Un rootkit (en français : « outil de dissimulation d’activité »1) est un type de programme (ou d’ensemble de programmes ou d’objets exécutables) dont le but est d’obtenir et de maintenir un accès frauduleux (ou non autorisé) aux ressources d’une machine, de la manière la plus furtive et indétectable possible.
Le terme peut désigner à la fois la technique de dissimulation ou son implémentation (c’est-à-dire un ensemble particulier d’objets informatiques mettant en œuvre cette technique).
Historique
Le phénomène n’est pas nouveau : des programmes manipulant les logs système, tout en se dissimulant des commandes donnant des informations sur les utilisateurs (telles que who, w, ou last), sont apparus en 1989{{Lien web | url = http://www.sans.org/reading_room/whitepapers/honors/linux_kernel_rootkits_protecting_the_systems_1500?show=1500.php&cat=honors | titre = Linux kernel rootkits: protecting the system’s « Ring-Zero » | date = mars 2004 | éditeur = SANS Institute }} ; les premiers rootkits sur Linux et Solaris ont été rencontrés au début des années 19902 et ont été répertoriés en tant que tels en octobre 1994. Le projet chkrootkit, dédié au développement d’un outil de détection de rootkits pour les plateformes Solaris et HP-UX, a été démarré en 1997.
Il existe des rootkits pour la plupart des systèmes d’exploitation. En 2002, Securityfocus constatait déjà des évolutions et des progrès en matière de rootkit pour les plate-formes Windows. Un des premiers rootkits pour Mac OS X (WeaponX) est apparu en novembre 20043.
Certains rootkits peuvent être légitimes, pour permettre aux administrateurs de reprendre le contrôle d’une machine défaillante, pour suivre un ordinateur ayant été volé4, ou dans des outils comme Daemon Tools ou Alcohol 120%5. Mais aujourd’hui le terme n’évoque quasiment plus que des outils à finalité malveillante.
Mode opératoire
Contamination
La première phase d’action d’un rootkit consiste à chercher un accès au système, sans forcément que celui-ci soit un accès privilégié (ou en mode administrateur). La contamination d’un système peut avoir lieu de différentes façons, en utilisant les techniques habituelles des programmes malveillants. Les moyens les plus courants sont :
- utilisation des techniques virales : un rootkit n’est pas un virus à proprement parler, mais il peut se transmettre par les techniques utilisées par les virus, notamment par un [[Cheval_de_Troie_(informatique)|cheval de Troie]]. Un virus peut avoir pour objet de répandre des rootkits sur les machines infectées (a contrario, un virus peut aussi utiliser les techniques de rootkits pour parfaire sa dissimulation) ;
- mise en œuvre d’un [[Exploit_(informatique)|exploit]], c’est-à-dire l’exploitation d’une vulnérabilité de sécurité, à n’importe quel niveau du système : application, système d’exploitation, BIOS, etc. Cette mise en œuvre peut être le fait d’un virus, mais elle résulte aussi souvent de botnets qui réalisent des scans de machines pour identifier les failles et exploiter celles qui sont utiles à l’attaque ;
- attaque par force brute, afin de profiter de la faiblesse des mots de passe de certains utilisateurs, et obtenir ainsi un accès au système.
Modification du système et dissimulation
Une fois la contamination effectuée et l’accès obtenu, la phase suivante du mode opératoire consiste en l’installation de l’ensemble des objets et outils nécessaires au rootkit. Il s’agit des objets permettant la mise en place de la charge utile du rootkit, s’ils n’ont pas pu être installés durant la phase de contamination, ainsi que les outils et les modifications nécessaires à la dissimulation.
Mise en place de la charge utile
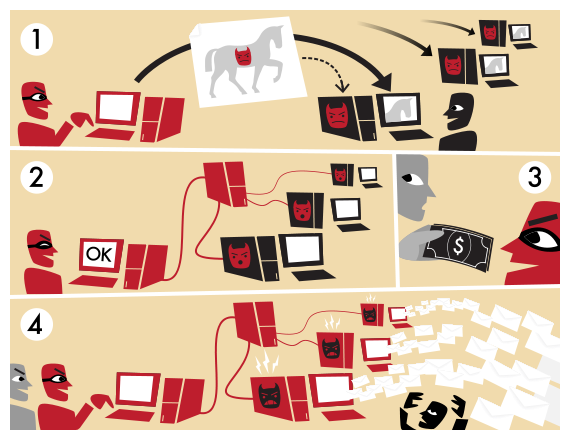
permet d’avoir un accès sur des centaines de machines.]]
