Principe
Les principe des serverless functions (fonctions sans serveur) consiste à mettre à disposition, pour un client, un environnement d’exécution géré par l’hébergeur (et non par le client) permettant de faire tourner un script ou programme ayant une durée de vie assez courte, par exemple en réponse à un événement quelconque.
Source : us-17-Krug-Hacking-Severless-Runtimes.pdf (blackhat.com)
Faille ou pas ?
Bien que n’étant pas à proprement parler une faille VM Escape, de tels problèmes peuvent également apparaître dans l’utilisation de conteneurs et de fonctions sans serveur (ou serverless functions), où la provision des ressources échappe à l’utilisateur. L’isolation des conteneurs (qu’elle qu’en soit la technique) doit être parfait sous peine d’avoir des « containers escape ».
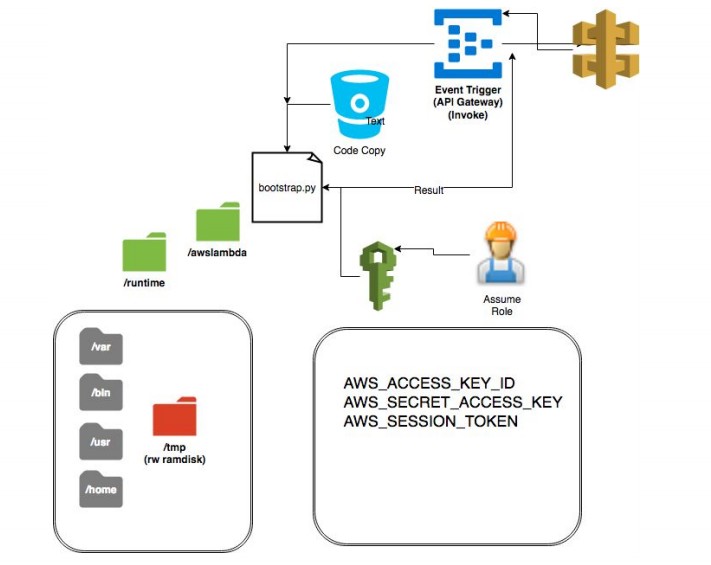
Ces fonctions très à la mode à partir de 2018 exposent à un risque similaire à celui des VM, en cas de manque d’isolation : un utilisateur non autorisé pourrait aller modifier le code d’un autre utilisateur, et faire ainsi ce qu’il veut, comme récupérer des données critiques. Ce risque n’est plus uniquement théorique, lui non plus1 : on a trouvé une façon d’exploiter ce type de vulnérabilité sur le cloud IBM, utilisant notamment OpenWhisk (Apache). IBM n’est pas un petit acteur, Apache non plus ; et Microsoft et Amazon proposent aussi ce type de fonctions sans serveur, sans qu’il soit facile pour un observateur extérieur de maîtriser toutes les couches logicielles et matérielles mises en oeuvre.
Certains ont essayé de découvrir ce qui se cachait derrière2 (cf schéma ci-dessus pour AWS), afin d’évaluer les risques d’une telle architecture.
Sources
- https://www.blackhat.com/docs/us-17/wednesday/us-17-Krug-Hacking-Severless-Runtimes.pdf
- https://gist.github.com/andrewkrug/c2a8858e1f63d9bcf38706048db2926a
- https://liftoff.github.io/pyminifier/
- https://github.com/torque59/AWS-Vulnerable-Lambda