à tromper les capteurs, car quasiment aucun d’eux ne vérifie que la personne est effectivement présente lors de l’authentification !
La liveness detection (la vivantitude en français, la détection du vivant) est oublié de quasiment toutes les solutions de biométrie, ou elle n’est que très sommaire (et elle peut être également trompée).
A partir du moment où presque toutes les biométries laissent des traces, et qu’on peut donc reproduire les caractéristiques souhaitées, la détection de vie devrait être un impératif pour tous les systèmes biométriques : personne n’est capable (pour l’instant) de reproduire un être vivant (ou suffisamment vivant) pouvant tromper les capteurs. Or cette liveness detection est délaissée, probablement car elle est très complexe à mettre en oeuvre.
Or tant que cette détection de vie ne sera pas en place, toutes les biométries présentées à froid ne seront pas dignes de confiance. Et si on arrive à un niveau élevé de détection de vie, il faudra garder à l’esprit que les pirates ont plus d’imagination que nous pour tromper les systèmes.
L’empreinte digitale est curieusement très utilisée, alors que c’est un assez mauvais candidat puisqu’étant avec traces. Le Chaos Computer Club a pu tromper très rapidement le système biométrique de l’iPhone, puis du Samsung S5, et surtout à démontré qu’il était possible de récupérer une image de l’empreinte suffisamment précise pour être utilisée à partir d’un appareil photo du commerce, à une distance de trois mètres6.
Ensuite il faut faire preuve de bon sens : sécuriser un terminal grâce à une empreinte qu’on retrouve… partout sur le terminal lui-même, car il est rare de porter des gants avec nos smartphones ! Surtout si on veut utiliser la saisie tactile ou le lecteur d’empreinte. Et comme la mode est aux surfaces brillantes…
Bien que je préfère espérer que certains faits divers stupéfiants ne restent qu’exceptionnels, mais il y a déjà des précédents :
J’ai peur que la nature humaine ne pousse des criminels à des actions de plus en plus insensées pour contourner la quasi-exactitude d’une identification biométrique. Comme il est précisément impossible de modifier ses caractéristiques biométriques, des malfrats vont (et l’ont déjà fait) mettre en oeuvre des scenarii insensés et violents soit pour récupérer les identifiants biométriques, soit pour disposer d’échantillons permettant de créer une fausse identité. Au lieu de nous protéger, la biométrie forcera les malfaiteurs à attaquer physiquement les individus, avec la part de violence que cela peut engendrer.
Je me base ici sur les chiffres fournis par les constructeurs ou intégrateur de systèmes biométriques (tels qu’Apple, Samsung9 ou ZTE10). Apple indique que le taux d’erreur de son système de biométrie (EER) par empreinte est de l’ordre de 1 pour 50 000. Pour Fujitsu, qui équipe le ZTE, ce taux est meilleur puisqu’il est de 1 pour 250 000.
Un petit rappel : un mot de passe ne comprenant que des lettres (majuscules et minuscules) et faisant 8 caractères de long, on est à 1 pour 218 340 105 584 896. C’est donc 200 millions de fois plus complexe qu’un scan de l’iris.
A contrario, un code PIN sur 5 chiffres donne 1 pour 100 000, sachant qu’un code PIN peut être répudié. Donc un scan de l’iris est comparable à un code PIN de 5 chiffres, en moins bien (car impossible à répudier). Côté Apple, le lecteur d’empreinte Apple donné 1 pour 50 00011 n’équivaut donc qu’à un code PIN de 4 chiffres (je me répète : en moins bien, car impossible à répudier).
Donc contrairement aux discours commerciaux comme ceux de ZTE, ça n’est absolument pas en termes de sécurité qu’il faut voir les choses mais en termes de confort et d’expérience utilisateur12.
La réponse est : non, tout va bien. Enfin presque. Normalement. Dans l’état actuel de la technologie. Rassurant, non ?
Oui, car il faut tempérer les propos rassurants comme suite à l’affaire de vol de données confidentielles de l’OPM13 : après quelques investigations, ils se rendent compte que ça n’est pas 1 mais 5 millions d’empreintes qui sont dans la nature 14, mais qu’heureusement il est difficile d’en faire quelque chose… dans l’état actuel des technologies…

Par chance, le gouvernement américain reviendra vers les victimes si, dans le futur, cela devenait possible. Comme vous le voyez, la biométrie des empreintes digitales est une technique sûre !