La charge utile est la partie active du rootkit (et de tout programme malveillant en général), dont le rôle est d’accomplir la (ou les) tâche(s) assignée au système. La charge utile permet d’avoir accès aux ressources de la machine infectée, et notamment :
- CPU, pour décoder des mots de passe ou plus généralement pour effectuer des calculs distribués à des fins malveillantes ;
- serveur de messagerie, pour envoyer des mails (pourriel ou spam) en quantité ;
- ressources réseaux, pour servir de base de lancement pour des attaques diverses (déni de service, exploits) ou pour sniffer l’activité réseau ;
- pilotes de périphériques, pour installer des enregistreurs de frappe ou keyloggers (par exemple) ;
- accès à d’autres machines, par rebond ;
- prise de contrôle total de la machine (par exemple en remplaçant le procédé de connexion, comme
/bin/loginsous Linux).
Certains rootkits sont utilisés pour l’exploitation de botnets, la machine infectée devenant alors une machine zombie, comme par exemple pour le botnet Srizbi6.
Dissimulation
Le rootkit cherchera également à « dissimuler » son activité. Ce procédé de dissimulation permet évidemment de minimiser le risque de découverte du rootkit, afin de profiter le plus longtemps possible de l’accès frauduleux. Une des caractéristiques principales d’un rootkit est donc sa faculté à se dissimuler, alors qu’un virus cherche principalement à se répandre, ces deux fonctions étant parfois jumelées pour une efficacité supérieure. Selon les cas, plusieurs méthodes peuvent être employées et combinées :
- en ouvrant des portes dérobées, afin de pérenniser l’accès au système et permettre le contrôle de la machine, l’installation de la charge utile, etc27 ;
- en cachant des processus informatiques ou des fichiers ; sous Windows, une technique consiste à modifier certaines clés de la base de registre ; sous Linux, on peut par exemple modifier les fichiers
/usr/include/proc.h(processus à masquer) ou/usr/include/file.h(fichiers à masquer) ; - en remplaçant certains exécutables ou certaines librairies par des programmes malveillants et des chevaux de Troie, contrôlables à distance ;
- en obtenant des droits supérieurs (par élévation des privilèges), afin de désactiver les mécanismes de défense ou pour agir sur des objets de haut niveau de privilèges ;
- en utilisant des techniques de type « {{lang|en|Stealth by Design}} » (littéralement « furtif par conception »)8, à savoir implémenter à l’intérieur du rootkit des fonctions système afin de ne pas avoir à appeler les fonctions standards du système d’exploitation et ainsi éviter l’enregistrement d’événements système suspects ;
- en détournant certains appels aux tables de travail utilisées par le système{{pdf}} {{Lien web |url=http://www.security-labs.org/fred/docs/sstic07-rk-article.pdf|titre=De l’invisibilité des rootkits : application sous Linux|auteur=E. Lacombe, F. Raynal, V. Nicomette|éditeur=CNRS-LAAS/Sogeti ESEC}} par [[Hook (informatique)|hooking]] ;
- en effaçant physiquement toute trace d’activité, notamment dans les journaux de logs système, etc.
Niveau de privilège
Bien que le terme a souvent désigné des outils ayant la faculté à obtenir un niveau de privilège de type administrateur (utilisateur root) sur les systèmes Unix et Linux, un rootkit ne cherche pas obligatoirement à obtenir un tel accès sur une machine (par [[Élévation_des_privilèges|élévation de privilège]]), et ne nécessite pas non plus d’accès administrateur pour s’installer, fonctionner et se dissimuler9. Le programme malveillant Haxdoor10, même s’il était un rootkit du type noyau11 pour parfaire sa dissimulation, écoutait les communications sous Windows en mode utilisateur12 afin de tenter de capturer des identifiants avant cryptage, en interceptant les API de haut niveau.
Cependant, l'[[Élévation_des_privilèges|élévation de privilège]] est souvent nécessaire pour que le camouflage soit efficace : le rootkit peut utiliser certains [[Exploit_(informatique)|exploits]] afin de parfaire sa dissimulation en opérant à un niveau de privilège très élevé, pour atteindre des bibliothèques du système, des éléments du noyau, pour désactiver les défenses du système, etc.
