L’intelligence artificielle est un concept nouveau depuis 30 50 ans (mince, c’est encore plus vieux que je ne le pense). Quand j’ai commencé l’informatique, on parlait déjà d’intelligence artificielle, et déjà on était déçu des résultats, au point que l’acronyme IA se trouvait souvent remplacé par Informatique Avancée qui correspondait mieux à la nature profonde du sujet. Le marketing ou nos peurs primaires nous empêchent souvent de bien comprendre ce que recoupe cette notion d’intelligence artificielle. Mais parler d’intelligence artificielle est nettement plus vendeur que de parler de classification automatique de motifs complexes1.
Archives de catégorie : Attaques
SuperFish
SuperFish est un outil publicitaire qui a défrayé la chronique en février 2015. Sa principale fonction était de délivrer de la publicité ciblée, en analysant le trafic réseau de l’ordinateur où il est installé. Le problème est qu’il est aussi capable de déchiffrer les communications théoriquement sécurisées (par SSL ou TLS), via des techniques de type man-in-the-middle. Il a été installé sur de nombreux ordinateurs Lenovo.
Epilogue
Uber
Sacré Uber ! A leur sujet, je balance entre les pires des filous et les meilleurs bidouilleurs dans leur genre. Après une sombre histoire de batteries, les revoici encore pour nous montrer que leurs développeurs (ou ses cadres de vente) ont de sacrées idées !
L’histoire de la batterie
Tout çà ne serait qu’une boutade : Uber jure que l’information n’est pas utilisée pour de vrai. Avec des explications un peu confuses, on apprend sur le site npr.org1 que le chef marketing d’Uber a constaté que ses clients seraient enclins à payer plus cher une course quand leur smartphone est à court de batterie. On le comprend aisément : quand le téléphone va lâcher, on manque de temps pour faire sa réservation donc on accepte plus facilement ce qui est proposé2.
La question est : comment Uber sait que vous êtes à sec ? Simple : cela fait partie de ce qu’on peut savoir sur votre téléphone, par exemple s’il est en mode économie de batterie. Cela aide certaines applications pour continuer de fonctionner (elles peuvent ainsi désactiver des fonctions trop gourmandes en énergie), mais cela intéresse aussi le marketing. Autant le procédé est discutable, autant la trouvaille est toute en finesse.
Légal mais pas moral
Sans jeter l’opprobre sur Uber (bien que je n’apprécie pas vraiment cette société), ce subterfuge est légal mais pas très moral. Ce sont aux clients de juger, mais Uber avait déjà été interrogé sur les prix pratiqués lors d’une prise d’otages à Sidney3, où les personnes voulant s’éloigner de la zone dangereuse ont vu les prix flamber.
What’s that Hell ?
C’est pas rien, mais c’est pas tout : Uber surveillait (surveille ?) de près ses concurrents, au point de mettre au point un programme (appelé Hell4) de traçage des courses des autres sociétés, grâce à de faux clients demandant de fausses courses sur les vrais sites, afin de voir la disponibilité et les tarifs dont on peut supposer que la connaissance a pu influer sur la priorisation et le coût des courses proposées. Bilan : un procès à venir5…
C’est pas rien, mais c’est pas tout (encore). Les révélations se succèdent : Uber aurait détourné l’usage de certaines techniques pour pister les smartphones d’Apple6, afin de voir quels utilisateurs enfreignaient la politique d’utilisation d’Uber. Certes, le but avoué publiquement est la lutte contre la fraude7, mais avec leur propre recette dirons-nous, et en enfreignant à leur tour les conditions d’utilisation de l’Apple Store8, y compris en utilisant un blocage géographique empêchant de voir le code litigieux depuis le siège d’Apple. Ce qui signifie qu’ils savaient donc très bien qu’ils étaient en dehors des clous.
Innovation ?
Uber fait preuve de grande ingéniosité et d’innovation même, pourrait-on dire. Oui, mais vu les résultats économiques peu probants910 et les procès à venir, je ne suis pas sûr que la stratégie soit la meilleure et que la multiplication des opérations à la limite de la morale vont finir par peser sur la société.
Encore des histoires
Et encore un truc pas net : des caméras qui traquent les concurrents11 pour voir où ils sont, quand ça n’est pas des clients, des chauffeurs, etc. Si tout n’est pas avéré ni confirmé par Uber (of course), rien n’empêche que ponctuellement de telles initiatives aient pu avoir cours, et qu’elles ne soient pas connues à tous les niveaux. L’employé en question semble s’être baladé en Australie et à Singapour. Le logiciel employé aussi (Surfcam).
Canaux auxiliaires
Les attaques par canaux auxiliaires (ou side channel atacks en anglais) sont des attaques très particulières1, qui utilisent les propriétés physiques ou matérielles d’un composant ou d’un microprocesseur2. Tout peut servir : la chaleur ou le rayonnement émis, le temps de réponse, la consommation electrique, etc. En général, la cible est le processus de chiffrement pour attaquer les clés servant à sécuriser la transmission de l’information.
Théorique ou pratique ?