Un petit rappel : si une donnée biométrique est compromise (par exemple votre empreinte), non seulement c’est à vie mais également sur tous les autres dispositifs utilisant cette empreinte. Dire qu’on conseille de ne pas réutiliser le même mot de passe sur différents sites, avec une empreinte (ou n’importe quelle donnée biométrique), vous l’utilisez partout à l’identique !
Or où peut-on trouver facilement l’original d’une empreinte utilisée pour déverrouiller un smartphone ?
En tant que technologie intermédiaire, c’est plus risqué. Cela dit, il faut que le pirate puisse enregistrer votre voix, de préférence lorsque vous prononcez la phrase servant à l’authentification. Et encore, les systèmes de reconnaissance ont des mécanismes anti-rejeu. Enfin, parfois. A moins que… A moins qu’on puisse à partir d’échantillons divers de votre voix reconstruire la phrase qu’on veut. Mais ça, c’est de la science-fiction15. Et je ne parle même pas des frères jumeaux16 !
Ayé, c’est fait : le CCC a réussi à en faire son affaire17…
Alouette. Maintenant (2018) on peut déverrouiller son smartphone en montrant sa tronche. Il va donc falloir se promener cagoulé pour éviter la compromission de mon moyen d’authentification.
Une solution idéale en biométrie serait de pouvoir révoquer la donnée biométrique utilisée. Or les quelques propositions qu’ont trouve dans la nature n’évoquent que la révocation des minuties stockées, et non de la donnée de base. De plus, la sécurité du stockage est trop souvent perfectible, et quoi qu’il en soit ce stockage sera toujours attaquable.
Voir https://hal.archives-ouvertes.fr/hal-01591593/document
Il me semble que pour l’instant c’est pire chez les autres, et pas trop mal chez nous, les petits zeuropéens protégés un peu par le RGPD.
On ne peut pas gérer la sécurité informatique d’une entreprise de la même façon qu’un particulier, de façon évidente. Difficile également de faire le tour du sujet en une seule rubrique, mais certains grands principes et grandes questions reviendront dans tous les services ayant à traiter de SSI.
Continuer la lectureL’intelligence artificielle est un concept nouveau depuis 30 50 ans (mince, c’est encore plus vieux que je ne le pense). Quand j’ai commencé l’informatique, on parlait déjà d’intelligence artificielle, et déjà on était déçu des résultats, au point que l’acronyme IA se trouvait souvent remplacé par Informatique Avancée qui correspondait mieux à la nature profonde du sujet. Le marketing ou nos peurs primaires nous empêchent souvent de bien comprendre ce que recoupe cette notion d’intelligence artificielle. Mais parler d’intelligence artificielle est nettement plus vendeur que de parler de classification automatique de motifs complexes1.
Le Règlement Général sur la Protection des Données est un règlement européen sur la protection des données. Amis de La Palice, bonjour. Mais encore ? Je vais faire un résumé de la très bonne explication fournie par NextInpact sur le sujet.
Continuer la lectureFIDO est une alliance créée (en 2012) à l’origine par PayPal et quelques autres acteurs afin d’essayer d’établir un protocole d’authentification sans mot de passe.
Dès 2013, Google, Yubico et NXP1 s’y joignent pour répondre à une problématique forte chez Google de lutte contre le phishing. Pour cela, l’industrie avait besoin d’un standard pour une authentification « forte », et très vite l’idée d’un facteur matériel a été présentée par ces acteurs, avec un protocole ouvert et donc utilisable par tous.
L’acronyme FIDO correspond à Fast IDentity Online, ce qui souligne bien l’orientation web des protocoles. Les grandes étapes historiques de cette alliance sont ici.
Le besoin initial était de renforcer l’authentification sur des services web ; il était donc naturel d’introduire un second facteur en complément du mot de passe. Fin 2014, les normes FIDO UAF et FIDO U2F sont publiées simultanément.
UAF correspond à Universal Authentication Framework, qui propose un protocole d’authentification sans mot de passe, à base de cryptographie.
