L’intelligence artificielle est un concept nouveau depuis 30 50 ans (mince, c’est encore plus vieux que je ne le pense). Quand j’ai commencé l’informatique, on parlait déjà d’intelligence artificielle, et déjà on était déçu des résultats, au point que l’acronyme IA se trouvait souvent remplacé par Informatique Avancée qui correspondait mieux à la nature profonde du sujet. Le marketing ou nos peurs primaires nous empêchent souvent de bien comprendre ce que recoupe cette notion d’intelligence artificielle. Mais parler d’intelligence artificielle est nettement plus vendeur que de parler de classification automatique de motifs complexes1.
As soon as it works, no one calls it AI any more.
John McCarthy
Démystifions
[…] la présentation à outrance du moindre outil de calcul comme un outil d’intelligence artificielle nous détourne de ce que nous pouvons accomplir, tout comme une décennie passée à vanter les mérites des startups nous a détournés de l’objectif de créer des entreprises capables de survivre2.
Luis Perez Breva, MIT
Test de Türing
Calculateur
Autrefois, nous avions la donnée qui suivait scrupuleusement le chemin tracé par l’algorithme, selon un procédé qualifié de déterministe : une même donnée en entrée du même algorithme produira toujours le même résultat.
Avec l’IA, on est plutôt dans le sens inverse : l’algorithme suit la donnée et l’enrichit. Ainsi, même si on utilise un ordinateur, machine hautement déterministe, on se retrouve face à un processus qui devient non-déterministe, principalement parce qu’il est quasi-impossible de repartir du même jeu de données initial, car le but principal de l’IA est d’interpréter les données, de les qualifier, de les enrichir, de les classer, etc.
Prise de décision ?
Non, techniquement, l’apparente décision n’est qu’un choix (ou un classement), basé sur des données acquises et une programmation, parfois issu de calculs extrêmement complexes et dépassant largement les capacités humaines. Il n’y a pas de place pour les sentiments, l’erreur, ou la véritable intuition, un système d’IA ne fait que du calcul ou du classement. Contre-exemple de ce que je peux faire : je peux choisir la pire des solutions pour moi ou mon entreprise au profit d’un client parce qu’il m’est personnellement sympathique (empathie).
Traçabilité
Un des enjeux essentiels désormais dans l’IA est son niveau de traçabilité. Certains appellent ça interprétabilité ou explicabilité, à tort car cela n’existe pas en français, mais l’idée est là : on doit être capable de savoir pourquoi un système d’IA a fait tel ou tel choix.
Côté RGPD, on indique même que toute décision importante ou ayant une conséquence juridique doit pouvoir être expliquée et donc tracée. Et toute personne concernée doit pouvoir demander une intervention humaine en cas de contestation.
De mémoire, la CNIL demandait même qu’aucun automate ne doit pouvoir prendre de décision ayant un impact juridique ; ça explique pourquoi même lorsqu’on se fait flasher par un radar automatique lors d’un excès de vitesse, il y a toujours un policier qui signe le procès-verbal d’infraction.
Le problème vient des capacités de calculs de ces systèmes : il y a tellement d’éléments (données) en entrée et les séquences de décisions peuvent être si longues qu’elles sont difficilement lisibles par un être humain. Un système de Deep Learning imitant (très mal) un réseaux de neurones conduit à des calculs complexes, non linéaires, et avec de nombreux liens. Je vois mal un pauvre humain s’y retrouver3…
Le comble
La traçabilité est si complexe que c’en est un sujet de recherche. Or le problème semble si compliqué qu’aucune méthode n’émerge (en 2019) et que leur stabilité même varie d’un système à l’autre… Pourvu que ça s’arrange !
Sentiment ?
Aujourd’hui, on ne sait pas modéliser efficacement des sentiments. On peut donner du simili, mais presque par définition, le sentiment est quelque chose qu’on ne peut pas modéliser ni conceptualiser : cela échappe à toute logique.
Un agent intelligent existe-t-il ?
Non, il exhibe un comportement intelligent. Il en a l’apparence. cf Ferber 1995 ? Le terme d’intelligence artificielle est lui-même trompeur, car la plupart des systèmes s’en revendiquant ne sont en réalité que des systèmes d’apprentissage automatiques4. Ces derniers permettent de faire des choses extrêmement complexes, qu’un humain n’est pas capable de faire, mais sans réelle intelligence, avec simplement de bons algorithmes et de bonnes données (soit dit en passant, les algorithmes sont créés par les humains, et les données sélectionnées par leur soin).