Bien que cela semble très conceptuel, plusieurs failles liées à l’exploitation de canaux auxiliaires ont été mises au jour récemment. En 2018, Intel en a fait les frais avec Spectre et Meltdown. A peine avait-il repris sa respiration qu’une autre faille a été divulguée, encore une fois sur la prédiction de branche.
http://www.cs.ucr.edu/~nael/pubs/asplos18.pdf
Linky
Le compteur électrique dit « intelligent » est un objet connecté qui est un très bon exemple d’exploitation de canaux auxiliaires pour déduire des informations personnelles à partir de mesures physiques (l’intensité du courant principalement).
Le distributeur d’électricité vous vante de pouvoir vous fournir un service adapté, ainsi que des offres les plus compétitives pour vous. Mais comment arrive-t-il à cela ? En récupérant de très nombreuses mesures au niveau de votre habitation, jusqu’à toutes les demi-heures3 ! On peut ainsi, de façon indirecte, en déduire beaucoup de choses sur vos habitudes, votre présence à votre domicile ainsi que votre activité. Et personnellement je ne le souhaite pas, et je n’ai pas non plus besoin de ce service qui est en plus difficile (et même interdit) de refuser4.
La CNIL s’est penchée sur le compteur5, sans rien trouver à redire, à part quelques conseils et éclaircissements. Les informations les plus détaillées (ou plus précisément celles relevés plus souvent qu’à la journée) nécessitent l’accord explicite de l’abonné.
Objets connectés
Tout comme Linky, les objets connectés peuvent être source d’informations personnelles de façon indirecte, dès qu’ils sont en capacité de capter et mesurer des informations liées (directement ou indirectement) à l’activité d’une personne, d’un foyer ou d’un système quelconque. Un capteur de température réglant le chauffage est ainsi en mesure de savoir si un pièce est occupée ou non assez facilement.
Bibliographie
- https://fr.wikipedia.org/wiki/Attaque_par_canal_auxiliaire
- http://www.bibmath.net/crypto/index.php?action=affiche&quoi=chasseur/canalauxiliaire
- https://connect.ed-diamond.com/MISC/MISC-088/Attaques-par-canaux-auxiliaires-utilisant-les-proprietes-du-cache-CPU (payant)
- http://www.normalesup.org/~fbenhamo/files/stage2011/slides.pdf
- http://www.cs.ucr.edu/~nael/pubs/asplos18.pdf
Voir aussi
Serverless functions
Principe
Les principe des serverless functions (fonctions sans serveur) consiste à mettre à disposition, pour un client, un environnement d’exécution géré par l’hébergeur (et non par le client) permettant de faire tourner un script ou programme ayant une durée de vie assez courte, par exemple en réponse à un événement quelconque.
Continuer la lectureS3
S3 (Amazon Simple Storage Service) est un service de stockage d’objets en ligne d’Amazon Web Services (AWS). Bien que très pratique, il peut être très mal utilisé. Résultat : on assiste en ce moment à un florilège de divulgation de données via des S3 fonctionnant très bien mais mal paramétrés.
Il existe des variantes avec d’autres produits mal configurés, comme le service ElasticSearch, qui peut se révéler tout aussi fatal aux informaticiens peu consciencieux (ou débordés), ou la base MongoDB mal sécurisée par défaut.
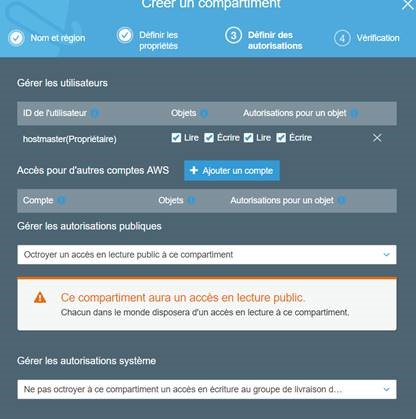
Responsabilité partagée
La presse se fait souvent l’écho de fuite d’informations liées à S3, allant parfois jusqu’à annoncer une faille sur S3. Or il s’agit d’un service d’infrastructure (IaaS), dont la sécurité est partagée entre le fournisseur d’accès et le client utilisateur du service : le fournisseur est responsable de la sécurité du cloud, le client est responsable de la sécurité dans le cloud.
Le fournisseur est responsable du bon fonctionnement du service, rien de moins mais rien de plus : il doit juste répondre au contrat de service. Par exemple, s’il y a un mécanisme d’autorisation d’accès, il doit s’assurer qu’il est efficace et qu’il fonctionne comme attendu, sans erreur, sans interruption, etc.
De l’autre côté, le client paramètre ce mécanisme d’autorisation d’accès comme il le souhaite. S’il laisse son compartiment S3 ouvert à tout vent (par erreur, par mégarde, par bêtise), c’est de sa faute.
Les failles S3, à qui la faute ?