U2F est la norme concernant le second facteur d’authentification, ou Universal 2nd Factor en anglais, également à base de cryptographie.
Grâce à ces normes, on garantit la valeur de l’authentification puisqu’on sait comment cette dernière est établie. Garantir ne signifie pas que l’authentification est parfaite mais qu’on en connaît les mécanismes, et qu’on peut ainsi gérer correctement le risque associé.
En bonus, une certification peut ainsi être réalisée sur les dispositifs concernés : en utilisant un dispositif FIDO, on sait donc parfaitement comment ce dernier fonctionne. Par la suite, les travaux concernant la certification vont continuer pour suivre l’évolution des technologies et l’accompagner.
Des travaux viendront compléter ces premières normes, en standardisant les échanges via Bluetooth et NFC, en incluant la biométrie, etc.
En 2016, l’alliance poursuit son travail avec un objectif ambitieux, à savoir créer une norme reconnue pour l’authentification forte sur internet (sur le web).
Pour cela, l’alliance pouvait se baser sur les travaux de la première norme et en 2018 le protocole fut intégré comme candidate recommandation par le W3C, ouvrant la porte à la reconnaissance en tant que standard international de ce qui était en train de devenir FIDO2.
FIDO2 est un ensemble de spécifications, comprenant deux parties :
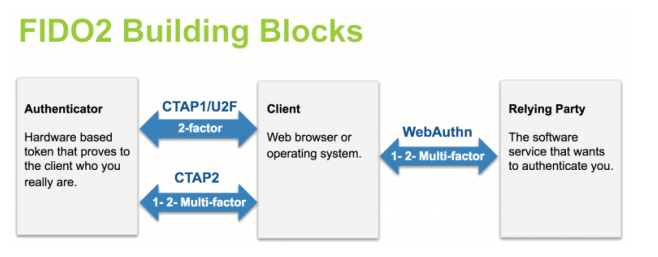
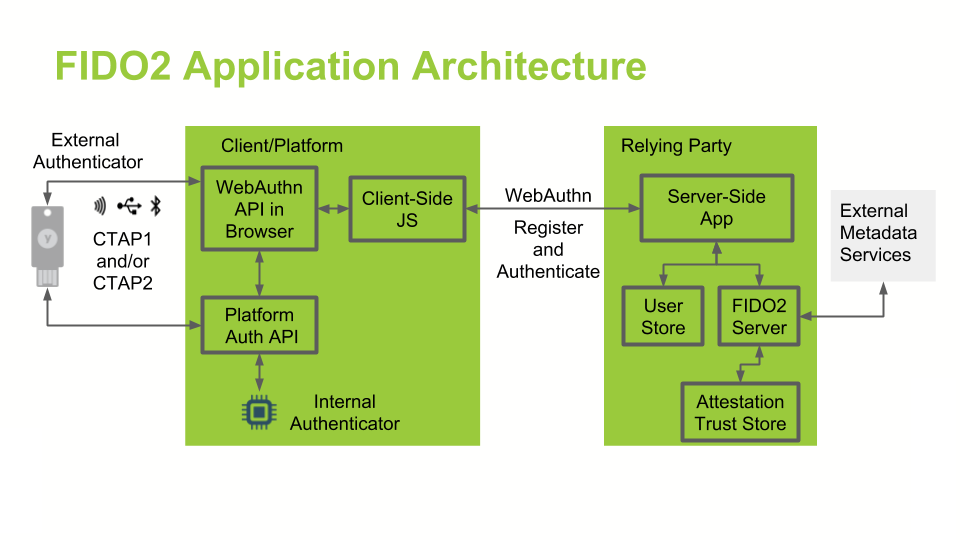
FIDO utilise un mécanisme cryptographique pour assurer l’authentification à un site. Chaque authentifiant est unique pour chaque site, le secret ne quittant jamais le dispositif FIDO.
La facilité d’utilisation provient du dispositif FIDO lui-même, qui gère la partie cryptographique avec le site web. L’authentification sur le dispositif lui-même peut être celui que le client désire (parmi ce qui existe), et est réalisée localement, sans échange avec le serveur web.