Les programmes ont réussi à devenir des champions d’échec ou de go, puisqu’ils arrivent à battre n’importe quel humain (au moins pour AlphaGo), mais aucun de ces programmes ne relève de l’intelligence : ils sont extrêmement spécialisés, rapides, puissants, mais pas intelligents. Imaginons qu’on change une règle du jeu de go, la machine perdra alors les pédales !
Biaisons
Toute observation peut être sujette à des biais. On peut en avoir de deux natures :
- Soit les données sont inexactes, approximatives, car elles sont difficiles à mesurer et à obtenir ;
- Soit elles sont exactes mais elles ne sont que partiellement représentatives, car leur contexte influe sur leur valeur.
Dis ainsi, ça peut paraître théorique (et rhétorique). Pourtant, si vous mesurez le taux d’humidité dans le désert (même si le désert est gigantesque et vos points de mesures nombreux), vous ne mesurez que des valeurs correspondant au désert. Si par la suite vous demandez à un algorithme d’IA ou de tout ce qu’on veut de déduire un modèle météo en fonction de ces mesures, vous serez incapables d’avoir un résultat correct si vous appliquez le même algorithme dans une zone tempérée. Ballot.
Plus grave : si vos mesures représentent des choix et des décisions humaines, vous risquez de les reproduire dans votre algorithme. Dans un article des Echos consacré au sujet5, on nous apprend que les algorithmes ont beau être vérifiables, ils peuvent quand même produire des réponses inappropriées en raison d’un biais existant dans le système. Les optimistes nous diront qu’heureusement on peut le corriger ; oui, tout à fait, mais qui peut le faire ? Pas l’algorithme lui-même, car il a travaillé conformément aux données dont il disposait.
Biais connus dans des systèmes existants :
- Recrutement Amazon (sources ?)
- Algorithme de reconnaissance visuelle Google6
- Fiasco de l’agent Microsoft7
Le biais du survivant
Amusons-nous à biaiser : voici un concept intéressant, le biais du survivant, qui s’applique à beaucoup de domaines et qui explique également un des risques de la donnée non interprétée.
Durant la seconde guerre mondiale, on a cherché à protéger les bombardiers alliées de tirs allemands. On a alors étudié l’endroit où les impacts se trouvaient pour renforcer le blindage à ces endroits.
Sur les bombardiers qu’on a étudié, les zones touchées sont les ponts rouges. La première approche est de dire qu’il faut renforcer le blindage à ces endroits, statistiquement plus touchés. Or c’est précisément là qu’intervient le biais : les bombardiers étudiés sont les survivants, ne couvrant qu’une partie de la réalité. Car tous les avions touchés sur la cabine de pilotage ou les moteurs ne sont pas rentrés, et ont été détruits.
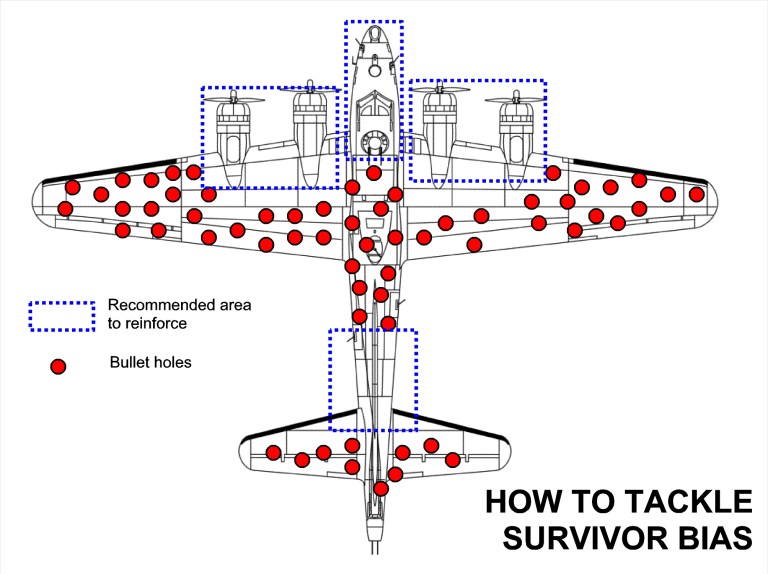
Ce biais a par la suite été nommé biais du survivant, après les travaux d’un statisticien hongrois, Abraham Wald.
Source : https://blog.goood.com/2019/12/11/le-biais-du-survivant-et-la-recette-agile/
Contre-biaisons
cf IBM
Déraillons
- Sexiste, homophobe, anti-handicapés… Un chatbot sud-coréen mis hors-ligne après avoir déraillé (bfmtv.com)
- Microsoft fait taire Tay, son intelligence artificielle… devenue raciste (bfmtv.com)
Que penser ?
