Kubernetes, ou k8s pour les intimes, est un orchestrateur. On pourrait dire parmi tant d’autres, vus qu’ils fleurissent pour nous aider à tout faire, mais pas tant que ça : il tend de facto à devenir un standard, ou tout du moins l’outil le plus utilisé dans son genre.
Concepts
C’est quoi son genre ?
C’est de déployer une application sur des nœuds. Dis comme ça, ça ne casse pas des briques. Mais disons que c’est un outil (initialement créé par Google mais open source depuis quelques temps) qui dispose d’une certaine puissance et surtout une grande maturité dans son domaine, ce qui est plutôt rare dans le monde si animé du DevOps.
En gros nous avons les grands constituants suivants :
- Un maître ou master, qui est un machine (ou un ensemble de machines) qui contrôle tout le reste ;
- Des noeuds ou nodes ou minions, qui sont des ensembles de ressources disponibles pour les déploiements ;
- Des clusters, qui ne sont rien d’autres que des regroupements de nœuds travaillant pour un master donné ;
- Des pods ou pods, qui sont la plus petite unité gérée (l’unité atomique), qui correspond à la machine virtuelle dans un environnement de virtualisation, ou à un conteneur pour Docker, etc.
- Des services, qui sont une abstraction d’un service mis en oeuvre par des pods.
Le rôle de Kubernetes est de déployer un système (une application) selon les spécifications qu’on lui donne, et de le maintenir dans l’état voulu. Cet état peut être défini grâce au mécanisme Replication Controller, qui se met en place par un simple fichier YAML. On peut par exemple indiquer que l’on souhaite 10 ou 20 instances d’un même pod, et que cet état soit maintenu dans le temps.
En résumé, et en image (source wikipedia) :
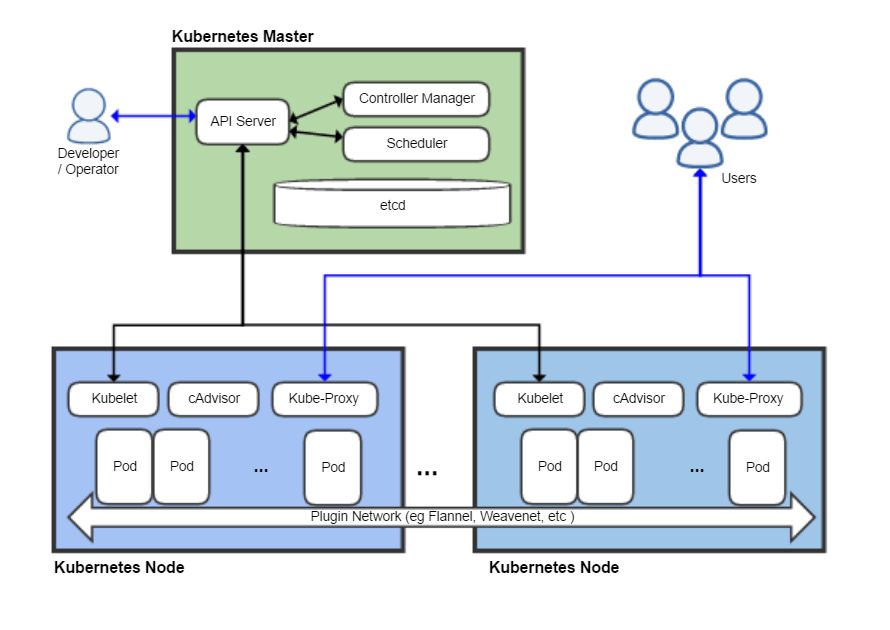
Un composant est très intéressant : etcd, qui est une base de type clé/valeur (noSQL pour ceux qui aiment ré-inventer la roue), et qui sert de base référentielle persistante pour le master.
YAML, le format
L’ensemble du paramétrage d’une application se fait via des fichiers de type manifest, ou bordereau de livraison, au format YAML ou JSON.
Mon pote le pod
Le pod est l’unité la plus intéressante dans Kubernetes, car c’est l’unité qu’on manipule, qu’on construit, et qui sert effectivement à produire le service demandé. Un pod peut contenir plusieurs conteneurs : ainsi un pod peut intégrer tous les services nécessaires à un fonctionnement intègre et autonome, ce qui peut toujours être utile ou plus pratique en termes d’architecture.
Points notables :
- Un pod se crée et se gère via un simple fichier de type manifest, au format YAML.
- Il y a une et une seule adresse IP par pod : pour gérer plusieurs conteneurs (et donc services) au sein d’un pod, il conviendra de le faire via les ports IP.
- Les communications inter-pods sont tout à fait possibles, via le mécanisme du réseau de pods (pods network), qui repose sur le réseau où ils sont déployés.