FIDO versions 1 et 2 permettent plusieurs types d’authentification, en combinant les différentes possibilités. En ce ce qui concerne FIDO2 :
Les dispositifs FIDO2 sont également rétro-compatibles avec l’authentification FIDO U2F :
Voici quelques commandes utiles pour openssl et la manipulation de certificats.
Continuer la lectureLes principe des serverless functions (fonctions sans serveur) consiste à mettre à disposition, pour un client, un environnement d’exécution géré par l’hébergeur (et non par le client) permettant de faire tourner un script ou programme ayant une durée de vie assez courte, par exemple en réponse à un événement quelconque.
Continuer la lectureLe mot de passe est un élément extrêmement sensible dans la chaîne de la sécurité. C’est le point faible le plus souvent rencontré et, forcément, le plus souvent utilisé pour les piratages et les actes malveillants. Il ne sert à rien de sécuriser sa connexion SSH si vous laissez un mot de passe faible…
Continuer la lectureLinux is not Unix. Or Linux tend à se répandre un peu partout alors que, n’en déplaise à son créateur, il n’a pas forcément été conçu sur des bases suffisamment sûres pour les entreprises1.
Le concept de villes connectées (ou Smart Cities) est un des nébuleux concepts issus de l’imagination débridée de nos têtes plus ou moins pensantes. Elles seront alimentées par nos équipements informatiques et par une foultitude de capteurs qui seront inévitablement disseminés dans notre environnement urbain (mais pourquoi pas aussi dans des zones moins denses) : des objets connectés dédiés au fonctionnement de la ville.
Or nos brillants techniciens sont plus enclins à étudier comment réaliser et rendre possible cette idée plutôt que de penser aux conséquences de cette utilisation ultra-intrusive de données récoltées1, lesquelles échapperont probablement au contrôle des citoyens.
De très loin, même. Sans refaire l’historique des vulnérabilités, on remarque que les chercheurs (comme ceux d’IBM2)relèvent que les plus basiques sont présentes quasiment partout, aussi bien dans des capteurs météo que dans des feux tricolores de signalisation !
Et je te mets un mot de passe administrateur codé en dur (et facilement devinable), que je ne sécurise pas ma couche d’authentification, que je laisse passer les injections SQL (voir ce que ça donne pour les machines à voter électroniques) ou le XSS.
Les scénarios de risque ressemblent à ce qu’on trouve dans les films3 : on détourne l’usage des feux rouges pour bloquer la circulation et échapper aux flics, on fausse les mesures d’éléments critiques comme la niveau des eaux ou le taux de radioactivité, pour causer des dégâts ou désorganiser les activités humaines.
SGX est un système d’enclave sécurisé présent au sein de certains processeurs Intel, spécialement conçus pour être plus sécurisés.
Continuer la lectureNos smartphones sont-ils sûrs ? Je suis persuadé que la plupart des utilisateurs pensent que oui, particulièrement les afficionados d’Apple qui ont entendu dire (et donc sont persuadés) qu’iOS et Mac OS sont insensibles voire invulnérables aux virus et autres malwares.
Or malheureusement il n’en est rien, je renvoie iOS et Android dos-à-dos, surtout lorsque les utilisateurs débrident (débloquent) leur téléphone à des fins de personnalisation. A ce titre voici les principales, recensées par l’éditeur Checkpoint.
Je ne regarderai ici que le point de vue technique, et non fonctionnel, car nos smartphones sont nos pires ennemis au sujet de notre vie privée (et même professionnelle), en dévoilant par le biais de notre usage une énorme partie de notre vie.
Cette opération consiste à faire sauter les contrôles de votre téléphone et de vous donner, consciemment ou non, un accès complet à celui-ci. Avec un niveau élevé de privilèges, vous pouvez devenir administrateur (= grand chef) de votre machine et y faire ce que vous voulez. En bien ou en mal. C’est amusant pour installer des applications qu’Apple a refusé. Donc ok vous pourrez personnaliser votre écran d’accueil et télécharger toutes les applications pornos que vous souhaitez (par exemple sur Cydia), mais rien n’arrêtera les programmes malveillants qui n’en demandent pas tant… D’abord ils pourront s’installer facilement, mais en plus ils pourront ensuite faire ce qu’ils veulent. Exemple : installer un RAT ou un outil cherchant à cacher que votre téléphone est jailbreaké…
Votre iPhone peut être totalement contrôlé par un inconnu, sans que vous ne le sachiez. Le principe est qu’une fois un iPhone jailbreaké, il devient possible d’installer tout et n’importe quoi dessus, et donc pas seulement les applications vérifiées par Apple sur son store. L’attaquant se débrouille pour installer son malware ou son RAT .