Types
Il existe cinq types principaux de rootkits selon leur cible : les kits de niveau micrologiciel, hyperviseur, noyau, bibliothèque et applicatif.
Niveau micrologiciel/hardware
Il est possible d’installer des rootkits directement au niveau du micrologiciel (ou {{lang|en|firmware}}). De nombreux produits proposent désormais des mémoires flash, ce qui peut être utilisé pour implanter durablement du code13, en détournant par exemple l’usage d’un module de persistance souvent implanté dans le BIOS de certains systèmes.
Un outil légitime utilise d’ailleurs cette technique : LoJack, d’AbsolutSoftware4, qu’on trouve sur des ordinateurs portables car il permet ainsi de suivre un ordinateur à l’insu de l’utilisateur (en cas de vol). Ce code peut « survivre » à un changement de disque dur voire à un flashage du BIOS14 si le module de persistance est présent et actif. Tout périphérique disposant d’un tel type de mémoire est donc potentiellement vulnérable.
Une piste évoquée pour contrer ce genre de rootkit serait d’interdire l’écriture du BIOS (grâce à un cavalier sur la carte-mère ou par l’emploi d’un mot de passe) ou d’utiliser des EFI à la place du BIOS15, mais cette méthode reste à tester et à confirmer16.
Niveau hyperviseur
Ce type de rootkit se comporte comme un hyperviseur classique (de niveau 1) : après s’être installé et avoir modifié la séquence de démarrage, pour être lancé en tant qu’hyperviseur de la machine infectée au démarrage. Le système d’exploitation original se retrouve alors être un hôte (invité) du rootkit, lequel peut alors intercepter tout appel matériel. Il devient quasiment impossible à détecter depuis le système original.
Une étude conjointe de chercheurs de l’université du Michigan et de Microsoft ont démontré la possibilité d’un tel type de rootkit, qu’ils ont baptisé « {{lang|en|virtual-machine based rootkit}} » (VMBR)17. Ils ont pu l’installer sur un système Windows XP et sur un système Linux. Les parades proposées sont la sécurisation du boot, le démarrage à partir d’un média vérifié et contrôlé (réseau, CD-ROM, clé USB, etc) ou l’emploi d’un moniteur de machine virtuelle sécurisé.
Niveau noyau
Certains rootkits arrivent à s’implanter dans les couches du noyau du système d’exploitation soit dans le noyau lui-même, soit dans des objets exécutés avec un niveau de privilèges équivalent au système, ce qui est le cas pour certains pilotes de périphériques.
Sous Linux, il s’agit souvent de modules pouvant être chargés au niveau du noyau (modules de noyau chargeables, ou {{lang|en|loadable kernel modules}}), sous Windows de pilotes informatiques. Avec un tel niveau de privilèges, la détection et l’éradication du rootkit n’est souvent possible que de manière externe au système en redémarrant (en bootant) depuis un système sain, installé sur CD, sur une clé USB ou par réseau.
Ce type de rootkit est dangereux à la fois parce qu’il a acquis des privilèges élevés (il est alors plus facile de leurrer un logiciel de protection), mais aussi par les instabilités qu’il peut causer sur le système infecté comme cela a été le cas lors de la correction de la vulnérabilité MS10-01518, où des [[Écran_bleu_de_la_mort|écrans bleus]] sont apparus en raison d’un conflit entre cette correction et le fonctionnement du rootkit Alureon19.
Niveau bibliothèque
À ce niveau, le rootkit détourne l’utilisation de bibliothèques légitimes du système d’exploitation. Plusieurs techniques peuvent être utilisées :
- en patchant un objet d’une bibliothèque, c’est-à-dire en ajoutant du code à l’objet en question ;
- en détournant l’appel d’un objet (« hooking »), ce qui revient à appeler une autre fonction puis à revenir à la fonction initiale ;
- en remplaçant des appels système par une version spécifique, ce qui correspond à remplacer l’appel système initial par du code malveillant.
Ce type de rootkit est assez fréquent, mais il est aussi le plus facile à contrer, notamment par un contrôle d’intégrité des fichiers essentiels en surveillant leur empreinte grâce à une fonction de hachage, par détection de signature du programme malveillant, ou par exemple par examen des {{lang|en|hooks}} par des outils comme unhide sous Linux ou HijackThis sous Windows.