D’une part qu’il est illusoire de penser qu’une IA ou un algorithme, à partir du moment où la complexité et le nombre de données en entrée grandissent, puissent donner un résultat ou une représentation objective et indiscutable5.
D’autre part, même avec une conception parfaite et poussée, tout résultat reste sensible à une interprétation, qu’aucune machine n’est capable de faire pour le moment.
Spécialisation
Les algorithmes sont spécialisés. Interpréter, juger, évaluer risque d’être impossible tant les ordinateurs ne seront pas en nous.
Exemple criant : les problèmes de Facebook8 pour supprimer les contenus terroristes, et donc les problèmes de modération automatique. Il est en effet plus facile de classifier une image où on voit un bout de sein qu’une vidéo d’un mec en train de tirer dans la foule en direct.
Ethique
Problème crucial9.
Voir aussi les recommandations de l’armée américaine quant à l’usage d’intelligence artificielle sur une zone de combat.
Robots
A rapprocher de singularité10.
Singularité
Doit-on redouter que les machines surpassent l’homme ? Gardons un peu l’espoir :
[…] les ordinateurs et logiciels actuels n’ont ni culture sociale, politique ou artistique, ni intuition, ni vraie créativité4. (Gérard Berry, professeur au Collège de France)
L’intelligence artificielle en sécurité informatique
L’IA peut venir aider à plusieurs niveaux (reconnaissance, analyse, prospective). Mais si un gentil peut l’utiliser pour se défendre, un méchant peut aussi l’utiliser à son avantage.
Sources
- https://www.msn.com/fr-fr/actualite/technologie-digital/cyberattaques-fausses-vidéos-un-rapport-alerte-sur-le-potentiel-de-lintelligence-artificielle/ar-BBJpXjm?ocid=spartandhp
- http://www.zdnet.fr/actualites/intelligence-artificielle-les-scientifiques-tirent-la-sonnette-d-alarme-39864502.htm
- https://www.20minutes.fr/sciences/2224627-20180221-intelligence-artificielle-pourrait-tomber-entre-mauvaises-mains-avertissent-experts
- https://www.reuters.com/article/us-cyber-tech/artificial-intelligence-poses-risks-of-misuse-by-hackers-researchers-say-idUSKCN1G503V
- https://fr.sputniknews.com/societe/201804291036157311-google-ia-danger/ (crédibilité ?)
- http://www.lemonde.fr/pixels/article/2018/04/05/intelligence-artificielle-3-100-employes-pressent-google-d-arreter-d-aider-le-pentagone_5281180_4408996.html
- https://abc.xyz/investor/founders-letters/2017/index.html
- https://www.linkedin.com/pulse/la-vision-actuelle-de-lia-ou-le-syndrôme-hal-pierre-jean-benghozi/
- Machine learning et confidentialité : https://medium.com/tensorflow/introducing-tensorflow-privacy-learning-with-differential-privacy-for-training-data-b143c5e801b6
- Inquiétant : détournements possibles (https://threatpost.com/machine-learning-dark-side/142616/)
- Sécuriser l’IA aujourd’hui… pour ne pas le regretter demain
- Comment l’IA pourrait faciliter les fraudes à l’assurance dans la santé
- Pourquoi Facebook arrive mieux à supprimer les photos de seins que les vidéos terroristes
- CNRS https://lejournal.cnrs.fr/billets/robotique-et-intelligence-artificielle-parlons-en
- https://www.blogdumoderateur.com/intelligence-artificielle-existe-pas/?
- https://www.lemagit.fr/actualites/252477780/IA-Souvent-ce-quon-appelle-Big-Data-ca-nexiste-pas
- John McCarthy | blog@CACM | Communications of the ACM
- Becoming Elon Musk – the Danger of Artificial Intelligence | SecurityWeek.Com
Publications
- https://img1.wsimg.com/blobby/go/3d82daa4-97fe-4096-9c6b-376b92c619de/downloads/1c6q2kc4v_50335.pdf
- https://foresight.org/publications/AGI-Timeframes&PolicyWhitePaper.pdf
- https://www.cnil.fr/sites/default/files/atoms/files/cnil_rapport_garder_la_main_web.pdf
- https://www.lexpress.fr/actualite/sciences/pourquoi-il-faut-un-droit-des-robots_2018912.html
- https://www.lexpress.fr/actualite/sciences/l-intelligence-artificielle-n-est-pas-intelligente_2024279.html
- https://www.darkreading.com/endpoint/5-emerging-trends-in-cybercrime/a/d-id/1333363