A quoi bon faire de faux certificats ? Pour tromper son monde ! Si un petit malin arrive à se faire passer pour une entreprise réputée qui publie de nombreuses applications légitimes sur le store d’Apple, il arrivera alors facilement à faire passer son programme à lui, voire à l’intégrer dans un programme légitime.
D’où l’importance de vérifier correctement les certificats, afin d’être sûr de qui les publie et les utilise. Cela peut représenter une somme de travail importante dans le cas des magasins d’applications, où des centaines d’applications sont publiées.
Pfou, un titre incompréhensible au premier abord. Les attaques MITM consistent à ce qu’un tiers vienne se placer au milieu d’une conversation en principe sécurisée. Ce type d’attaque se voit sur les réseaux Wifi mal sécurisés (ou non sécurisés). On peut théoriquement éviter cela avec un utilisateur au faîte du sujet et très vigilant. Et disposant d’un smartphone qui lui permette de contrôler visuellement certains éléments (comme les certificats).
Les webkits ne sont pas de méchants programmes : ce sont des outils que les navigateurs internet utilisent pour construire visuellement le résultat de votre navigation (afficher et positionner le texte, les images, etc.). Très utilisés, la moindre faille est critique. Une d’entre elles permettait, par exemple, d’effectuer le jailbreak de son iPhone rien qu’en visitant une page web spécialement construite à cet effet.
Pour moi, un 0-day (ou faille 0-day) est une faille non corrigée dans une application. Qu’elle soit connue ou pas importe peu.
Une attaque 0-day est une attaque utilisant… une faille 0-day. Pourquoi est-grave ? Voir ci-dessus : parce qu’elle est non corrigée. Donc un petit malin se sert de cette faille, et personne ne peut l’arrêter. Il existe un commerce de ces failles : la cybercriminalité est devenue une industrie.
La plupart des fabricants de smartphones proposent des services de stockage en ligne. Il faut garder à l’esprit qu’ils sont souvent opérés par des tiers, et que leur mise en œuvre peut être plus ou moins bien faite, sans compter les risques inhérents à l’usage de services en ligne. Savez-vous par exemple qu’Apple utilise Amazon (AWS), Microsoft (Azure) ou Google (GCP) pour son service iCloud1 ?
Checkpoint ne mentionne pas pour Android les webkits (je ne vois pas pourquoi) ni les profils iOS malicieux (là j’ai une petite idée). Sinon, à défaut d’être identiquement exploitées (d’un point de vue purement technique), les menaces sont très similaires d’un point de vue conceptuel. La pomme n’est pas plus sûre que les bonbons.
Toutefois, certaines caractéristiques desservent Android, comme par exemple le nombre d’applications publiées (supérieur à iOS2), le fractionnement des versions du système d’exploitation et l’ouverture complète du système qui permet aux constructeurs et opérateurs de proposer des services et des programmes dont le niveau de sécurité peut être très hétérogène. Quand à la maintenance des programmes et versions d’OS, elle est à la main des mêmes constructeurs et opérateurs, donc la rigueur de gestion diffère (quand il n’y a pas carrément d’impossibilité technique à prendre en compte certains correctifs de sécurité).
Enfin, il est très facile sous Android de se connecter à des magasins d’applications non contrôlés, portes ouvertes aux programmes malveillants.
Sujet intéressant ! Les mentions légales de ce site sont ici.
https://www.service-public.fr/professionnels-entreprises/vosdroits/F31228
Que dit la loi ? https://www.cnil.fr/fr/cookies-traceurs-que-dit-la-loi
Voir aussi https://github.com/LINCnil/CookieViz/releases pour les cookies !
Cloud Act est l’acronyme de Clarifying Lawful Overseas Use of Data Act. Trop forts ces ricains pour les acronymes (presque aussi bien que Patriot Act). A l’instar du Patriot Act, ou dans le même esprit que le RGPD, il devrait permettre une collaboration plus facile dans les requêtes judiciaires.