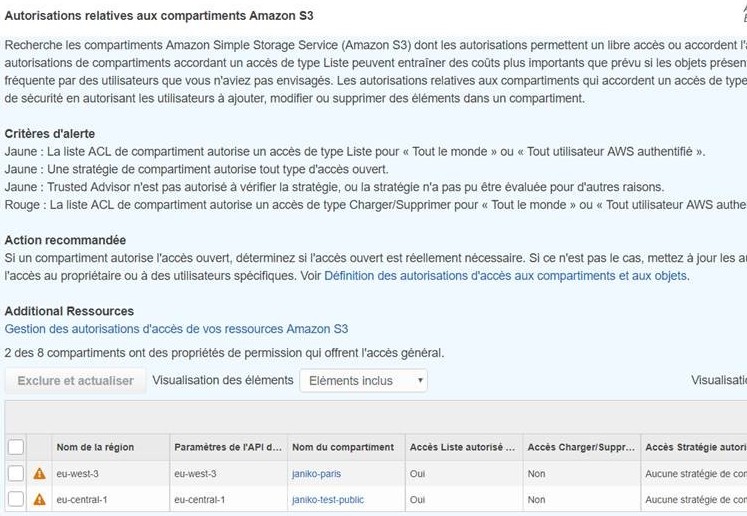
Et bien jusqu’à présent, toutes les failles sur S3 sont dues à un mauvais paramétrage par le client. Pourtant AWS indique en grand le risque encouru, lors du paramétrage.
Tant et si bien qu’à partir de février 2018, AWS ajoute gratuitement le contrôle sur les droits d’accès sur S31 dans son service Trusted Advisor (ce contrôle était jusqu’alors réservé aux clients ayant un niveau de support payant). Début 20182, on estimait que 7% des buckets S3 étaient accessibles en lecture sans restriction (ce qui est parfois voulu, pour l’hébergement d’éléments web statiques), et que 2% étaient également accessible en écriture sans contrôle (là je suis moins sûr que ça soit normal).
Aujourd’hui ?
Il faut vraiment être neuneu pour laisser un bucket ouvert : AWS a rajouté plein d’outils, de procédures, d’informations affichées pour qu’on ne se prenne plus les pieds dans le tapis.
Quelques exemples
- Mars 2018
- 1,3 millions de données client de Walmart (bijouterie) exposés3.
- Keeper, un gestionnaire de mots de passe, laisse traîner des fichiers en lecture-écriture4.
- Avril 2018
- 1,2 To de données correspondant à 48 millions de personnes, non protégées par LocalBox, une société de profilage publicitaire au profil douteux5.
- Mai 2018
- Divulgation de données de 15 ou 20 000 joueurs de cricket indiens67.
- Divulgation de données du service social de Los Angeles8.
- Mots de passe de l’application TeenSafe en clair9.
- Une société d’assurance (AgentRun) laisse des milliers de données de souscripteurs10 en accès libre
- Honda laisse à disposition les informations de 50 000 véhicules et de leur propriétaires11.
- Juillet 2018
- Août 2018
- GoDaddy, un célèbre hébergeur web, laisse des informations d’infrastructures de 24 000 machines sur un bucket S3 mal configuré14.
- Septembre 2018
- Avril 2019
- Juin 2019
- 1 Tb de données de sauvegardes (comprenant des clés privées) exposées par Attunity (qui a des clients de l’envergure de Netflix ou Ford).
La faute d’Amazon ?
Il n’y a pas qu’Amazon qui soit touché puisque la plupart des fournisseurs de services nuagiques proposent des services permettant le partage de façon publique ; on a vu que Google via Groups recelait de très nombreux documents18 qui n’ont pas à être exposés au grand public. Or les personnes ayant le rôle d’administrateur Google Groups n’ont pas toujours de hauts compétences en administration19, ce qui est normal vu le public visé par le service de Google.
Répétons : le problème ne vient pas du fournisseur de services, ni du service, mais de son utilisation.
Faut-il utiliser S3 ?
A mon humble avis, il faut l’éviter autant que faire se peut. Certes les usages potentiels sont nombreux, certains sont justifiés, d’autres non.
Hébergement de site web statique
AWS met en avant cet usage qui est parfaitement stupide. En effet, avec AWS, comme rien n’est gratuit, on paye à la bande passante utilisée mais aussi en fonction du nombre d’accès. Et ça va très vite…
Le seul usage raisonnable que je vois est de stocker des objets de livraison, qui doivent être accessibles facilement et dont on ne se sert qu’épisodiquement (pour construire une machine virtuelle, déployer une application, etc.).
Alors pourquoi AWS met en avant des usages du type site web statique ou fichiers statiques ? Simple : vous imaginez AWS vous dire d’économiser votre budget et de ne rien dépenser sur leurs infrastructures ?
Innovons dans les attaques
Parfois, il est normal et voulu que des fichiers soient stockés sur un bucket public : on peut même faire un site web statique rien qu’avec S3. Dans ce cas, les fichiers sont disponibles publiquement et c’est le comportement désiré.
Alors les attaquants se sont tournés vers ces fichiers publics pour les compromettre et tenter d’injecter du code ou n’importe quelle cochonnerie, par exemple sur Magecart20. Dans ce cas là, il s’agit d’un problème de gestion des droits, mais de façon plus fine, dans le contrôle d’accès de S3.
Voir aussi
Articles externes
ElasticSearch
ElasticSearch est un moteur de recherche et d’analyse RESTful distribué, d’après son site web (elastic.co). Très utilisé et même proposé sous forme de service par AWS, ce produit permet de gérer des recherches sur de grandes quantités de données.
C’est bien.