- De manière générale, toutes les ressources au sein d’un pod sont mutualisées : réseau, mémoire, CPU… Il n’y a aucune isolation au sein d’un pod. Par contre, un pod est totalement isolé des autres pods (toujours du point de vue des ressources).
- Enfin, un pod n’est considéré comme disponible que si l’ensemble des conteneurs devant y être déployés sont effectivement disponibles. Cela renforce la notion d’atomicité du pod.
C’est donc un peu plus conséquent en termes de fonctionnalités qu’un simple conteneur, mais cela reste en dessous du niveau d’une machine virtuelle. D’ailleurs, un pod ne peut pas être scindé, c’est-à-dire déployé par morceaux sur plusieurs noeuds : il est installé sur un et un seul noeud. Et lorsqu’il meurt, on ne relance pas un pod : on en recrée (refabrique) un nouveau, identique, mais qui n’est pas le pod précédent : il n’y a aucune persistance de pod. Le pod est donc un simple mortel, et non un phénix renaissant de ses cendres.
Rendons service
Comme vu ci-dessus, un service est une abstraction d’une fonctionnalité mise en oeuvre par un ensemble de pods. Un service est caractérisé par une adresse IP fixe, un nom, et un port interne et un port exposé (si besoin). Un service peut être de différents types :
- Cluster interne (ClusterIP) ;
- Service exposé à l’extérieur (NodePort) ;
- Équilibreur de charge (LoadBalancer).
Le port interne doit être le même que celui du service mis en oeuvre au niveau du pod (il n’y a pas de translation au niveau du port, mais uniquement au niveau de l’adresse IP).
Ainsi on ne se préoccupe plus du détail de l’instanciation des pods : le service trouve et regroupe les pods réalisant le service (par exemple via des labels qu’on assigne aux pods) et permet d’avoir un point d’entrée unique et stable au service (via une API REST) et même permet un équilibrage de charge.
Le déploiement
C’est le stade ultime dans une architecture Kubernetes : on y gère la mise-à-jour (et le retour arrière), les différents Replicas Sets, de façon à initier l’application ou à la faire monter de version proprement.
Kubernetes sait-il garder un secret ?
Euh… non. Pas bien, en tout cas. En dehors des mécanismes basiques genre TLS qui ne servent qu’au transport, un secret est difficile à protéger au sein d’un déploiement Kubernetes1. Il est possible de gérer des secrets partagés au sein d’un cluster, mais in fine les informations sont stockées en clair2 (ou quasiment, je crois que c’est en base64) dans etcd, qui est l’outil de stockage utilisé par Kubernetes (cf plus haut).
Il ne faut donc pas compter sur le mécanisme par défaut pour une gestion sécurisée des secrets, notamment dans un environnement mutualisé comme le cloud. Dans l’avenir, il sera peut-être possible que ces valeurs secrètes soient stockées correctement chiffrées, mais pour l’instant c’est expérimental3. Les seules solutions fonctionnant en pratique sont d’utiliser les gestionnaires de clés ou les HSM des fournisseurs (AWS, Azure, Google) ou un vault comme celui d’HashiCorp4. Vous ne maîtriserez donc pas totalement vos clés, ce qui peut être un obstacle dans les environnements où la conformité importe.
Installation de MiniKube
Pour apprendre le fonctionnement de Kubernetes, le meilleur moyen sera d’installer MiniKube, un tout-en-un qui tient sur une seule machine mais qui permet d’apprendre les principes. Le support le plus à jour se trouve sur github :
Il y a plusieurs prérequis, dont celui d’avoir installé un outil de virtualisation genre VirtualBox. Il faut aussi avoir installé kubectl.
Linux
Tout en ligne de commande !
Installation de kubectl
$ curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
$ chmod +x ./kubectl
$ sudo mv ./kubectl /usr/local/bin/kubectl
Installation de Minikube
$ curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 && chmod +x minikube && sudo mv minikube /usr/local/bin/
Windows
Il n’y a aussi qu’à recopier les binaires. Pour des questions pratiques, il faut ajouter le chemin d’installation dans le paramètre PATH de Windows, ce qui peut aussi être fait via un installateur pour MiniKube (en version bêta).
Installation de kubectl
$ curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.9.0/bin/windows/amd64/kubectl.exe
Installation de Minikube
Le lien est https://storage.googleapis.com/minikube/releases/latest/minikube-windows-amd64.exe.
Démarrage
$ minikube start
Liens utiles
- https://kubernetes.io/docs/concepts/overview/components/
- https://kubernetes.io/docs/getting-started-guides/minikube/
- https://platform9.com/blog/kubernetes-docker-swarm-compared/
- https://www.stratoscale.com/blog/kubernetes/container-orchestration-kubernetes-12-key-features/