Continuer la lectureLe terme objets connectés me semble plus approprié que l‘internet des objets, qui prend les choses dans le mauvais sens en partant d’internet pour arriver aux objets, et qui est également trop limitatif car le vrai enjeu n’est pas tant d’être sur internet que d’être relié à d’autres objets.
Le ‘S’ dans IOT c’est pour « Sécurité ».
Blague anonyme
Les objets connectés existent depuis longtemps, sur l’échelle de temps informatique. Un ordinateur ou un serveur informatique étant des objets, il y a belle lurette que la connexion est faite. Le vrai changement est qu’en suivant la vague de miniaturisation et de banalisation des composants informatiques, on peut désormais coller partout ces composants, jusque dans votre pacemaker12, permettant notamment des fonctions évoluées mais aussi de la communication avec d’autres objets, sur internet ou pas.
Cela concourt selon moi à rendre ces objets menaçants, car comme souvent toujours en informatique, la sécurité n’a été abordée qu’après coup, car le bénéfice immédiat (réel) a souvent coupé court à toute autre réflexion.
Difficile de penser qu’on arrivera facilement à un niveau de sécurité acceptable dans le monde des objets connectés, car la multiplicité des acteurs3 et leur féroce concurrence commerciale, le manque de culture sécurité et le coût nécessaires à cette sécurisation sont des freins puissants sur le chemin de cet objectif. Quant aux mauvaises habitudes, elles perdurent et les mots de passe par défaut continueront à nous jouer des tours, jusqu’à transformer un aspirateur45 en espion (puisque les aspirateurs automatiques ont des caméras pour se diriger).
Que n’ai-je entendu que j’étais un râleur patenté, un pessimiste né, un rétrograde primaire, tout ça parce que je pestais (et peste encore) contre l’innovation bête et stupide, ainsi que sa glorification béate (toute comme pour les start-up) sans prise de conscience de l’ensemble des enjeux liés à ladite innovation.
A partir du moment où votre aspirateur5 devient un objet connecté, attendez vous au pire. Toute caméra peut devenir un espion potentiel. Donc tout objet connecté, même anodin, peut recueillir (et donc transmettre) plein d’informations vous concernant, et à l’ère du big data, l’utilisation qu’on peut en faire est quasiment infinie.
Des chercheurs ont même réussi à transformer un aspirateur-robot en centre d’écoute : ils ont détourné l’usage du « lidar » (le radar dont se sert le robot pour se déplacer) pour capter les vibrations sonores sur les surfaces rencontrées6, et en déduire les conversations. Seul élément rassurant : vous parlez beaucoup, quand l’aspirateur marche ?
Cela fait beaucoup moins rire de parler du danger des connexions dans les avions que pour les réfrigérateurs : autant un frigo qui envoie du spam ou qui commande une pizza, cela prête à sourire, autant la perspective d’un avion qui s’écrase fait froid dans le dos. Or dans objets connectés il y a aussi avions connectés. Et le département de la sécurité intérieure aux Etats-Unis nous dit que ce n’est qu’une question de temps7 avant qu’un avion ne soit piraté, avec les conséquences catastrophiques que l’on peut imaginer. Ils ont réussi à la faire avec un Boeing 737, on peut voir une analyse de risque ici.
Entre les scooters électriques (ou les vélos) en libre-service qu’il faut suivre pour leur entretien, ou les voitures se conduisant toutes seules, les interactions informatiques sont forcément très nombreuses. Donc récolte de données à gogo8 et réutilisation par toujours contrôlée, surtout en cas de faille.
Un autre exemple ? Volontiers : les trottinettes Xiami M365 peuvent être (au moins partiellement) contrôlées par un pirate9, qui peut agir sur le freinage ou l’accélération avec les conséquences qu’on peut imaginer.
Parfois on trouve des failles non seulement dans les objets connectés, mais aussi dans les centrales électroniques censées les contrôler. En gros, si par extraordinaire vous utilisez un objet connecté non troué (= non vulnérable), alors il faudra vérifier que votre hub10 soit également bien protégé.