Mais cela devient moins amusant quand on le configure mal, les informaticiens pouvant être peu consciencieux ou débordés. Le résultat est alors sans appel : des moteurs de recherche internet (comme Shodan) indexent (trop) facilement les contenus mal protégés, et l’énorme quantité des données gérées par ElasticSearch deviennent purement et simplement disponibles et accessibles à la moindre requête anonyme.
D’après Shodan1, en 2018, 900 To de données ElasticSearch sont disponibles sans protection, et plus de 5 Po de données pour de clusters Hadoop.
Fuites de données
Exactis
Il s’agit du premier cas que j’ai repéré (ça qui ne signifie pas qu’il s’agisse du premier). La volumétrie fait peur : 2 To de données de 340 millions d’utilisateurs2. Pas de cartes bancaires, mais tout un tas de données de profilage, relevant de la vie privée, mais pouvant aussi servir à répondre aux questions de sécurité pour récupérer (frauduleusement) un accès à un quelconque service de messagerie, de réseautage social, etc.
Durée de vie
Ne pas faire attention et laisser les paramètres par défaut peut rapidement conduire à de gros ennuis : une étude de 2020 indique qu’une base non sécurisée est repérée par les méchants en huit heures3. Ils sont à l’affût !
Tellement courant
Les fuites de données dues à une mauvaise mise en oeuvre d’ElasticSearch sont si courantes que la CNIL a publié un guide de bonnes pratiques.
Principe d’Elasticsearch
Elasicsearch est un outil de recherche, open source, très populaire. Son fonctionnement repose sur les index inversés, ou inverted indexes, qui recensent des caractéristiques associées à ces documents, comme par exemple des mots clés, mais il peut y avoir bien d’autres usages, comme le traitement d’un grand nombre de logs, sujet très pertinent en sécurité informatique.
Index inversé
Un index inversé est créé après examen de chacun des documents (« crawling »), et création des caractéristiques associées, que l’on définit selon ses besoins. A la suite de cela, on crée un index partant de ces caractéristiques et pointant vers les documents correspondant le mieux aux caractéristiques recherchées.
Dans des moteurs de recherche web (Yahoo, Google, Bing…) on tape une liste de mots clés, et l’index inversé nous renvoie les pages web les plus pertinentes qu’il a recensé auparavant.
Apache Lucene est un outil open source permettant l’indexation de documents, sur lequel est basé Elasticsearch, qui est une société commerciale mais qui propose des versions gratuites de son produit (qui reste open source).
Cluster
Conçu pour des requêtes complexes, et un nombre de documents très important, Elasticsearch se structure en clusters, dont chacun peut contenir de un à plusieurs milliers de nœuds, chaque nœud étant une machine de traitement.
Sharding
On comprend qu’une requête peut être complexe et avoir besoin de beaucoup de ressources, et donc utiliser plusieurs nœuds. De même, il peut arriver que l’indexation produise des tables si grandes qu’elles ne tiennent pas sur un seul nœud. Pour cela, on peut scinder un index sur plusieurs nœuds ; cela s’appelle le sharding.
Réplication
Comme toute bonne architecture distribuée digne de ce nom, toute donnée doit être dupliquée (ou répliquée) afin de pallier aux accidents mais aussi pour paralléliser les traitements, et Elasticsearch le permet.
Manipulons
ElasticSearch (que je vais abréger en ES) se manipule via des API Rest. Ce gros mot signifie qu’on appelle des requêtes HTTP avec une logique définie. Autant je trouve ça super pour développer une appli web, autant c’est pénible pour mes petits doigts quand il faut taper les commandes avec curl. Heureusement Kibana est une interface web qui permet de réaliser la plupart des opérations sur ES.
Opérations CRUD
Pour créer un index :
$ curl -XPUT 'localhost:9200/documents'
Pour ajouter un document (de format JSON) :
$ curl -XPUT 'localhost:9200/alerts/cloudtrail/1?pretty' -H 'Content-Type: application/json' -d fichier
$ curl -XPUT 'localhost:9200/alerts/cloudtrail?pretty' -H 'Content-Type: application/json' -d fichier
Les arguments sont le nom de l’index, le type du document, et son identifiant (facultatif). Pour un fichier JSON, depuis la version 6, il faut rajouter le type dans le header. Chouette.
Pour afficher les champs id et version du document #1.
$ curl -XGET 'localhost:9200/logs/cloudtrail/1?pretty&_source=id,version'
Pour savoir simplement si le document #1 existe :
$ curl -i -XHEAD 'localhost:9200/logs/cloudtrail/1?pretty'
Pour modifier un document :
$ curl -XPOST 'localhost:9200/alerts/cloudtrail/1?pretty' -H 'Content-Type: application/json' -d fichier
Il faut utiliser POST sur un document existant, et seuls les champs modifiés ont besoin d’être présents dans le fichier, lequel peut également « scripter » le résultat.
Sans surprise, pour supprimer un document, voici la commande :
$ curl -XDELETE 'localhost:9200/alerts/cloudtrail/1?pretty'
Pour avoir différentes informations sur le cluster, il faut jouer avec les commandes _cat.
$ curl -XGET 'localhost:9200/_cat/'
=^.^=
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
...
D’autres commandes utiles sont : _mget, _bulk.