Niveau applicatif
Un rootkit applicatif implante des programmes malveillants de type [[Cheval_de_Troie_(informatique)|cheval de Troie]], au niveau utilisateur. Ces programmes prennent la place de programmes légitimes ou en modifient le comportement, afin de prendre le contrôle des ressources accessibles par ces programmes.
Exemples
Rootkits Sony
À deux reprises, Sony a été confronté à la présence masquée de rootkits dans ses produits : dans ses clés usb biométriques20 et dans son composant de gestion numérique des droits (DRM)2122 présent notamment sur ses CD audio. Ce rootkit possède lui-même des failles qui peuvent être exploitées.
Ces affaires ont fait un tort important à Sony, aussi bien pour sa respectabilité que financièrement. Dans plusieurs pays, Sony a été poursuivi en justice et obligé de reprendre les CD contenant un rootkit et de dédommager les clients23.
Voir aussi : [[:en:Sony BMG CD copy protection scandal|Sony BMG CD copy protection scandal]].
Exploitation de la vulnérabilité de LPRng
Le CERTA (Centre d’Expertise Gouvernemental de Réponse et de Traitement des Attaques informatiques) a publié, dans une note d’information, l’analyse d’une attaque ayant permis d’installer un rootkit (non identifié), n’utilisant à l’origine qu’une seule faille (répertoriée CERTA-2000-AVI-08724) qui aurait pu être stoppée soit par la mise-à-jour du système, soit par le blocage d’un port spécifique grâce à un pare-feu25.
Cette attaque a été menée en moins de deux minutes. L’attaquant a identifié la vulnérabilité, puis envoyé une requête spécialement formée sur le port 515 (qui était le port exposé de cette vulnérabilité) pour permettre l’exécution d’un code arbitraire à distance. Ce code, nommé « SEClpd », a permis d’ouvrir un port en écoute (tcp/3879) sur lequel le pirate est venu se connecter pour déposer une archive (nommée rk.tgz, qui contenait un rootkit) avant de la décompresser et de lancer le script d’installation.
Ce script a fermé certains services, installé des [[Cheval_de_Troie_(informatique)|chevaux de Troie]], caché des processus, envoyé un fichier contenant les mots de passe du système par mail, et il a même été jusqu’à corriger la faille qui a été exploitée, afin qu’un autre pirate ne vienne pas prendre le contrôle de la machine.
Prévention
Moyens de détection
La mise en œuvre de la détection peut parfois demander un examen du système ou d’un périphérique suspect en mode « inactif » (démarrage à partir d’un système de secours ou d’un système réputé sain), selon le type de rootkit. Les moyens de détection peuvent être :
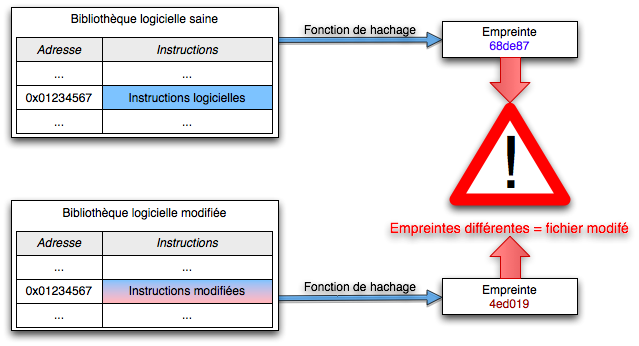
- contrôle de l’intégrité des fichiers : on cherche à détecter toutes modifications des fichiers sensibles (bibliothèques, commandes systèmes, etc)8 en vérifiant régulièrement leur intégrité, en calculant pour chacun d’eux leur empreinte : toute modification inattendue de cette somme indiquera une modification du fichier et une contamination potentielle. Cela demande cependant une analyse car tout système subit aussi des modifications légitimes (comme lors des mises-à-jour du système) ; idéalement, l’outil de contrôle aura la possibilité d’accéder à une base de référence de ces sommes de contrôles, qui variera donc en fonction du système et des versions utilisées (comme rkhunter, par exemple) ;