Puisqu’il est si facile de prendre le contrôle d’un grand nombre de machines informatiques reliées à internet, les objets connectés sont tout naturellement d’excellents candidats pour construire un réseau de machines zombies (botnet). Et les méchants ne s’en privent pas. Les objets connectés piratables, zombifiables et contrôlables à souhait sont du pain béni pour les attaques de type DDoS (déni de service) ; Mirai en a été le premier exemple marquant.
Les conséquences juridiques sont difficiles à appréhender à l’émergence d’une nouvelle technologie (ou de son expansion). Or, tout comme la sécurité, les aspects juridiques sont trop souvent négligés11, et ça n’est qu’au moment d’une catastrophe, d’une attaque ou d’un litige qu’on se rend compte qu’on ne maîtrise ni la situation technique ni les conséquences juridiques (et judiciaires) de cette technologie.
Étonnamment, malgré des alertes renouvelées et argumentées, malgré des compromissions, les fabricants d’objets connectés continuent leur déni12 et la situation ne s’améliore absolument pas. En cause, toujours les mêmes facteurs :
Une étude de Palo Alto Networks13 enfonce le clou : sur le million d’objets connectés étudiés, 98% des flux réseaux circulent en clair, avec les risques de fuite d’information et de détournement associés, 57% sont vulnérables à des attaques ayant des impacts moyens ou élevés, dans l’industrie et les milieux hospitaliers, les objets vulnérables sont sur les mêmes VLAN que les dispositifs traditionnels, les mots de passe sont majoritairement faibles voire encore triviaux, etc.
The Internet of Things is a security nightmare reveals latest real-world analysis: unencrypted traffic, network crossover, vulnerable OSes
Sources
theregister.co.uk
Une autre étude de Zscaler14 est moins pessimiste, mais pas plus rassurante pour autant : seules 17% des « transactions » sont chiffrées. Cela s’explique probablement par un panel d’étude différent, avec d’autres usages et donc d’autres types de machines, mais ça reste pas beaucoup…
La défense semble une posture normale pour tout entité, vivante ou organisationnelle. Il va de soi qu’un Etat va chercher à se défendre et à défendre ses concitoyens, tout comme n’importe quel individu. L’attaque dépend d’autres facteurs, et cette capacité a longtemps eu une place à part en informatique, car cela a toujours été considéré comme l’apanage des méchants. L’informatique était considérée comme un outil de production, qu’il fallait protéger et garder en état de marche.
Continuer la lectureApplication, gestion des fichiers
Just like files that you save on the device’s internal storage, Android stores your database in private disk space that’s associated application. Your data is secure, because by default this area is not accessible to other applications.
Cependant, si on ne suit pas les bonnes pratiques, notamment lors du stockage de données sur des supports externes à l’OS (genre carte SD), les données deviennent vite accessibles pour des intrus1.
Une des choses que je reproche le plus à Android est la fragmentation des versions de l’OS, ce qui se comprend par la difficulté d’intégration de tous les acteurs (fabricants de composants et puces, fabricants de smartphones, opérateurs téléphoniques) qui devaient chacun revoir leur copie à chaque mise à jour d’Android, ce qui fait que beaucoup traînaient les pieds ou ne le faisaient carrément pas. Or un OS viable est un OS à jour !
Depuis Android 8.0, toutes les parties spécifiques que les acteurs précédents devaient modifier a été séparée (logiquement) de l’OS. L’avantage indéniable de la manœuvre est de laisser le code spécifique à part, sans avoir besoin de le retravailler2. Il « suffit » donc de mettre à jour l’OS, pour un téléphone donné, afin d’avoir les derniers correctifs : le travail est du côté de Google, pas des acteurs intervenant par la suite (fondeurs de puces, constructeurs de téléphone et opérateurs).
Une autre option pour avoir un système à jour est justement de n’utiliser aucune personnalisation du téléphone, en respectant certains critères documentés par Google3. Au final, on aura un téléphone moins personnalisé (personnellement ça m’importe peu) mais surtout suivant (ou plutôt : pouvant suivre) les mises-à-jour Android sans aucun souci.
Google propose même de labelliser les téléphones respectant les critères Android One ; et je ne vois pas l’intérêt qu’aurait un constructeur à s’embêter à être Android One pour ne pas suivre le train des mises-à-jour de l’OS !