Statut du machin
Différentes commandes permettent d’avoir des infos sur la santé d’ES. Exemples :
$ curl -XGET 'localhost:9200/_cat/health/?v&pretty'
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1535634422 15:07:02 elasticsearch yellow 1 1 6 6 0 0 5 0 - 54.5%
$ curl -XGET 'localhost:9200/_cluster/health/'
{"cluster_name":"elasticsearch","status":"yellow","timed_out":false,"number_of_nodes":1,"number_of_data_nodes":1,"active_primary_shards":6,"active_shards":6,"relocating_shards":0,"initializing_shards":0,"unassigned_shards":5,"delayed_unassigned_shards":0,"number_of_pending_tasks":0,"number_of_in_flight_fetch":0,"task_max_waiting_in_queue_millis":0,"active_shards_percent_as_number":54.54545454545454}
$curl -XGET 'localhost:9200/_cat/indices/?v&pretty'
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana ppRzSXt0Q8G8OXZg8o7_tQ 1 0 2 0 103.4kb 103.4kb
yellow open logs 8YYRLl5_SauA2sglf9YRfA 5 1 36886 0 32.2mb 32.2mb
Recherches et analyses
Les recherches sont similaires à ce qu’on imagine pour un moteur de recherche, tels que Google ou Yahoo. Un langage permet de créer la requête qui vous conviendra et qui vous rendra riche et célèbre, appelé DSL. Rien de mystérieux dans ce langage calqué sur du JSON, il est très souple et très puissant et permet de scripter des requêtes plus ou moins évoluées. Tout comme SQL, on arrivera facilement à faire des requêtes simples, alors que les requêtes complexes demanderont beaucoup de grattage de tête. Point important : les requêtes sont stateful, ce qui signifie qu’il n’y a pas de mécanisme genre curseur comme en SQL.
En gros, on peut demander quels sont les meilleurs documents selon nos critères, auquel cas un score est calculé (et peut être expliqué dans la réponse) et les meilleurs résultats sont affichés ; sinon on peut filtrer et demander si un enregistrement satisfait à nos critères ou pas (la réponse est alors binaire).
La puissance de l’algorithme
TF/IDF de son petit nom, l’algo qui sert de base pour le calcul du score des documents. Il doit être recalculé à chaque ajout de document, mais il ne dépend que de la base de documents indexés, et de rien d’autre. Il est au cœur du fonctionnement d’ES, mais je n’ai pas trouvé de présentation récente de son fonctionnement sur le site ES ; on peut trouver l’info ici (compose.com) ou ici (sur le site de Lucene, le moteur d’ES).
- TF : Term frequency, calculé comme étant la racine carré du nombre d’occurrences d’un terme dans un document ; cela permet de savoir à quelle fréquence un terme apparaît dans un champ. Plus un terme apparaît dans un document, plus le document est pertinent ;
- IDF : Inverse Document Frequency (à expliciter). Il permet de savoir à quelle fréquence un terme apparaît dans un index. Plus un terme est fréquent dans un index, moins il est différenciant.
- La longueur d’un champ intervient aussi (plus la longueur du champ est court, plus l’apparition d’un terme à l’intérieur de celui-ci a de la pertinence). Ainsi, un terme trouvé dans le titre d’un livre induira un score plus élevé que s’il est trouvé dans le corps du texte du livre.
Quand une requête est lancée, les informations demandées dans la requêtes sont combinées avec les résultats de l’algo TF/IDF, et un score est associé à chaque document. Le tour est joué.
Analyse de données
ES permet aussi de réaliser des agrégations de données, ouvrant ainsi la possibilité à l’analyse de données (« analytics »). Il existe quatre types d’agrégation dans ES (je chercherai s’il existe une traduction) :
- « Metric » qui permet de faire des calculs sur l’ensemble des données (ou sur un groupe logique, cf ci-dessous). Cela se rapproche des AVG(), SUM() du SQL ;
- « Bucketing » réalise des groupes logiques de données à partir d’une requête de recherche, similaire au GROUP BY en SQL ;
- « Matrix » est une fonction expérimentale portant sur plusieurs champs en même temps (à développer) ;
- « Pipeline » permet d’enchaîner les agréations.
Champs textes
Les champs texte, de format assez libres, ne sont pas par défaut inclus dans les champs pouvant être requêtés (sic), car cela consomme beaucoup de ressources à indexer (et donc de mémoire). Si on souhaite pouvoir filter et requêter sur ces champs, il faut explicitement demander qu’ils soient intégrés dans le fielddata, qui est l’espace mémoire servant justement à ce type de requêtes.
Voir aussi
Objets connectés
Le terme objets connectés me semble plus approprié que l‘internet des objets, qui prend les choses dans le mauvais sens en partant d’internet pour arriver aux objets, et qui est également trop limitatif car le vrai enjeu n’est pas tant d’être sur internet que d’être relié à d’autres objets.
Le ‘S’ dans IOT c’est pour « Sécurité ».
Blague anonyme
Les objets connectés existent depuis longtemps, sur l’échelle de temps informatique. Un ordinateur ou un serveur informatique étant des objets, il y a belle lurette que la connexion est faite. Le vrai changement est qu’en suivant la vague de miniaturisation et de banalisation des composants informatiques, on peut désormais coller partout ces composants, jusque dans votre pacemaker12, permettant notamment des fonctions évoluées mais aussi de la communication avec d’autres objets, sur internet ou pas.