- détection de leur signature spécifique : il s’agit du procédé classique d’analyse de signature, comme cela se fait pour les virus. On cherche à retrouver dans le système la trace d’une infection, soit directement (signature des objets du rootkit), soit par le vecteur d’infection (virus utilisé par le rootkit)8 ;
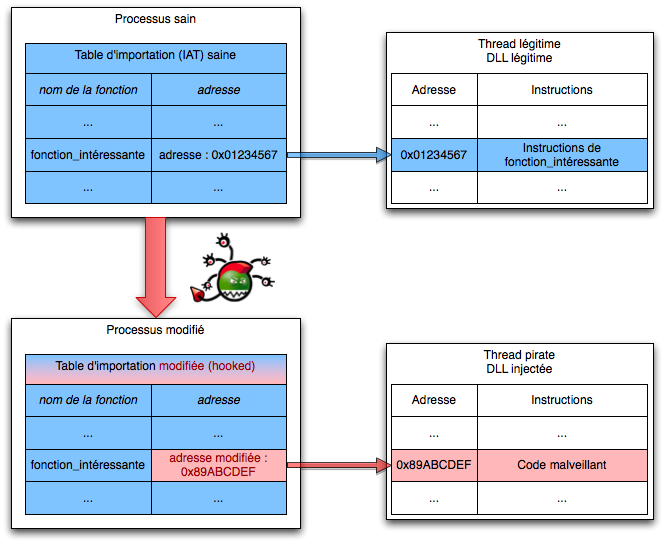
- analyse des appels systèmes : cette technique consiste à analyser la table des appels système, les tables d’interruption (ou Interrupt Descriptor Table)2627 et de manière générale les tables de travail utilisées par le système par des outils comme HijackThis qui permettent de voir si ces appels sont détournés ou non, par exemple en comparant ce qui est chargé en mémoire avec les données brutes de bas niveau (ce qui est écrit sur le disque) ;
- analyse des flux réseau anormaux : cette analyse28 permet de détecter une surcharge ou une utilisation de ports logiciels inhabituels qui peut être observée à partir de la contamination de la machine, grâce aux traces issues d’un pare-feu ou grâce à un outil spécialisé. Il est également possible de faire une recherche des ports logiciels ouverts et de la comparer à ce que connaît le système, avec des outils d’investigation comme unhide-tcp. Toute différence peut être considérée comme anormale. Il existe cependant des moyens de dissimulation réseau, comme de la stéganographie ou l’utilisation de canaux cachés, qui rend la détection directe impossible, et seule une analyse statistique peut éventuellement répondre à cette difficulté29 ;
- analyse des logs système : ce type d’analyse30 automatisée s’appuie sur le principe de corrélation, avec des outils de type HIDS qui disposent de règles paramétrables31 pour distinguer les événements anormaux et mettre en relation des événements systèmes distincts, sans rapport apparent ou différés dans le temps ;
- analyse de la charge système : une surveillance continue peut mettre en évidence un surcharge, à partir de la contamination de la machine. Il s’agit essentiellement d’une analyse statistique de la charge habituelle d’une machine, comme le nombre de mails sortants ou la charge CPU. Toute modification (en surcharge) sans cause apparente est suspecte, mais cela demandera une analyse complémentaire pour écarter toute cause légitime (mise-à-jour du système, installation de logiciels, etc).
- recherche d’objets cachés, tels que des processus informatiques, des clés de registre, des fichiers, etc. Des outils comme unhide sous Linux réalisent cette tâche pour les processus. Sous Windows, des outils comme RootkitRevealer recherchent les fichiers cachés en listant les fichiers via l’API normale de Windows puis en comparant cette liste à une lecture physique du disque ; tout fichier caché (à l’exception des fichiers légitimes connus de Windows, tels que les fichiers métadata de NTFS comme
$MFTou$Secure) est alors suspect32.