Cela concourt selon moi à rendre ces objets menaçants, car comme souvent toujours en informatique, la sécurité n’a été abordée qu’après coup, car le bénéfice immédiat (réel) a souvent coupé court à toute autre réflexion.
Marchera pas
Difficile de penser qu’on arrivera facilement à un niveau de sécurité acceptable dans le monde des objets connectés, car la multiplicité des acteurs3 et leur féroce concurrence commerciale, le manque de culture sécurité et le coût nécessaires à cette sécurisation sont des freins puissants sur le chemin de cet objectif. Quant aux mauvaises habitudes, elles perdurent et les mots de passe par défaut continueront à nous jouer des tours, jusqu’à transformer un aspirateur45 en espion (puisque les aspirateurs automatiques ont des caméras pour se diriger).
Innovons
Que n’ai-je entendu que j’étais un râleur patenté, un pessimiste né, un rétrograde primaire, tout ça parce que je pestais (et peste encore) contre l’innovation bête et stupide, ainsi que sa glorification béate (toute comme pour les start-up) sans prise de conscience de l’ensemble des enjeux liés à ladite innovation.
Aspirateurs connectés
A partir du moment où votre aspirateur5 devient un objet connecté, attendez vous au pire. Toute caméra peut devenir un espion potentiel. Donc tout objet connecté, même anodin, peut recueillir (et donc transmettre) plein d’informations vous concernant, et à l’ère du big data, l’utilisation qu’on peut en faire est quasiment infinie.
Des chercheurs ont même réussi à transformer un aspirateur-robot en centre d’écoute : ils ont détourné l’usage du « lidar » (le radar dont se sert le robot pour se déplacer) pour capter les vibrations sonores sur les surfaces rencontrées6, et en déduire les conversations. Seul élément rassurant : vous parlez beaucoup, quand l’aspirateur marche ?
Avions connectés
Cela fait beaucoup moins rire de parler du danger des connexions dans les avions que pour les réfrigérateurs : autant un frigo qui envoie du spam ou qui commande une pizza, cela prête à sourire, autant la perspective d’un avion qui s’écrase fait froid dans le dos. Or dans objets connectés il y a aussi avions connectés. Et le département de la sécurité intérieure aux Etats-Unis nous dit que ce n’est qu’une question de temps7 avant qu’un avion ne soit piraté, avec les conséquences catastrophiques que l’on peut imaginer. Ils ont réussi à la faire avec un Boeing 737, on peut voir une analyse de risque ici.
Voitures et deux-roues connectés
Entre les scooters électriques (ou les vélos) en libre-service qu’il faut suivre pour leur entretien, ou les voitures se conduisant toutes seules, les interactions informatiques sont forcément très nombreuses. Donc récolte de données à gogo8 et réutilisation par toujours contrôlée, surtout en cas de faille.
Un autre exemple ? Volontiers : les trottinettes Xiami M365 peuvent être (au moins partiellement) contrôlées par un pirate9, qui peut agir sur le freinage ou l’accélération avec les conséquences qu’on peut imaginer.
N’importe quoi connecté
Parfois on trouve des failles non seulement dans les objets connectés, mais aussi dans les centrales électroniques censées les contrôler. En gros, si par extraordinaire vous utilisez un objet connecté non troué (= non vulnérable), alors il faudra vérifier que votre hub10 soit également bien protégé.
Menaces
DDoS et Botnets
Puisqu’il est si facile de prendre le contrôle d’un grand nombre de machines informatiques reliées à internet, les objets connectés sont tout naturellement d’excellents candidats pour construire un réseau de machines zombies (botnet). Et les méchants ne s’en privent pas. Les objets connectés piratables, zombifiables et contrôlables à souhait sont du pain béni pour les attaques de type DDoS (déni de service) ; Mirai en a été le premier exemple marquant.
Conséquences juridiques
Les conséquences juridiques sont difficiles à appréhender à l’émergence d’une nouvelle technologie (ou de son expansion). Or, tout comme la sécurité, les aspects juridiques sont trop souvent négligés11, et ça n’est qu’au moment d’une catastrophe, d’une attaque ou d’un litige qu’on se rend compte qu’on ne maîtrise ni la situation technique ni les conséquences juridiques (et judiciaires) de cette technologie.
En 2019 : rien de nouveau
Étonnamment, malgré des alertes renouvelées et argumentées, malgré des compromissions, les fabricants d’objets connectés continuent leur déni12 et la situation ne s’améliore absolument pas. En cause, toujours les mêmes facteurs :
- La course au prix le plus bas (la sécurité étant vue comme source de surcoût initial) ;
- La course à la part de marché et le time-to-market : faut être le premier, et pas le meilleur. Or la sécurité demande de réfléchir, donc du temps que les industriels ne se donnent pas.
En 2020 : rien de nouveau
Une étude de Palo Alto Networks13 enfonce le clou : sur le million d’objets connectés étudiés, 98% des flux réseaux circulent en clair, avec les risques de fuite d’information et de détournement associés, 57% sont vulnérables à des attaques ayant des impacts moyens ou élevés, dans l’industrie et les milieux hospitaliers, les objets vulnérables sont sur les mêmes VLAN que les dispositifs traditionnels, les mots de passe sont majoritairement faibles voire encore triviaux, etc.
The Internet of Things is a security nightmare reveals latest real-world analysis: unencrypted traffic, network crossover, vulnerable OSes
Sources
theregister.co.uk
Une autre étude de Zscaler14 est moins pessimiste, mais pas plus rassurante pour autant : seules 17% des « transactions » sont chiffrées. Cela s’explique probablement par un panel d’étude différent, avec d’autres usages et donc d’autres types de machines, mais ça reste pas beaucoup…
Sources
- https://threatpost.com/security-glitch-in-iot-camera-enabled-remote-monitoring/134504/
- https://www.zdnet.com/article/flaw-let-anyone-snoop-on-smart-cameras/
- https://blog.talosintelligence.com/2018/07/samsung-smartthings-vulns.html?m=1
- https://www.armis.com/dns-rebinding-exposes-half-a-billion-iot-devices-in-the-enterprise/
- https://internetofthingsagenda.techtarget.com/definition/IoT-security-Internet-of-Things-security
- Article IBM X-Force (très complet, présenté à DefCon 2018)
Voir aussi
Attaque et défense
La défense semble une posture normale pour tout entité, vivante ou organisationnelle. Il va de soi qu’un Etat va chercher à se défendre et à défendre ses concitoyens, tout comme n’importe quel individu. L’attaque dépend d’autres facteurs, et cette capacité a longtemps eu une place à part en informatique, car cela a toujours été considéré comme l’apanage des méchants. L’informatique était considérée comme un outil de production, qu’il fallait protéger et garder en état de marche.
Or dans la vraie vie, l’attaque fait partie de la stratégie des individus comme des nations, et les capacités offensives commencent à se faire jour. De plus, avec l’importance croissante de l’informatique dans la richesse et les capacités de production (parfois vitales) des pays, elle devient aussi une cible stratégique.
C’est la guerre ?
Je ne parle pas des nord-coréens qui ne pensent qu’à détruire cette méchante Amérique qui fait rien que les embêter. Je parle de ce que la cyberguerre est désormais une réalité si tangible qu’elle est l’objet de discussion et même d’un projet de traité au sein des Nations-Unies.
Or il semble que le sujet soit si sensible que treize années de négociations n’ont pas pu aboutir1. Point de traité donc, notamment parce que certains pays souhaitent que le cyberespace reste en dehors des conflits et que sa militarisation (c’est-à-dire la définition de ce que serait une attaque et une réponse dans ce cybermonde) risquerait de conduire à de réels conflits armés2.
L’intention est évidemment bonne, mais l’effet ne sera-t-il pas au contraire une escalade des conflits dans cet espace au mépris de toute règle ? Les attaques informatiques peuvent avoir un impact économique (et donc humain) majeur, et l’absence de principes ou de contrôles pourrait tout au contraire exacerber les tensions et conduire également à de vrais conflits militaires. L’Europe a relancé une action3 pour tenter de formaliser tout ça afin de stabiliser le cyberespace, mais il est difficile de savoir sur quoi cela va aboutir.
Ça change ?
Oui : on estime que seuls deux états avaient des capacités offensives en 2007, et ils seraient une trentaine en 2017. Les activités quasi-militaires prennent tant d’importance que l’ONU s’en inquiète et propose d’instaurer une sorte de code de bonne conduite via un cadre légal4, qui risque cependant d’être très difficile à faire respecter s’il venait à voir le jour.
Localisation
Historiquement, les Etats-Unis, la Chine et la Russie font partie des nations ayant une forte activité (en attaque comme en défense). Mais certains pays émergents profitent de la demande pour proposer des services d’attaque et de compromission, de type APT : l’Iran et le Vietnam commencent à se faire une réputation dans ce domaine5.
Ça chauffe ?
On dirait : à l’aube des élections présidentielles russes de 2018, les Etats-Unis accusent ouvertement la Russie6 d’avoir perturbé le fonctionnement des réseaux énergétiques (et d’autres choses7) via une attaque informatique, avec des mesures de rétorsion diplomatiques notables8 en retour. Il semble acquis (en août 2018) que des pirates910 ont bel et bien réussi à pénétrer un réseau pouvant agir sur la distribution d’électricité, mais sans n’avoir rien déclenché11 (ou perturbé).
Ce qu’il y a de nouveau ne sont pas les conséquences dans les relations internationales mais l’outil employé pour peser dans ces relations : l’informatique. Les attaques sont désormais tellement structurées et les conséquences tellement visibles que les attaques informatiques constituent un moyen de pression mais aussi un moyen d’action contre ses ennemis.
D’autres exemples
En août 2017, une usine pétrochimique située en Arabie Saoudite aurait été visée par un programme malveillant dont le but aurait été une destruction physique12 d’installations de cette usine. La complexité de l’attaque est telle qu’il est peut probable qu’elle soit le fait d’un petit groupe isolé : les auteurs avaient de l’information, du temps, et de moyens. L’attaque n’a échoué qu’à cause d’une seule une erreur dans le code.