Moyens de protection et de prévention
Les moyens de détection peuvent également servir à la prévention, même si celle-ci sera toujours postérieure à la contamination. D’autres mesures en amont peuvent limiter l’installation d’un rootkit33 :
- correction des failles par mise-à-jour de l’OS : cela permet de réduire la surface d’exposition du système en éliminant le temps où une faille est présente sur le système34 et dans les applications30, afin de prévenir les [[Exploit_(informatique)|exploits]] pouvant être utilisés pour la contamination ;
- utilisation d’un pare-feu : cela fait partie des bonnes pratiques dans le domaine de la sécurité informatique, et se révèle efficace dans le cas des rootkits273034 car cela empêche des communications inattendues (téléchargements de logiciel, dialogue avec un centre de contrôle et de commande d’un botnet, etc.) dont ont besoin les rootkits ;
- utilisation d’outil de prévention de type HIPS : ces outils30, de type logiciel ou appliance, répondent dès qu’une alerte est suspectée, en bloquant des ports ou en interdisant la communication avec une source (adresse IP) douteuse, ou toute autre action appropriée. La détection sera d’autant meilleure que l’outil utilisé sera externe au système examiné, puisque certains rootkit peuvent atteindre des parties de très bas niveau dans le système, jusqu’au BIOS même. Un des avantages de ces outils est l’automatisation des tâches de surveillance8 ;
- contrôle d’intégrité des fichiers : des outils spécialisés existent pour remplir cette tâche, et peuvent produire des alertes lors de modifications inattendues. Cependant, ce contrôle à lui seul seul est insuffisant si d’autres mesures préventives ne sont pas mises en œuvre, si aucune réponse du système n’est déclenchée, ou si ces différences ne sont pas analysées. Les HIPS/HIDS, ainsi que certains outils anti-rootkits comme rkhunter peuvent interpréter ces contrôles via une base de sommes de contrôle (pour des versions connues de systèmes d’exploitation) ou par corrélation ;
.]]
- renforcement de la robustesse des mots de passe : il s’agit là encore d’une des bonnes pratiques de sécurité informatique, qui éliminera une des sources principales de contamination. Des éléments d’authentification triviaux sont des portes ouvertes pour tous type d’attaque informatique ;
- démarrage du système à partir d’une image saine : le démarrage à partir d’une image saine, contrôlée et réputée valide du système d’exploitation, via un support fixe (comme un LiveCD, une clé USB) ou par réseau, permet de s’assurer que les éléments logiciels principaux du système ne sont pas compromis, puisqu’à chaque redémarrage de la machine concernée, une version valide de ces objets est chargée. Un système corrompu serait donc remis en état au redémarrage (sauf dans le cas de rootkit ayant infecté le BIOS, qui ne sera lui pas rechargé automatiquement) ;
- moyens de protection habituels : {{citation étrangère |lang=en |Do everything so that attacker doesn’t get into your system}}29. Tous les moyens habituels et classiques de protection d’un système informatique sont utiles, tels que [[Durcissement_(informatique)|durcissement du système]]27, filtrages applicatifs (type mod_security), utilisation de programmes antivirus2734 pour minimiser la surface d’attaque et surveiller en permanence les anomalies et tentatives de contamination, sont bien sûr à mettre en œuvre pour éviter la contamination du système et l’exposition aux [[Exploit (informatique)|exploits]].
Windows 10
Microsoft a travaillé pour rendre l’installation de rootkits plus difficile. Leur travail a porté ses fruits, mais être mieux protégé ne signifie pas être totalement protégé, car un malware (Zacinlo) présent à 90%35 sur des machines Windows a réussi à assurer sa persistance grâce à un rootkit.
Outils et programmes de détection
Bien que les rootkits existent depuis un certain temps, l’industrie de la sécurité informatique ne les a pris en compte (en masse) que récemment, les virus puis les chevaux de Troie accaparant l’attention des éditeurs. Il existe cependant quelques programmes de détection et de prévention spécifiques à Windows, tels que Sophos Anti-Rootkit, ou AVG Anti-Rootkit. Sous Linux, on peut citer rkhunter et chkrootkit ; plusieurs projets open-source existent sur Freshmeat et Sourceforge.net.
Aujourd’hui, il reste difficile de trouver des outils spécifiques de lutte contre les rootkits, mais heureusement leur détection et leur prévention sont de plus en plus intégrées dans les HIPS et même dans les anti-virus classiques, lesquels sont de plus en plus obligés de se transformer en suites de sécurité pour faire face à la diversité des menaces ; ils proposent en effet de plus en plus souvent des protections contre les rootkits, comme Avast, AVG 8.0 ou Microsoft Security Essentials.
Liens externes
- Vidéo sur le rootkit Trojan.Alureon/Trojan.TDSS
- Le danger et fonctionnement des rootkits
- cert-ist.com, CERT dédié à la communauté Industrie, Services et Tertiaire française
- antirootkit.com, site (ancien) listant de nombreux outils
{{Portage}}