En janvier 2017, d’autres structures d’Arabie Saoudite avaient été touchées par un programme ayant effacé une grande partie des disques durs touchés. Une attaque qui rappelle celle ayant eu lieu cinq ans plus tôt (le 15 août 2012) où les 3/4 des disques durs ont été effacés13, ce qui était une des attaques les plus marquantes de l’époque en raison justement de cette destruction physique de données.
En juin 2018, des observateurs ont noté une baisse notables des attaques d’un groupe supposé nord-coréen (Covellite14) vers des cibles américaines. Curieusement, cela correspond à une période de réchauffement des relations15 entre les deux pays, au moment où rencontre entre Potus (@potus est le compte twitter du President Of The United States [of America]) ) et Kim Jong Un (le leader nord-coréen) est prévue.
Les forces en présence
Des attaques militaires
En 2010, une corvette militaire sud-coréenne a été coulée (incident de Baengnyeong). Récemment, des analystes ont émis l’hypothèse que des cyberattaquants nord-coréens auraient tenté à de nombreuses reprises de compromettre le service météo sud-coréen16 afin de prévoir la route de patrouille empruntée par la corvette.
Ça continue !
Les accusations contre la Russie qui compromettrait des installations industrielles continuent à fleurir au début de l’année 2018 (presque autant que des fuites d’informations sur AWS S3).
- https://www.us-cert.gov/ncas/alerts/TA18-106A
- http://www.dailymail.co.uk/news/article-5623477/Hundreds-Australian-companies-hit-Russian-cyber-attacks-Kremlin-hacks-millions-computers.html
- http://www.digitaljournal.com/news/world/us-britain-warn-of-russian-campaign-to-hack-networks/article/519977
- https://www.reuters.com/article/us-germany-russia-maas/germany-says-it-has-to-assume-russia-behind-recent-cyber-attack-idUSKBN1HM0TZ
- https://www.boursorama.com/bourse/actualites/berlin-accuse-moscou-d-etre-derriere-une-recente-cyberattaque-22f85ed245a291be4a315c6dfdbf6520
On se défend
Comme on peut. Que ce soit contre la manipulation, ou contre les pirates soutenus par des Etats, les grands acteurs de l’informatique se liguent et s’unissent pour protéger nos intérêts. Ou les leurs. Ou les deux. Tous les grands noms y sont, sauf Apple, Amazon et Google. Ne me demandez pas pourquoi.
Guerre offensive
En 2019, il n’y a plus guère de doutes sur les tentatives de manipulation des élections américaines de 2016, au point qu’on sait désormais qu’il y a eu des mesures de rétorsion17 sur « l’usine à trolls » russe, aboutissant à la destruction de données (via un contrôleur RAID a priori).
Voir aussi
Sources
- http://www.lefigaro.fr/flash-actu/2018/03/15/97001-20180315FILWWW00429-l-otan-elabore-une-definition-de-l-etat-de-cyberguerre.php
- https://abcnews.go.com/Technology/wireStory/us-hits-russian-firms-sanctions-citing-cyberattacks-55806268
Russie, NotPetya
- http://money.cnn.com/2018/02/15/technology/russia-cyberattack-notpetya-uk/index.html
- https://www.theregister.co.uk/2018/02/15/uk_names_russian_military_as_source_of_notpetya/
- https://www.reuters.com/article/us-britain-russia-cyber-usa/white-house-blames-russia-for-reckless-notpetya-cyber-attack-idUSKCN1FZ2UJ
- http://www.bbc.com/news/uk-politics-43062113
- https://www.infosecurity-magazine.com/news/five-eyes-united-blaming-russia/
Etats
- https://www.dni.gov/files/documents/Newsroom/Testimonies/2018-ATA—Unclassified-SSCI.pdf
- https://www.afcea.org/content/russia-iran-and-north-korea-bolder-cyber-realm
- https://arstechnica.com/information-technology/2018/05/researchers-link-a-decade-of-potent-hacks-to-chinese-intelligence-group/
- http://www.clubic.com/antivirus-securite-informatique/virus-hacker-piratage/piratage-informatique/actualite-843496-rapport-10-ans-piratage-gouvernement-chinois.html
Attaques
- https://www.cyberscoop.com/trisis-ics-malware-saudi-arabia/
- https://dragos.com/blog/trisis/TRISIS-01.pdf
- https://cyberdefense.orange.com/fr/trisis-le-malware-ciblant-les-systemes-industriels/
APT
- https://www.scmagazineuk.com/new-apt-groups-emerge-as-more-nations-join-the-global-cyber-arms-race/article/762291/
- https://www.fireeye.com/blog/executive-perspective/2018/04/rise-of-the-rest-apt-groups-no-longer-from-just-china-and-russia.html
- https://forum.anomali.com/t/apt29-a-timeline-of-malicious-activity/2480
- https://www.anomali.com/blog/what-is-operational-threat-intelligence
Insolite
Août 2018
- Les shadow brokers avaient déjà balancé les outils de la NSA, pour réchauffer l’ambiance. Maintenant on balance ses petits collègues, entre pirates de bonne compagnie1.
- Un pirate peut infiltrer votre réseau avec… un fax !